1. Введение в Web
В конце 80-х — начале 90-х годов XX-го столетия практически все системы строились по принципу client-server. На компьютере работника было установлено графическое (или текстовое) приложение, которое обращалось к database с запросами на изменение или получение данных.
Таким образом было две стороны:
-
client который имел какую-то логику и давал возможность пользователю что-то делать с данными
-
server обычно СУБД типа SQL, на котором выполнялись запросы на получение данных и их изменение
За счет возможности писать сохраненные процедуры (Stored Procedure) с помощью расширения для SQL. Это расширение описывается ISO standard SQL/PSM. Большинство СУБД на 100% реализуют этот стандарт, но некоторые СУБД имеют свои собственные Procedural Language:
-
PL/SQL: Oracle, DB2 (since version 9.7)
-
Transact-SQL: Sybase (SAP), Microsoft
-
PL/pgSQL: PostgreSQL
-
SQL PL: DB2
Такого рода процедуры позволяли писать достаточно сложную логику обработки данных, не перекладывая эту работу на client. Поэтому когда изменялась логика, то изменения необходимо было произвести ТОЛЬКО на server не затрагивая при этом client application.
Такое взаимодействие замечательно работало до тех пор, пока не появилась ПОТРЕБНОСТЬ.
Системы client-server требовали сотрудника. Если клиент хочет сделать заказ — он должен связаться с сотрудником, который занесет его заказ в database с помощью своего client application.
Достаточно прямолинейное решение — дать клиентам приложение (пусть и ограниченное) было бы слишком опрометчивым, потому что:
-
необходимо разработать
-
необходимо менять под потребности клиентов
-
необходимо обновлять каждый раз у клиентов
-
система все чаще становилась зависимой не от одной базы данных, а от многих источников информации
-
клиентское приложение ходит в базу данных. Центральное хранилище “открывать” наружу — это уже не БЕЗОПАСНО.
Поэтму появились три задачи, которые стали определяющими для дальнейшего развития:
-
безопасность
-
клиентское приложение с возможностью обновления для сотен тысяч пользователей
-
возможность принимать запросы от универсального клиента и писать логику для распределенных источников информации
1.1. Безопасность
Вполне логичным решением было введение промежуточного звена, которое принимало запросы от клиентов, проверяло бы их и транслировало бы дальше внутрь корпоративной сети. Таким образом все хранилища будут закрыты извне. Будет только один шлюз/вход, через который будут проходить все запросы. Такой вход гораздо легче контролировать.
1.2. Универсальный клиент
Самое очевидное решение — нужна программа, которая в runtime исполняет код, который в нее загружается. И этим универсальным client стал browser.
Со временем браузеры совершенствовались, язык отображения HTML (Hyper Text Markup Language — язык разметки гипертекста), становился более сложным и изощренным. Появились JavaScript, который мог исполнять браузер и таким образом сделать страницы более интерактивными. Начиная с версии HTML 4.0 появились CSS (Cascade Style Sheets — каскадные таблицы стилей). Потом появилась и прижилась технология AJAX (Asynchronous JavaScript And XML).
Browser может загрузить данные, отобразить их, позволить что-то ввести в текстовые поля и отправить данные на server.
1.3. Сервер приложений
Он-то и должен предоставить “возможность принимать запросы от универсального клиента и писать логику для распределенных источников информации”.
В простом варианте это была обычная программа, которая ждала запросы от внешних программ. Причем в ранних версиях у такого сервера не было даже многопоточности — она просто порождала свою копию в виде отдельного процесса и передавала туда обработку запроса.
Также программа предоставляла возможность писать другие программы, которые могли быть ею запущены для исполнения запросов.
В итоге схема для решения ПОТРЕБНОСТИ выглядит следующим образом:
-
browser, как универсальный клиент, который, по определенному протоколу обратиться к application server (т.е. к программе, которая умеет запускать другие программы)
-
application server в свою очередь запустит на выполнение program, которая написана по определенным правилам
-
program обработает запрос, что-то поменяет, что-то считает и отдаст результат (какие-то данные) в browser
-
browser это отобразит
В итоге пришли к выводам:
-
нам нужен browser
-
нам нужна program для приема сетевых запросов, которая должна предоставлять возможности интегрировать в него другие programs, которые будут решать специализированные задачи
1.4. Browser как client
Browser - это прикладное программное обеспечение для просмотра страниц, содержания веб-документов, компьютерных файлов и их каталогов; управления веб-приложениями; а также для решения других задач. Браузеров, на данный момент, очень много, например:
-
Mozilla Firefox
-
Google Chrome
-
Internet Explorer
-
Opera
-
Apple Safari
-
Амиго
1.5. Application server как server
Программа, которая работает с сетевыми запросами может быть как простой, так и сложной, с большим количеством возможностей, которые необходимо изучать. Эту программу и называют application server. Так как application server — это программа, то ее надо запускать, как обычную программу на компьютере. Эта программа предоставляет широко используемые сервисы. Уже заранее готовые и настроенные. Если говорить о Java, то упрощенно, это уже готовый набор объектов или классов, которые можно использовать. Эти объекты создает application server по настройкам и любая программа, которая установлена на application server, может их использовать.
1.6. Взаимодействие client и server
Client и server (как и любым двум программам) необходимо научиться разговаривать друг с другом. Server должен понимать request от client, а client должен понимать response от server. Всё это и называется protocol. Если рассматривать это на низном уровне, то это набор слов (байтов), которые можно использовать для общения.
2. Версии Web
Поскольку дискуссия вокруг Web 3.0 набирает обороты в текущем веб-сценарии, большинство людей часто не понимают, что такое Web 3.0 и чем он отличается от предыдущих версий web.
