1. Общая информация
HTTP — это протокол, позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно web-браузером (web-browser). Полученный итоговый документ может состоять из различных документов являющихся частью итогового документа: например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.
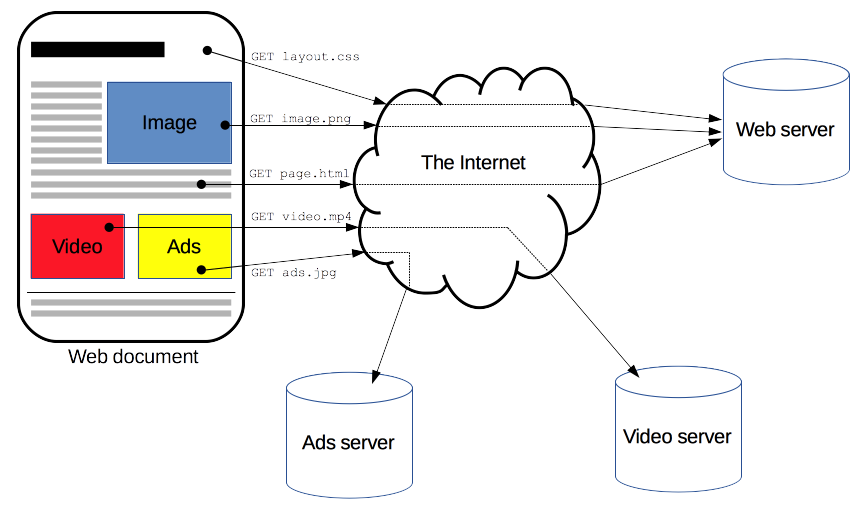
Клиенты и серверы взаимодействуют, обмениваясь одиночными сообщениями, а не потоком данных. Сообщения, отправленные клиентом, обычно web-браузером, называются запросами, а сообщения, отправленные сервером, называются ответами.
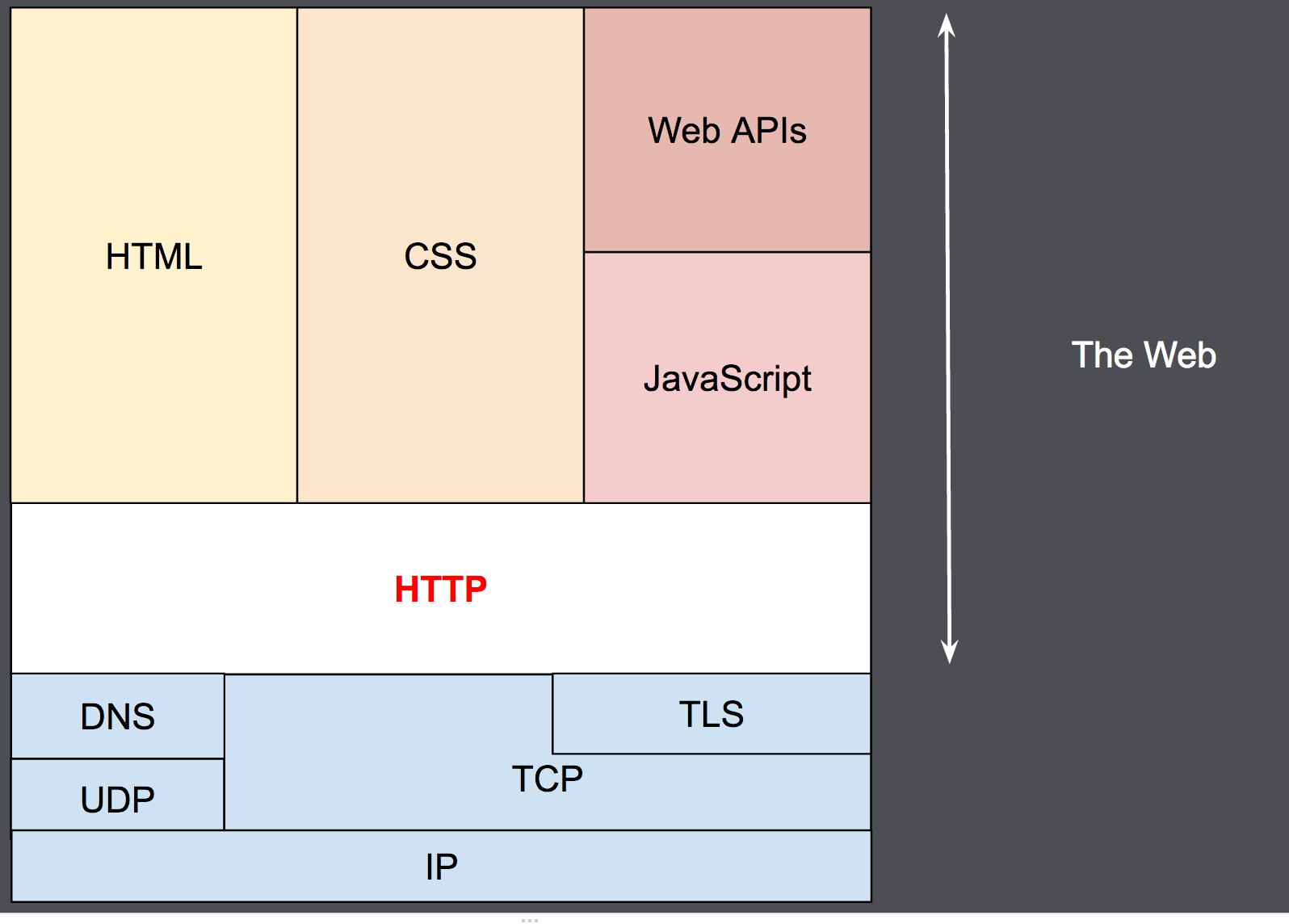
Хотя HTTP был разработан ещё в начале 1990-х годов, за счёт своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола - TCP (или TLS - защищённый TCP) - для пересылки своих сообщений, однако любой другой надёжный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов, изображений и видео, но и для передачи содержимого серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления web-страницы по запросу (например посредством AJAX запроса).
1.1. Составляющие систем, основанных на HTTP
HTTP — это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной — участником обмена (user-agent) (либо прокси вместо него). Чаще всего в качестве участника выступает веб-браузер, но им может быть кто угодно.
Каждый запрос (англ. request) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response). Между этими запросами и ответами, как правило, существуют многочисленные посредники, называемые прокси, которые выполняют различные операции и работают как шлюзы или кеш.

Обычно между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: маршрутизаторы, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники "спрятаны" на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется прикладным (или уровнем приложений). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имеют важное значение для понимания работы сети и диагностики возможных проблем, но не требуются для описания и понимания HTTP.
1.2. Клиент: участник обмена
Участник обмена (user agent) — это любой инструмент или устройство, действующие от лица пользователя. Эту задачу преимущественно выполняет веб-браузер; в некоторых случаях участниками выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая создаёт запрос. Сервер обычно этого не делает, хотя за многие годы существования сети были придуманы способы, которые могут позволить выполнить запросы со стороны сервера.
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер изучает этот документ, и запрашивает дополнительные файлы, необходимые для отображения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы - CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов), которые непосредственно являются частью исходного документа, но расположены в других местах сети. Далее браузер соединяет все эти ресурсы для отображения их пользователю в виде единого документа — веб-страницы. Скрипты, выполняемые самим браузером, могут получать по сети дополнительные ресурсы на последующих этапах обработки веб-страницы, и браузер соответствующим образом обновляет отображение этой страницы для пользователя.
Веб-страница является гипертекстовым документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы (переход по ссылке). Это позволяет пользователю "перемещаться" по страницам сети (Internet). Браузер преобразует эти гиперссылки в HTTP-запросы и в дальнейшем полученные HTTP-ответы отображает в понятном для пользователя виде.