Интернет, часто называемый синонимом web, претерпел огромное количество изменений с тех пор: как он был представлен еще в 1980 году. В период с 1980 по 2005 год была разработана концепция и эволюционировала сеть, доступная только для чтения, или Web 1.0. На его основе примерно в 1999 году появились социальные сети и сотрудничество между создателями и пользователями, что привлекло к появлению Web 2.0 или Интернета, каким мы его видим сегодня.
С 2006 года мы наблюдаем, как новые технологии доминируют в веб-мире, порождая новый и несколько расплывчатый Web 3.0, который рекламируется как будущее Интернета.
В этой статье мы проанализируем сильные и слабые стороны каждого типа Интернета и их сравнение друг с другом. Таким образом, мы создаем лучшее представление о том, что представляет собой Web 3.0.
2.1. Web 1.0
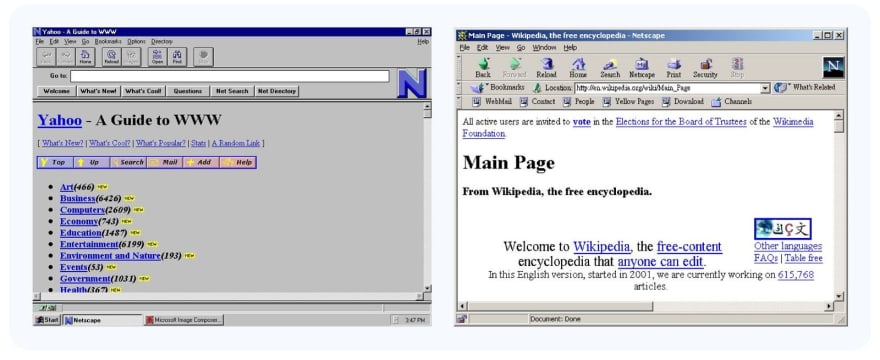
Говоря простым языком непрофессионала, Web 1.0- это все, что нужно для чтения и поиска информации. Web 1.0- это самая ранняя форма Интернета, созданная Тимом Бернерсом Ли в 1989 году.
Тим разработал концепцию простого проекта, которая позволяет одной странице в каталоге ссылаться на другие страницы в той же системе с помощью гиперссылок. Идея не только набрала обороты, но и породила огромный поток новых браузеров, протоколов и технологий, которые положили начало эре обмена информацией.
Web 1.0 - это поколение Интернета, существовавшее в период с 1991 по 2005 год. Это эпоха, когда создателей контента было меньше, а вместо этого подавляющее большинство были потребителями данных. Пользователям было разрешено просматривать контент, размещенный на веб-сайтах, но они не могли сотрудничать, оставлять отзывы или добавлять свой собственный контент на эти веб-сайты. Web 1.0 использовал статический HTML и отображал контент с помощью таблиц и фреймов. Веб-сайты были в основном статичными, а данные хранились преимущественно в файловых системах.
Web 1.0 можно рассматривать как огромную цифровую энциклопедию, которой не хватало интерактивности. Хотя у него, безусловно, были свои сильные стороны, у него также были некоторые недостатки, которые привели к эволюции Web 2.0.
Сильные стороны Web 1.0:
-
Web 1.0 положил начало Всемирной паутине (WWW), и веб, каким мы его видим сегодня, был построен поверх нее.
-
Web 1.0 предоставлял единый доступ, поэтому никто, кроме создателя, не смог бы добавлять контент. Следовательно, Web 1.0 не разрешал загружать вредоносный контент без разрешения создателя.
Слабые стороны Web 1.0:
-
Web 1.0 был линейной технологией, которая допускала только одностороннюю связь от создателя к пользователю.
-
Web 1.0 был просто информационным порталом без какой-либо интерактивности и участия пользователей.
2.2. Web 2.0
Web 2.0 появился из-за недостатка Web 1.0, который допускал ограниченное общение между создателями контента и пользователями. Web 2.0 также известен как веб для чтения и записи или социальная сеть. Это произошло с появлением сайтов социальных сетей, таких как Twitter, Facebook и Instagram, но выросло, чтобы предоставить пользователям гораздо более богатый пользовательский опыт. Интернет, как мы видим сейчас, находится в фазе Web 2.0 и медленно переходит к Web 3.0.
Веб-сайты в Web 2.0 позволяют пользователям предоставлять обратную связь производителям контента, а также создавать свой собственный контент. Пользователи не только предоставляют данные и обратную связь, но и могут контролировать данные, которые они видят на веб-сайтах Web 2.0. Web 2.0 - это также эпоха, когда появились решения Software as a Service (SaaS) и использовались такие технологии, как HTML 5, CSS 3 и фреймворки JavaScript.
Вместо статичных веб-сайтов, которые просто размещали контент, Web 2.0 ввел концепцию ведения блогов, а также масштабирования, прокрутки и манипулирования контентом, например, в Google Maps. В начале 2000-х годов Web 2.0 стал еще более популярным, что изменило внешний вид Интернета.
Хотя Web 2.0 действительно имел свои преимущества по сравнению с Web 1.0, он все еще страдает от некоторых недостатков.
Сильные стороны Web 2.0:
-
Бесплатный поиск и сортировка информации.
-
Использование разработанных API, которые могут быть использованы самими пользователями.
-
Динамический контент.
-
Более широкое использование контента в социальных сетях, который позволяет людям участвовать в обсуждениях, делиться данными с друзьями и семьей и оставаться на связи с людьми по всему миру.
-
Простота обмена информацией.