1.3. Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кеширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).
Сервер необязательно расположен на одной машине, и наоборот - несколько серверов могут быть расположены (поститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея Host заголовок, они даже могут делить тот же самый IP-адрес.
1.4. Основные аспекты HTTP
1.4.1. HTTP - прост
Даже с большей сложностью, введённой в HTTP/2 путём инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более лёгкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
1.4.2. HTTP - расширяемый
Введённые в HTTP/1.0 HTTP-заголовки сделали этот протокол лёгким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
1.4.3. HTTP не привязан к конкретному типу данных
Начиная с версии HTTP/1.0 заголовки запросов и ответов были закодированы в ASCII (HTTP/0.9 весь был закодирован в ASCII), а вот тело ответа могло быть любого контентного типа — изображением, видео, HTML, обычным текстом и т.п., но при условии, что и клиент и сервер “умеют” работать с данным типом данных. Теперь сервер мог послать любой тип контента клиенту, поэтому словосочетание Hyper Text в аббревиатуре HTTP стало искажением. HMTP, или Hypermedia Transfer Protocol, пожалуй, стало бы более уместным названием, но все к тому времени уже привыкли к HTTP.
1.4.4. HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом, или состоянием.
1.4.5. HTTP и соединения
Соединение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортного протокол был основан на соединениях, требуя только надёжность, или отсутствие потерянных сообщений (т.е. как минимум представление ошибки). Среди двух наиболее распространённых транспортных протоколов Интернета, TCP надёжен, а UDP - нет. HTTP впоследствии полагается на стандарт TCP, являющийся основанным на соединениях, несмотря на то, что соединение не всегда требуется.
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений: тёплые соединения более эффективны, чем холодные.
Для смягчения этих недостатков, HTTP/1.1 предоставил конвейерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок Connection. HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение тёплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google экспериментирует с QUIC, которая основана на UDP, для предоставления более надёжного и эффективного транспортного протокола.
1.5. Чем можно управлять через HTTP
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кеш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с (HTTP).
-
Кеш
Сервер может инструктировать прокси и клиенты: что и как долго кешировать. Клиент может инструктировать прокси промежуточных кешей игнорировать хранимые документы. -
Ослабление ограничений источника
Для предотвращения шпионских и других, нарушающих приватность, вторжений, web-браузер обеспечивает строгое разделение между web-сайтами. Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). -
Аутентификация
Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовкаWWW-Authenticate (en-US)и подобных ему, либо с помощью настройки специальной сессии, используя куки. -
Прокси и туннелирование
Серверы и/или клиенты часто располагаются в интернете, и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси - HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, FTP, могут быть обработаны этими прокси. -
Сессии
Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создаёт сессию, хотя ядро HTTP - протокол без состояния.
1.6. HTTP поток
Когда клиент хочет взаимодействовать с сервером, являясь конечным сервером или промежуточным прокси, он выполняет следующие шаги:
-
Открытие TCP соединения: TCP-соединение будет использоваться для отправки запроса или запросов, и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее, или открыть несколько TCP-соединений к серверу.
-
Отправка HTTP-сообщения: HTTP-сообщения (до HTTP/2) - человеко-читаемо. Начиная с HTTP/2, простые сообщения инкапсулируются во фреймы, делая невозможным их чтения напрямую, но принципиально остаются такими же.
-
Читает ответ от сервера
-
Закрывает или переиспользует соединение для дальнейших запросов.
Если активирован HTTP-конвейер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвейер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвейер был заменён в HTTP/2 на более надёжные мультиплексные запросы во фрейме.
1.7. HTTP сообщения
HTTP/1.1 и более ранние HTTP сообщения человеко-читаемы. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос. Это также полезно для понимания HTTP/2 сообщений в формате HTTP/1.1.