-
Огромное разнообразие информации в один клик.
Слабые стороны Web 2.0:
-
Риск вирусных атак, мошенничества и спама.
-
Риск получения неверной информации, поскольку разнообразие, достоверность и объем информации слишком велики.
-
Нарушена безопасность, поскольку пользователи Web 2.0 находятся во власти крупных технологических компаний (Alphabet (Google), Amazon, Meta (Facebook), Apple и Microsoft), которые хранят почти все их данные.
-
Цензура информации крупными технологическими компаниями, имеющие возможность подвергать цензуре информацию, к которой пользователи пытаются получить доступ.
-
Экономические выгоды ограничены только крупными технологическими компаниями, даже несмотря на то, что контент, размещаемый на Web, генерируется в основном пользователями.
-
Централизованная финансовая система, при которой финансовая система централизованно управляется.
2.3. Web 3.0

Зависимость Web 2.0 от крупных технологических компаний неприемлема для обычных пользователей и, таким образом, революционизирует то, как люди используют Интернет. Это дает начало новой эре Web под названием Web 3.0. Web 3.0 также известен как сеть чтения-записи-выполнения и вводит концепцию машинного обучения, искусственного интеллекта и блокчейн-систем.
Web 3.0 вводит концепцию децентрализации во все, что он делает. Это концепция, которая предполагает, что контент и данные должны принадлежать децентрализованным автономным органам и контролироваться ими, тем самым уменьшая цензуру и централизованный контроль, осуществляемый крупными технологическими компаниями. Платежи в Web 3.0 используют аутентификацию на основе токенов, поэтому нет необходимости передавать персональные данные сторонним посредникам. Как только смарт-контракты развернуты, они выполняются так, как написано, без необходимости в посреднике.
Криптовалюты и токены - это не только трансформация финансов и денег, но и способы, с помощью которых создатели могут создавать интернет-организации для создания ценности и обмена ею.
Столпами Web 3.0 являются:
-
Искусственный интеллект и машинное обучение
Web 3.0 основан на обработке естественного языка (NLP), которая позволяет Сети анализировать и извлекать значение произносимых и написанных слов. Проверка орфографии, фильтрация спама и автозаполнение основаны на NLP. -
Децентрализация и блокчейн
Технология блокчейн, проще говоря, представляет собой цепочку блоков, где каждый блок содержит незаменимый криптографический хэш, временную метку и данные транзакции предыдущего блока. Использование этой технологии в децентрализованных организациях, работающих по одноранговым протоколам (P2P), является характерной чертой Web 3.0. -
Вездесущность
Web 3.0 предполагает, что системы доступны везде и всюду благодаря использованию децентрализованных серверов, что снижает зависимость от больших технологий, которая существует в Web 2.0. -
3D-графика и пространственная сеть
Web 3.0 также настроен на переход от 2D к 3D системам в сочетании с NLP и машинным обучением (ML). Web 3.0 увидит слияние реальности с виртуальными мирами с использованием датчиков, умных очков и технологий AR/VR.
Слабые стороны Web 3.0:
-
Поскольку Web 3.0 - это технология будущего, не все гаджеты смогут с ней работать.
-
Новичкам может быть трудно это понять.
-
Поскольку безопасность и владение децентрализованы, это может потребовать значительных изменений в законодательстве.
-
Регулирование Web 3.0 будет более сложным в отсутствие крупных технологических компаний или центральных структур.
-
Поскольку Web 3.0 - это нейронная сеть, доступ к личным и политическим данным становится проще.
2.4. Сравнение характеристик
| Web 1.0 | Web 2.0 | Web 3.0 | |
|---|---|---|---|
Возможности |
Веб-сайт только для чтения |
Чтение, запись и социальная сеть |
Чтение, запись, собственность |
Временная шкала |
С 1989 по 2005 |
С 2005 года по настоящее время |
Предстоящий |
Содержание |
Контент принадлежит только создателю |
Контентом делятся создатели и пользователи |
Контент консолидирован создателями и пользователями |
Сосредоточенность |
Больше внимания уделяется компаниям |
Больше внимания уделяется сообществу |
Больше внимания уделяется отдельному человеку |
Прибыль |
Заработок за счет просмотров страниц |
Заработок с помощью одного клика |
Заработок получается за счет вовлечения пользователей |
Рекламирование |
Реклама основана на баннере |
Реклама интерактивная |
Реклама является поведенческой |
Данные пользователя |
Данные пользователя не были сфокусированы |
Пользовательские данные контролируются центральными органами власти |
Пользовательские данные персонализированы и децентрализованы без использования центральной власти |
Использование |
В основном визуальный, статичный веб без связи между пользователем и сервером |
В.основном программируемая сеть с улучшенным пользовательским взаимодействием |
Связанная сеть данных с интеллектом, веб-основанные на функциях и приложениях |
Применение |
Появляются домашние страницы и веб-формы |
Возможность использовать блоги, вики и веб-приложения |
Появляются Livestreams, waves и smart-applications Сравнение технологий, сервисов и приложений |
| Web 1.0 | Web 2.0 | Web 3.0 | |
|---|---|---|---|
Технологии |
HTML/HTTP/URL/Portals |
XML/RSS |
RDF/RDFS/OWL |
Услуги |
Веб-серверы, поисковые системы, общий доступ к файлам P2P |
Обмен мгновенными сообщениями, Ajax, фреймворки JavaScript, Adobe Flex |
Помощники по обработке персональных данных, интеллектуальный анализ онтологических данных |
Приложения |
Навигатор Netscape, Slashdot, Craigslist |
Карты Google, документы Google, Flickr, YouTube, MediaWiki, WordPress, Facebook, Twitter |
Alexa, Siri, Bixby, Decentraland, DTube, Filecoin, Steevmit, Wolfram Alpha, Mastodon |
За 33 года Интернет превратился из простых поисковых систем в помощников по обработке персональных данных.