Существует два типа HTTP сообщений:
-
запросы
-
ответы
1.7.1. HTTP Запросы
Примеры HTTP запросов:
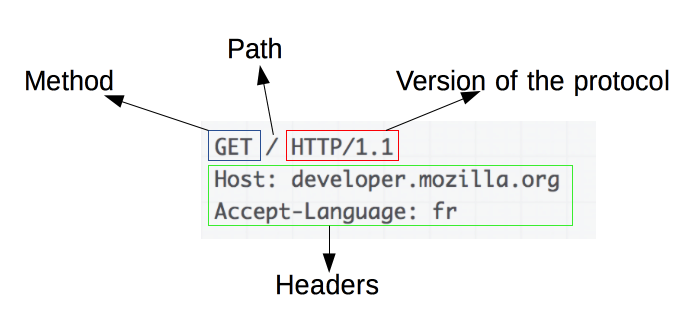
Запросы содержат следующие элементы:
-
HTTP-метод, обычно глагол подобно
GET,POSTили существительное, какOPTIONSилиHEAD, определяющее операцию, которую клиент хочет выполнить. Обычно, клиент хочет получить ресурс (используяGET) или передать значения HTML-формы (используяPOST), хотя другие операция могут быть необходимы в других случаях. -
Путь к ресурсу: URL ресурсы лишены элементов, которые очевидны из контекста, например без protocol (
http://), domain (здесьdeveloper.mozilla.org), или TCP port (здесь80). Фактически веб отошел от понимания URL как пути к файлу и стал рассматривать его как запрос. -
Версию HTTP-протокола.
-
Заголовки - (опционально), предоставляющие дополнительную информацию для сервера.
-
Тело, для некоторых методов, таких как
POST, которое содержит отправленный ресурс.
1.7.2. HTTP Ответы
Примеры ответов:
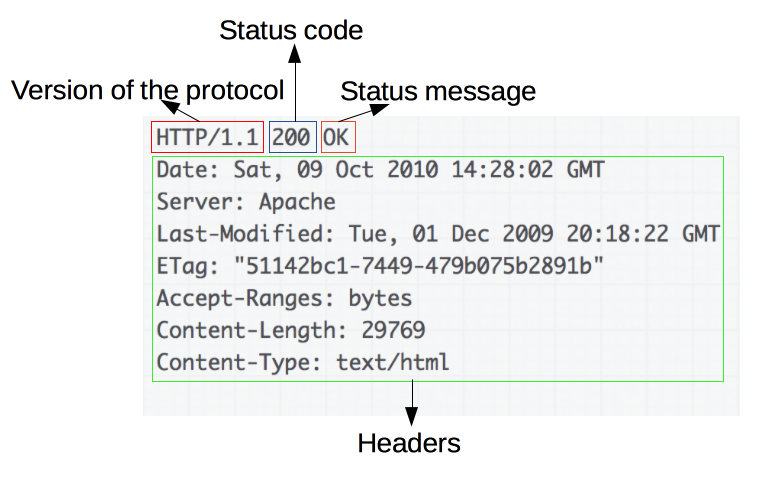
Ответы содержат следующие элементы:
-
Версию HTTP-протокола.
-
HTTP код состояния, сообщающий об успешности запроса или причине неудачи.
-
Сообщение состояния - краткое описание кода состояния.
-
HTTP заголовки, подобно заголовкам в запросах.
-
Опционально: тело, содержащее пересылаемый ресурс.
2. HTTP методы
HTTP метод (HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами. Названия метода чувствительны к регистру.
Каждый сервер обязан поддерживать как минимум методы GET и HEAD. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Наиболее востребованными являются методы GET и POST — на человеко-ориентированных ресурсах, POST — роботами поисковых машин и оффлайн-браузерами.
2.1. OPTIONS
-
Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Предполагается, что запрос клиента может содержать тело сообщения для указания интересующих его сведений. Формат тела и порядок работы с ним в настоящий момент не определён. Сервер пока должен его игнорировать.