Сеть, какой мы ее знаем, эволюционировала с помощью целого ряда технологий, концепций и идей до того, чем она является сегодня. Излишне говорить, что эволюция не собирается останавливаться, и новые идеологии будут вводиться каждый день, чтобы сделать жизнь проще и интереснее.
2.5. Вывод
В то время как Web 1.0 был просто сетью, доступной только для чтения, с однонаправленным потоком информации, появление Web 2.0 привело к расширению социального сотрудничества между создателями контента и пользователями. В Web 2.0 появилось огромное количество создателей контента, которых почти невозможно сосчитать. При столь высоком объеме, разнообразии и скорости передачи данных Web 2.0, а также при централизованном управлении этими данными крупными технологиями практически невозможно отличить реальные данные от спонсируемых и подвергнутых цензуре данных.
Эти опасения по поводу централизованных финансов, зависимости от крупных технологий и необходимости делиться личной информацией с посредниками породили волну новых идеологий и мышления, которые привели мир к появлению технологии Web 3.0.
Web 2.0 никогда по-настоящему не исчезал, а Web 3.0 никогда по-настоящему полностью не вытеснял Web 2.0, однако различия между двумя технологиями недостаточно тонкие, чтобы их игнорировать. В то время как сторонники Web 3.0 называют его будущим Интернета, некоторые скептики не считают его жизнеспособным направлением для Интернета.
В каком бы направлении ни развивалась эволюция Интернета, невозможно полностью игнорировать тот факт, что основы искусственного интеллекта, виртуальной реальности и использования блокчейна растут экспоненциальными темпами. На вопрос о том, действительно ли комбинация этих технологий приведет к появлению четко определенной технологии Web 3.0, можно будет ответить только в будущем.
3. Networking
На сегодняшний день использование клиентов служб мгновенного обмена сообщениями (instant messanger) стало незаменимым средством для всех пользователей Интернета. Существует множество клиентов (Skype, WhatsApp, Viber, ICQ и т. д.), о которых каждый слышал и которые мы ежедневно используем. Все они работают по определенным правилам, т.е. реализуют определенные протоколы взаимодействия.
Protocol — это по сути правила обмена информацией, которые описывают каким образом обмениваются информацией взаимодействующие стороны. Например: существует дипломатический протокол, где дипломаты в определенных случаях должны говорить фразы из определенного набора слов, фраз и другая сторона делает то же самое.
В сетевом взаимодействии - вы посылаете определенные байты и ждете в ответ определенные байты. Этот обмен и есть протокол. Если он соблюдается обеими сторонами, то они смогут о чем-нибудь договориться.
3.1. Сетевые модели
Существуют 2 сетевые модели:
-
OSI- теоритическая (существует только в теории) -
TCP/IP- практическая (используется на практике)
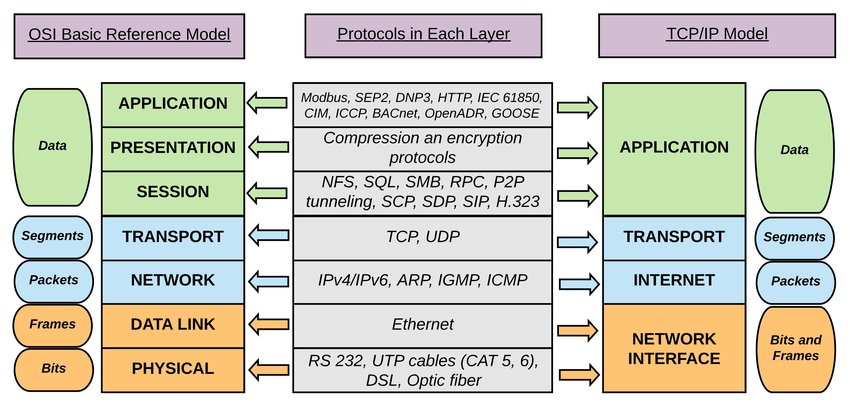
Если рассматривать полную сетевую модель OSI (Open System Interconnection — взаимодействие открытых систем), то прикладного программиста для Web затрагивают в основном протоколы Прикладного уровня — HTTP, FTP, SMTP, SNMP и протоколы Транспортного уровня — TCP и UDP.
Согласно протоколу IP (Internet Packet), каждый узел (компьютер, switch и т.п.) в сети имеет свой IP-адрес. На данный момент интернет работает по протоколу IPv4, где IP адрес записывается 4 числами от 0 до 255 - например, 127.0.0.1. Существует и другой способ идентификации компьютеров в сети через доменное имя, которое более удобное и нагляднее идентифицирует компьютер, чем простой набор чисел (например, github.com). В Интернете существуют специальные сервера DNS (Domain Name System), которые осуществляют преобразование доменного имени в IP-адрес и наоборот.
TCP протокол базируется на IP для доставки пакетов, но добавляет два важных свойства :
-
установление соединения между приложениями
-
использование портов (не просто узлов)
Таким образом, для идентификации компьютера (host) в сети используется IP-адрес; для идентификации приложения TCP добавляет понятие порта. Порт - это целое число от 1 до 65535 указывающее, какому приложению предназначается пакет.
Java имеет достаточно простой в использовании встроенный сетевой интерфейс, который упрощает связь через сокеты TCP/IP или UDP. TCP обычно используется чаще, чем UDP.