-
Аналогичная ситуация и с телом в ответе сервера.
-
Для того чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку —
*. ЗапросыOPTIONS * HTTP/1.1могут также применяться для проверки работоспособности сервера (аналогично использованию командыping) и тестирования на предмет поддержки сервером протокола HTTP версии 1.1. -
Результат выполнения этого метода не кэшируется.
2.2. GET
-
Используется для запроса содержимого указанного ресурса. С помощью метода
GETможно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Клиент может передавать параметры выполнения запроса в URI целевого ресурса после символа?:GET /path/resource?param1=value1&m2=value2 HTTP/1.1 -
Согласно стандарту HTTP, запросы типа
GETсчитаются идемпотентными — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET. -
Кроме обычного метода
GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовкиIf-Modified-Since,If-Match,If-Rangeи т.п. Частичные GET содержат в запросеRange. Порядок выполнения подобных запросов определён стандартами отдельно.
2.3. HEAD
-
Аналогичен методу
GET, за исключением того, что в ответе сервера отсутствует тело. ЗапросHEADобычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и, чтобы узнать, не изменился ли он с момента последнего обращения. -
Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая.
2.4. POST
-
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом
POSTи он помещает их на страницу. При этом передаваемые данные включаются в тело запроса. Аналогично с помощью методаPOSTобычно загружаются файлы. -
В отличие от метода
GET, методPOSTне считается идемпотентным, то есть многократное повторение одних и тех же запросовPOSTможет возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария). -
При результатах выполнения
200 (Ok)и204 (No Content)в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ201 (Created)с указанием URI нового ресурса в заголовкеLocation. -
Сообщение ответа сервера на выполнение метода
POSTне кэшируется.
2.5. PUT
-
Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по-заданному URI не существовало ресурса, то сервер создаёт его и возвращает статус
201 (Created). Если же был изменён ресурс, то сервер возвращает200 (Ok)или204 (No Content). Сервер не должен игнорировать некорректные заголовкиContent-*передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или не допустим при текущих условиях, то необходимо вернуть код ошибки501 (Not Implemented). -
Фундаментальное различие методов
POSTиPUTзаключается в понимании предназначений URI ресурсов. МетодPOSTпредполагает, что по-указанному URI будет производиться обработка передаваемого клиентом содержимого. ИспользуяPUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу. -
Сообщения ответов сервера на метод
PUTне кэшируются.
2.6. PATCH
Аналогично PUT, но применяется только к фрагменту ресурса.
2.7. DELETE
Удаляет указанный ресурс.
2.8. TRACE
Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе.
2.9. LINK
Устанавливает связь указанного ресурса с другими.
2.10. UNLINK
Убирает связь указанного ресурса с другими.
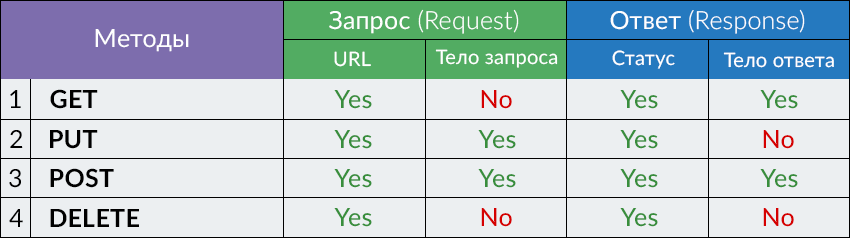
2.11. Часто используемые HTTP-methods и HTTP-body
3. Proxy-сервер
Proxy-сервер — это транзитный сервер, перенаправляющий HTTP-трафик. Proxy-серверы используются для ускорения выполнения запросов путем кэширования веб-страниц. В локальной сети применяется как межсетевой экран и средство управления HTTP-трафиком (например, для блокирования доступа к некоторым ресурсам).