3.1.1. TCP Networking
Обычно клиент открывает TCP/IP-соединение с сервером. Затем клиент начинает обмениваться информацией с сервером. Когда клиент завершает работу с сервером, он закрывает соединение.

Клиент может отправлять несколько запросов через открытое соединение. Фактически, клиент может отправлять столько данных, сколько сервер готов к приему. Сервер также может закрыть соединение, если он захочет.
3.1.2. UDP Networking
UDP работает немного иначе, чем TCP. Используя UDP, соединение между клиентом и сервером отсутствует. Клиент может отправлять данные на сервер, и сервер может (или не может) получать эти данные. Клиент никогда не узнает, были ли данные получены на другом конце. То же самое верно для данных, отправленных другим способом от сервера к клиенту.
Поскольку нет гарантии доставки данных, протокол UDP имеет меньшие накладные расходы протокола.
4. 7 шагов по созданию сайта
4.1. Определите цель своего проекта
-
Начните с определения цели вашего проекта. Это может быть демонстрация вашего портфолио всему миру, продажа электронной книги, создание блога и т.д.
-
Определите свою аудиторию. Спросите себя: какой типичный пользователь будет посещать мой сайт?
Это важно, потому что вы всегда должны проектировать с учетом своей цели и аудитории.
4.2. Распланируйте все
-
Как только ваш проект определен, тщательно спланируйте свой контент. Это включает в себя текст, изображения, видео, иконки и т.д.
-
Визуальное представление играет важную роль, когда вы начинаете думать о том, что вы хотите на своем сайте, а что нет.
-
Определение контента перед фактическим запуском дизайна называется подходом, основанным на контенте. Это означает, что вы должны разрабатывать контент, а не разрабатывать веб-страницу, а затем наполнять ее какими-то материалами.
-
Определите навигацию.
-
Определите структуру сайта. На этом шаге вы можете нарисовать карту сайта, если мы говорим о более крупном проекте.
4.3. Нарисуйте свои идеи перед дизайном
-
Теперь пришло время вдохновиться и подумать о своем дизайне. Необходимо перенести все идеи из головы на носитель информации, прежде чем начать проектирование. Это поможет вам изучить идеи и создать концепцию того, что вы хотите построить. Использование карандаша и бумаги - отличный способ быстро сохранить ваши ценные идеи.
-
Сделайте столько эскизов, сколько захотите, но не тратьте слишком много времени на совершенствование чего-либо. Если у вас есть первоначальная идея, вы можете сосредоточиться на деталях при разработке в HTML и CSS.
Я советую вам никогда не начинать проектировать, не имея представления о том, что вы хотите построить. На этом этапе очень важно получить вдохновение.
4.4. Дизайн и разработка вашего сайта
-
Начните разрабатывать свой веб-сайт. Вы сделаете это, используя HTML и CSS, что называется дизайном в браузере.
Проектирование в браузере - это в основном проектирование и разработка одновременно. Все больше дизайнеров покидают традиционные дизайнерские программы, такие как Photoshop, и начинают проектировать в браузере. Основная причина этого в том, что вы не можете создавать адаптивные сайты в фотошопе. Это также экономит вам кучу времени. На этом этапе вы будете использовать свои эскизы, контент и решения по планированию, которые вы приняли на шагах 1, 2 и 3.
4.5. Это еще не сделано: оптимизация
-
Оптимизировать производительность сайта с точки зрения скорости сайта.
-
Необходимо выполнить базовую поисковую оптимизацию (SEO) для поисковых систем, таких как Google.
4.6. Запустить сайт
Все, что вам нужно для запуска:
-
web-server (веб-сервер), на котором будет размещать ваш сайт и обрабатываться пользовательские запросы (хостинг)
-
domain (домен), т.е. адрес по которому сайт будет доступен для пользователей
4.7. Поддержка сайта
Запуск вашего сайта не конец истории.
-
Теперь пришло время отслеживать поведение ваших пользователей и вносить некоторые изменения в ваш сайт, если это необходимо.
-
Вы также должны регулярно обновлять свой контент, чтобы показать своим пользователям, что ваш сайт жив! Например, блог может быть отличным способом сделать это.
5. Семантическая структура страницы
5.1. Элемент article
Элемент article представляет целостный блок информации на странице, который может рассматриваться отдельно и использоваться независимо от других блоков. Например, это может быть пост на форуме или статья в блоге, онлайн-журнале, комментарий пользователя.
Один элемент article может включать несколько элементов article . Например, мы можем заключить в элемент article всю статью в блоге, и этот элемент будет содержать другие элементы article , которые представляют комментарии к этой статье в блоге. То есть статья в блоге может рассматриваться нами как отдельная семантическая единица, и в то же время комментарии также могут рассматривать отдельно вне зависимости от другого содержимого.
Использование article на примере статьи из блога с комментариями:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Семантическая разметка в HTML5</title>
</head>
<body>
<article>
<h2>Lorem ipsum</h2>
<div>
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh
euismod tincidunt ut laoreet dolore magna aliquam erat ...
</div>
<div>
<h3>Комментарии</h3>
<article>
<h4>Неплохо</h4>
<p>Норм статья</p>
</article>
<article>
<h4>Бред</h4>
<p>Мне не понравилось...</p>
</article>
<article>
<h4>Непонятно</h4>
<p>О чем вообще все это?</p>
</article>
</div>
</article>
</body>
</html>
Здесь вся статья может быть помещена в элемент article , и в то же время каждый отдельный комментарий также представляет отдельный элемент article .