В Интернете Proxy часто используют для анонимизации запросов - в этом случае веб-сервер получает ip-адрес прокси-сервера, а не реального клиента. В современных браузерах можно задать целый список прокси-серверов и переключаться между ними по мере необходимости (обычно такая возможность доступна через расширения или плагины браузера).
4. Коды ответа
Код ответа информирует клиента о результатах выполнения запроса и определяет его дальнейшее поведение. Набор кодов состояния является стандартом, и все они описаны в соответствующих документах RFC.
Каждый код представляется целым трехзначным числом. Первая цифра указывает на класс состояния, последующие — порядковый номер состояния. За кодом ответа обычно следует краткое описание на английском языке.
Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
Применяемые в настоящее время классы кодов состояния и некоторые примеры ответов сервера приведены ниже:
4.1. 1xx Informational (Информационный)
В этот класс выделены коды, информирующие о процессе передачи. В HTTP/1.0 сообщения с такими кодами должны игнорироваться. В HTTP/1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-сервера подобные сообщения должны отправлять дальше от сервера к клиенту.
Примеры ответов сервера:
-
100 Continue(Продолжать) -
101 Switching Protocols(Переключение протоколов) -
102 Processing(Идёт обработка)
4.2. 2xx Success (Успешно)
Сообщения данного класса информируют о случаях успешного принятия и обработки запроса клиента. В зависимости от статуса сервер может ещё передать заголовки и тело сообщения.
Примеры ответов сервера:
-
200 OK(Успешно). -
201 Created(Создано) -
202 Accepted(Принято) -
204 No Content(Нет содержимого) -
206 Partial Content(Частичное содержимое)
4.3. 3xx Redirection (Перенаправление)
Коды статуса класса 3xx сообщают клиенту, что для успешного выполнения операции нужно произвести следующий запрос к другому URI. В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход, т.е. redirect (перенаправление).
Обратите внимание, что при обращении к следующему ресурсу можно получить ответ из этого же класса кодов. Может получиться даже длинная цепочка из перенаправлений, которые, если будут производиться автоматически, создадут чрезмерную нагрузку на оборудование. Поэтому разработчики протокола HTTP настоятельно рекомендуют после второго подряд подобного ответа обязательно запрашивать подтверждение на перенаправление у пользователя (раньше рекомендовалось после 5-го). За этим следить обязан клиент, так как текущий сервер может перенаправить клиента на ресурс другого сервера. Клиент также должен предотвратить попадание в круговые перенаправления.
Примеры ответов сервера:
-
300 Multiple Choices(Множественный выбор) -
301 Moved Permanently(Перемещено навсегда) -
304 Not Modified(Не изменялось)
4.4. 4xx Client Error (Ошибка клиента)
Класс кодов 4xx предназначен для указания ошибок со стороны клиента. При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.
Примеры ответов сервера:
-
401 Unauthorized(Не авторизован) -
402 Payment Required(Требуется оплата) -
403 Forbidden(Запрещено) -
404 Not Found(Не найдено) -
405 Method Not Allowed(Метод не поддерживается) -
406 Not Acceptable(Не приемлемо) -
407 Proxy Authentication Required(Требуется аутентификация прокси)
4.5. 5xx Server Error (Ошибка сервера)
Коды 5xx выделены под случаи неудачного выполнения операции по вине сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю.
Примеры ответов сервера:
-
500 Internal Server Error(Внутренняя ошибка сервера) -
502 Bad Gateway(Плохой шлюз) -
503 Service Unavailable(Сервис недоступен) -
504 Gateway Timeout(Шлюз не отвечает)
5. HTTP заголовки
HTTP заголовок (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения, если иное не предусмотрено форматом поля.