При использовании article надо учитывать, что каждый элемент article должен быть идентифицирован с помощью включения в него заголовка h1 - h6 .
5.2. Элемент section
Элемент section объединяет связанные между собой куски информации html -документа, выполняя их группировку. Например, section может включать набор вкладок на странице, новости, объединенные по категории и т.д.
Каждый элемент section должен быть идентифицирован с помощью заголовка h1 - h6 .
При этом элемент section может содержать несколько элементов article , выполняя их группировку, так и один элемент article может содержать несколько элементов section .
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Семантическая разметка в HTML5</title>
</head>
<body>
<article>
<h1>Lorem ipsum</h1>
<section>
<h2>Содержание</h2>
<p>Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh
euismod tincidunt ut laoreet dolore magna aliquam erat ...</p>
</section>
<section>
<h3>Комментарии</h3>
<article>
<h4>Неплохо</h4>
<p>Норм статья</p>
</article>
<article>
<h4>Бред</h4>
<p>Мне не понравилось...</p>
</article>
<article>
<h4>Непонятно</h4>
<p>О чем вообще все это?</p>
</article>
</section>
</article>
</body>
</html>
Здесь для блока основного содержимого создается секция и для набора комментариев также создается элемент section .
5.3. Элемент nav
Элемент nav призван содержать элементы навигации по сайту. Как правило, это ненумерованный список с набором ссылок.
На одной веб-странице можно использовать несколько элементов nav . Например, один элемент навигации для перехода по страницам на сайте, а другой - для перехода внутри html -документа.
Не все ссылки обязательно помещать в элемент nav . Например, некоторые ссылки могут не представлять связанного блока навигации, например, ссылка на главную страницу, на лицензионное соглашение по поводу использования сервиса и подобные ссылки, которые часто помещаются внизу страницы. Как правило, их достаточно определить в элементе footer , а элемент nav для них использовать необязательно.
Используем элемент nav для создания навигационного меню:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Семантическая разметка в HTML5</title>
</head>
<body>
<nav>
<ul>
<li><a href="/">Главная</a></li>
<li><a href="/blog">Блог</a></li>
<li><a href="/contacts">Контакты</a></li>
</ul>
</nav>
<article>
<header>
<h2>Рассказ в двух частях</h2>
</header>
<nav>
<ul>
<li><a href="#part1">Часть 1</a></li>
<li><a href="#part2">Часть 2</a></li>
</ul>
</nav>
<div>
<section id="part1">
<h2>Часть 1</h2>
<p>Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Lorem Ipsum has been the industry...</p>
</section>
<section id="part2">
<h2>Часть 2</h2>
<p>There are many variations of passages of Lorem Ipsum available..</p>
</section>
</div>
<footer>
</footer>
</article>
<footer>
<p><a href="/license">Лицензионное соглашение</a> |
<a href="/about">О сайте</a> |
<a href="/donation">Donations</a></p>
<p><small>© Copyright 2016 MyCorp.</small></p>
</footer>
</body>
</html>
В данном случае определены два блока nav - один для межстраничной навигации, а другой - для навигации внутри страницы.
Необязательно все ссылки помещать в элементы nav . Так, в данном случае ряд ссылок располагаются в элементе footer .
5.4. Элемент header
Элемент header является как бы вводным элементом, предваряющим основное содержимое. Здесь могут быть заголовки, элементы навигации или какие-либо другие вспомогательные элементы, например, логотип, форма поиска и т.п.Например:
<! DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Семантическая разметка в HTML5</title>
</head>
<body>
<header>
<h1>Онлайн-магазин телефонов</h1>
<nav>
<ul>
<li><a href="/apple">Apple</a>
<li><a href="/microsoft">Microsoft</a>
<li><a href="/samsung">Samsung</a>
</ul>
</nav>
</header>
<div>
Информация о новинках мобильного мира....
</div>
</body>
</html>Элемент header нельзя помещать в такие элементы как address , footer или другой header .
5.5. Элемент footer
Элемент footer обычно содержит информацию о том, кто автор контента на веб-странице, копирайт, дата публикации, блок ссылок на похожие ресурсы и т.д. Как правило, подобная информация располагается в конце веб-страницы или основного содержимого, однако, footer не имеет четкой привязки к позиции и может использоваться в различных местах веб-страницы.
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Семантическая разметка в HTML5</title>
</head>
<body>
<h1>Xiaomi Mi 5</h1>
<div>
Xiaomi Mi 5 оснащен восьмиядерным процессором Qualcomm Snapdragon 820.
Размер внутреннего хранилища - 32 и 64 МБ.
</div>
<footer>
<p><a href="/license">Лицензионное соглашение</a><br/>
Copyright © 2016. SomeSite.com</p>
</footer>
</body>
</html>Здесь определен футер для всей веб-страницы. В него помещена ссылка на лицензионное соглашение использования сервисом и информация о копирайте.
Футер необязательно должен быть определен для всей страницы. Это может быть и отдельная секция контента:
<!DOCTYPE html>
<html lang="ru">
</html>Элемент footer не следует помещать в такие элементы как address , header или другой footer .
5.6. Элемент address
Элемент address предназначен для отображения контактной информации, которая связана с ближайшим элементом article или body. Нередко данный элемент размещается в футере:
5.7. Элемент aside
Элемент aside представляет содержимое, которое косвенно связано с остальным контентом веб-станицы и которое может рассматриваться независимо от него. Данный элемент можно использовать, например, для сайдбаров, для рекламных блоков, блоков навигационных элементов, различных плагинов типа твиттера или фейсбука и т.д.