Пример заголовков ответа сервера:
Server: Apache/2.2.3 (CentOS)
Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT
Content-Type: text/html; charset=UTF-8
Accept-Ranges: bytes
Date: Thu, 03 Mar 2011 04:04:36 GMT
Content-Length: 2945
Age: 51
X-Cache: HIT from proxy.omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
200 OKВсе HTTP-заголовки разделяются на четыре основных группы:
-
General Headers (Основные заголовки) — должны включаться в любое сообщение клиента и сервера.
-
Request Headers (Заголовки запроса) — используются только в запросах клиента.
-
Response Headers (Заголовки ответа) — присутствуют только в ответах сервера.
-
Entity Headers (Заголовки сущности) — сопровождают каждую сущность сообщения.
Сущности (entity, в переводах также встречается название "объект") — это полезная информация, передаваемая в запросе или ответе. Сущность состоит из метаинформации (заголовки) и непосредственно содержания (тело сообщения).
В отдельный класс заголовки сущности выделены, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (multipart/*).
Заголовки запроса и ответа, как и основные заголовки, описывают всё сообщение в целом и размещаются только в начальном блоке заголовков, в то время как заголовки сущности характеризуют содержимое каждой части в отдельности, располагаясь непосредственно перед её телом.
Ниже в таблице приведено краткое описание некоторых HTTP-заголовков.
Заголовок |
Группа |
Краткое описание |
|
Entity |
Список методов, применимых к запрашиваемому ресурсу. |
|
Entity |
Применяется при необходимости перекодировки содержимого (например, |
|
Entity |
Локализация содержимого (язык(и)) |
|
Entity |
Размер тела сообщения (в октетах) |
|
Entity |
Диапазон (используется для поддержания многопоточной загрузки или дозагрузки) |
|
Entity |
Указывает тип содержимого ( |
|
Entity |
Дата/время, после которой ресурс считается устаревшим. Используется прокси-серверами |
|
Entity |
Дата/время последней модификации сущности |
|
General |
Определяет директивы управления механизмами кэширования. Для прокси-серверов. |
|
General |
Задает параметры, требуемые для конкретного соединения. |
|
General |
Дата и время формирования сообщения |
|
General |
Используется для специальных указаний, которые могут (опционально) применяется к любому получателю по всей цепочке запросов/ответов (например, pragma: |
|
General |
Задает тип преобразования, применимого к телу сообщения. В отличие от |
|
General |
Используется шлюзами и прокси для отображения промежуточных протоколов и узлов между клиентом и веб-сервером. |
|
General |
Дополнительная информация о текущем статусе, которая не может быть представлена в сообщении. |
|
Request |
Определяет применимые типы данных, ожидаемых в ответе. |
|
Request |
Определяет кодировку символов (charset) для данных, ожидаемых в ответе. |
|
Request |
Определяет применимые форматы кодирования/декодирования содержимого (напр, |
|
Request |
Применимые языки. Используется для согласования передачи. |
|
Request |
Учетные данные клиента, запрашивающего ресурс. |
|
Request |
Электронный адрес отправителя |
|
Request |
Имя/сетевой адрес [и порт] сервера. Если порт не указан, используется |
|
Request |
Используется для выполнения условных методов (Если-Изменился…). Если запрашиваемый ресурс изменился, то он передается с сервера, иначе — из кэша. |
|
Request |
Представляет механизм ограничения количества шлюзов и прокси при использовании методов |
|
Request |
Используется при запросах, проходящих через прокси, требующие авторизации |
|
Request |
Адрес, с которого выполняется запрос. Этот заголовок отсутствует, если переход выполняется из адресной строки или, например, по ссылке из js-скрипта. |
|
Request |
Информация о пользовательском агенте (клиенте) |
|
Response |
Адрес перенаправления |
|
Response |
Сообщение о статусе с кодом 407. |
|
Response |
Информация о программном обеспечении сервера, отвечающего на запрос (это может быть как веб, так и прокси-сервер). |
6. Тело HTTP сообщения
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности (entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Заголовок Transfer-Encoding должен отправляться для указания любого кодирования передачи, примененного приложением в целях гарантирования безопасной и правильной передачи сообщения. Transfer-Encoding - это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
7. Cookies
HTTP cookie (web cookie, cookie браузера) — это небольшой фрагмент данных, отправляемый сервером на браузер пользователя, который тот может сохранить и отсылать обратно с новым запросом к данному серверу. Это, в частности, позволяет узнать, с одного ли браузера пришли оба запроса (например, для аутентификации пользователя). Они запоминают информацию о состоянии для протокола HTTP, который сам по себе этого делать не умеет.