<!DOCTYPE html>
<html lang="ru">
</html>
Здесь содержимое блока aside довольно косвенно связано с основным контентом из элемента article . Поэтому все это содержимое мы можем поместить в aside .
5.8. Элемент main
Элемент main представляет основное содержимое веб-страницы. Он представляет уникальный контент, в который не следует включать повторяющиеся на разных веб-страницах элементы сайдбаров, навигационные ссылки, информацию о копирайте, логотипы и тому подобное.
Используем элемент main :
<!DOCTYPE html>
<html lang="ru">
</html>
Не стоит думать, что абсолютно все содержимое надо обязательно помещать в элемент main. Нет мы также можем использовать вне его другие элементы, например, header и footer:
Однако надо помнить, что элемент main не может быть вложенным в такие элементы, как article , aside , footer , header , nav .Кроме того, на веб-странице допустимо наличие только одного элемента main .
Также стоит отметить, что на данный момент есть небольшие проблемы с поддержкой этого элемента в браузерах. В частности, IE 11 не поддерживает данный элемент (в остальных браузерах полная поддержка), поэтому в этом случае стоит использовать атрибут роли:
Указание роли позволит IE11 и более старшим версиям IE должным образом интерпретировать элемент.
6. Формы
Формы нужны для того, чтобы отправлять данные с веб-страницы на веб-сервер, который сможет эти данные обработать: зарегистрировать пользователя, создать сообщение на форуме, отправить письмо и так далее. В общем, формы в вебе просто необходимы.
6.1. Первая форма
Чтобы создать форму, нужно использовать парный тег <form> , внутри которого размещаются поля формы. У тега <form> есть два важных атрибута:
-
actionзадаёт адрес,URL, отправки формы -
methodзадаёт метод отправки формы.
Пример:
<form action="https://rakovets.com" method="get">
поля формы
</form>Для отправки формы обычно используют методы GET или POST. Если не указать атрибут method , то будет использован GET.
Метод GET посылает данные формы в строке запроса, то есть они видны в адресной строке браузера и следуют после знака вопроса. Например:
Метод GET лучше использовать в поисковых формах, потому что он позволяет получить ссылку на результаты поиска и передать её кому-то.
Метод POST посылает данные в теле HTTP -запроса и используется, когда нужно отправить много данных и ссылка на результат обработки этих данных не нужна. Например, при редактировании личного профиля.
6.2. Текстовое поле ввода
Большинство полей форм создаётся с помощью одиночного тега <input>. У этого тега два обязательных атрибута:
-
typeзадаёт тип поля -
nameзадаёт имя поля
Тип поля влияет на то, как оно будет отображаться и вести себя. Самый распространённый тип — это text , который обозначает текстовое поле. Он же используется по умолчанию.
Пример:
<form action="https://rakovets.com" method="get">
<input type="text" name="search">
</form>Имя поля нужно, чтобы правильно обработать данные на сервере. Обычно, имя поля должно быть уникальным в пределах формы, хотя есть исключения. Для задания имени поля используют латинские буквы и цифры.
6.3. Идентификатор и значение по умолчанию
Атрибут id поля ввода обозначает идентификатор. Он должен быть уникальным не только в пределах формы, но и на всей странице.
Обычно идентификаторы используют для повышения удобства работы с формой, например, создают подписи, связанные с мелкими полями. При щелчке по таким подписям активируется связанное поле. И это удобно, так как по большой подписи попасть легче, чем по маленькому полю. Также идентификаторы используют в JavaScript для работы с полями.
Идентификатор в отличие от имени поля не передаётся на сервер. Лучше использовать идентификаторы, отличающиеся от имени поля, особенно актуально это для полей множественного выбора, которые мы разберём далее.
Атрибут value задаёт значение поля ввода по умолчанию. Это тоже повышает удобство.
Согласитесь, приятно зайти в огромную анкету на каких-нибудь госуслугах, а там ваши паспортные данные уже подставлены в нужные поля и заполнять их не надо. И всё благодаря тому, что программист добавил к полям атрибут value с нужными данными.
6.4. Подпись для поля ввода
Можно подумать, что сделать подпись к полю очень просто. Пишем текст рядом с полем и всё готово:
Подпись <input type="text" name="username">На самом деле этого недостаточно — мы получили просто кусок текста и поле, которые расположены рядом друг с другом, но логически никак не связаны.
Есть специальный тег, который позволяет смело сказать: «Этот кусок текста действительно подпись к этому полю!». Это парный тег <label>.
Он связывает текст и поле ввода логически. А ещё если щёлкнуть по тексту в такой подписи, то курсор переместится в соответствующее поле.
Создавать подписи к полям с помощью <label> — хороший приём. Используйте его.
Первый способ создать подпись — просто обернуть текст подписи и тег поля в тег <label> , вот так:
<label>
Подпись <input type="text" name="username">
</label>Надо отметить, что при оборачивании текста в тег <label> он визуально никак не меняется, ведь главная задача подписи — создать логическую связь.
6.5. Связываем подпись и поле по id
Иногда обернуть поле и текст подписи в тег <label> нельзя. Например, когда они размещены в разных ячейках таблицы.
В этом случае можно связать подпись с полем с помощью атрибута id. Алгоритм такой:
-
Добавляем к полю ввода идентификатор с помощью атрибута id.
-
Оборачиваем текст подписи в тег <label>.
-
Добавляем тегу <label> атрибут for.
-
В атрибут for записываем такое же значение, что и в атрибуте id у поля.
Например:
<label for="user-field-id">Имя пользователя</label>
...
много-много других тегов
...
<input id="user-field-id" type="text" name="username">6.6. Поле для ввода пароля
Чтобы сделать поле для ввода пароля, в котором текст будет отображаться «звёздочками», нужно просто изменить значение атрибута type на password.