Cookie используются, главным образом, для:
-
Управления сеансом (логины, корзины для виртуальных покупок)
-
Персонализации (пользовательские предпочтения)
-
Мониторинга (отслеживания поведения пользователя)
До недавнего времени cookie принято было использовать в качестве хранилища информации на стороне пользователя. Это могло иметь смысл в отсутствии вариантов, но теперь, когда в распоряжении браузеров появились различные API (программные интерфейсы приложения) для хранения данных, это уже не так. Из-за того, что cookie пересылаются с каждым запросом, они могут слишком сильно снижать производительность (особенно в мобильных устройствах). В качестве хранилищ данных на стороне пользователя вместо них можно использовать Web storage API (localStorage and sessionStorage) и IndexedDB.
7.1. Создание Cookie
Получив HTTP-запрос, вместе с откликом сервер может отправить заголовок Set-Cookie с ответом. Cookie обычно запоминаются браузером и посылаются в значении заголовка HTTP Cookie (en-US) с каждым новым запросом к одному и тому же серверу. Можно задать срок действия cookie, а также срок его жизни, после которого cookie не будет отправляться. Также можно указать ограничения на путь и домен, то есть указать, в течении какого времени и к какому сайту оно отсылается.
Заголовок Set-Cookie HTTP-отклика используется для отправки cookie с сервера на клиентское приложение (браузер). Простой cookie может задаваться так:
Set-Cookie: <имя-cookie>=<заголовок-cookie>Этот заголовок с сервера даёт клиенту указание сохранить cookie. Отклик, отправляемый браузеру, содержит заголовок Set-Cookie, и cookie запоминается браузером.
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]Теперь, с каждым новым запросом к серверу, при помощи заголовка Cookie (en-US) браузер будет возвращать серверу все сохранённые ранее cookies.
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberryПростой cookie, пример которого приведён выше, представляет собой сессионный cookie (session cookie) - такие cookie удаляются при закрытии клиента, то есть существуют только на протяжении текущего сеанса, поскольку атрибуты Expires или Max-Age для него не задаются. Однако, если в браузере включено автоматическое восстановление сеанса, что случается очень часто, cookie сеанса может храниться постоянно, как если бы браузер никогда не закрывался.
Постоянные cookie (permanent cookies) удаляются не с закрытием клиента, а при наступлении определённой даты (атрибут Expires) или после определённого интервала времени (атрибут Max-Age).
8. cURL как HTTP-client
Для того что бы делать запросы на какой-то сервис нужен HTTP-client. В качестве HTTP-client удобно использовать cURL. cURL — кроссплатформенная служебная программа командной строки, позволяющая взаимодействовать с множеством различных серверов по множеству различных протоколов с синтаксисом URL.
Для описания взаимодействия по HTTP рекомендуется использовать именно cURL, так как:
-
нет зависимости от GUI, т.е. легко запускать на OS у которых отсутствует GUI
-
не требует дополнительных манипуляций со стороны пользователя, в отличии, например, от Postman, telnet
Примеры использования cURL:
curl -X GET https://www.yourwebsite.com/users/1
curl -X POST https://www.yourwebsite.com/users/ -d 'username=yourusername&password=yourpassword'
curl -X PUT https://www.yourwebsite.com/users/1 -d 'username=yourusername&password=yourpassword&age=25'
curl -X DELETE https://www.yourwebsite.com/users/1