6.7. Кнопка для отправки формы
Форма практически готова. Осталось добавить кнопку для отправки формы. Такая кнопка создаётся с помощью тега <input> c типом submit.
Надпись на кнопке можно задать с помощью атрибута value. Для кнопки отправки формы задавать имя необязательно. Но если имя задано, то на сервер будут отправляться имя и значение кнопки.
Обычно имя для кнопки отправки задают, когда в форме несколько кнопок, отвечающих за разные действия. Браузер отправляет на сервер имя и значение только той из них, на которую нажал пользователь. Таким образом, сервер может понять, какую кнопку нажали и что нужно сделать.
6.8. Многострочное поле ввода
Мы научились создавать простейшие формы с текстовыми полями и кнопками. А теперь познакомимся с более сложными элементами формы.
Многострочное текстовое поле создаётся с помощью парного тега <textarea>. У него есть атрибуты name и id , которые аналогичны атрибутам текстового поля.
Атрибут rows принимает целочисленное значение и задаёт высоту многострочного поля в строках. Атрибут cols задаёт ширину поля в символах. В качестве ширины символа берётся некоторая «усреднённая ширина».
Атрибут value у многострочного поля отсутствует, а значение по умолчанию задаётся по-другому. Текст, расположенный между открывающим и закрывающим тегом <textarea> и является значением по умолчанию. Вот так:
<textarea>Значение по умолчанию</textarea>6.9. Чекбокс и галочка
Поле-галочка — это тег <input> с типом checkbox.
Галочка работает по принципу «либо да, либо нет». Если галочка стоит, то браузер посылает переменную с именем поля на сервер, если галочки нет, то не посылается ничего. Таким образом, атрибут value не является обязательным.
Чтобы галочка стояла по умолчанию, нужно добавить к тегу атрибут checked. Вот так:
<input type="checkbox" checked>Чекбокс не подразумевает выбор одного элемента из нескольких. Поэтому если в одной форме есть несколько чекбоксов, то имена у них должны быть разными.
6.10. Переключатель и radiobutton
Поле-переключатель — это тег <input> с типом radio.
Обычно переключатели размещают группами по несколько штук. Причём у переключателей из одной группы должно быть одинаковое имя и разные значения, которые задаются с помощью value.
Таким образом, атрибут value является для переключателей обязательным. Браузер отправляет на сервер значение value выбранного переключателя.
В этом задании мы начнём создавать переключатель.
6.11. Группа переключателей
Теперь добавим ещё один вариант ответа в наш переключатель. Для этого нужно добавить ещё один <input> с таким же именем, но другим значением value.
Подобным образом можно создавать группы переключателей с любым количеством вариантов.
Чтобы сделать какой-либо вариант в переключателе выбранным по умолчанию, нужно добавить к соответствующему тегу <input> атрибут checked , как у поля-галочки.
Кстати, имя поля у переключателей одной группы должно быть одинаковым, но идентификаторы всегда должны быть уникальными.
6.12. Раскрывающийся список или селект
Раскрывающийся список так же, как и переключатель, позволяет выбрать один вариант ответа из нескольких.
Раскрывающийся список создаётся с помощью парного тега <select> , у которого есть знакомые атрибуты name и id.
Варианты ответов задаются с помощью парных тегов <option> , которые должны располагаться внутри тега <select>. Например:
<select name="theme">
<option value="light">Светлая тема</option>
<option value="dark">Тёмная тема</option>
...
</select>В атрибуте value тега <option> задаётся значение варианта ответа, а внутри этого тега располагается подпись варианта ответа.
Если при отправке формы у выбранного варианта задан value , то на сервер отправится значение этого атрибута. В противном случае будет отправлен текст подписи.
6.13. Мультиселект
Раскрывающийся список можно превратить в так называемый «мультиселект», то есть список, в котором можно выбрать не один, а несколько вариантов.
Чтобы сделать это, нужно добавить к тегу <select> атрибут multiple.
Выбрать несколько вариантов можно, щёлкая по ним с зажатой клавишей Ctrl на Linux и Windows или Command на OS X.
Высоту мультиселекта можно изменять с помощью атрибута size тега <select>.
Чтобы отметить как выбранные по умолчанию одно или несколько значений, нужно к соответствующим тегам <option> добавить атрибут selected.
При отправке данных мультиселекта на сервер с PHP после имени в значении атрибута name ставятся символы квадратных скобок []. Например, <select name="days[]">. Это необязательное требование для имени мультиселекта, а нужно только для корректной обработки данных в PHP.
6.14. Поле для загрузки
Поле для загрузки файлов — это тег <input> с типом file. Для этого поля обязательным атрибутом является имя.
Чтобы поле заработало и браузер смог передать выбранный файл на сервер, необходимо добавить форме атрибут enctype со значением multipart/form-data. Не полю, а форме.
Кстати, внешний вид таких полей очень сильно отличается в зависимости от операционной системы и очень плохо изменяется с помощью стилей.
6.15. Скрытое поле
И ещё одно невидимое и очень полезное поле. Это скрытое поле. Его используют, когда в форме нужно отправить какие-то дополнительные служебные данные, которые не вводятся пользователем.
Например, это могут быть реквизиты заказа или номер пользователя в форме оплаты.
Скрытое поле — это тег <input> с типом hidden.
7. Селекторы
7.1. Введение в стили
Любой html-документ, сколько бы он элементов не содержал, будет по сути "мертвым" без использования стилей. Стили или лучше сказать каскадные таблицы стилей (Cascading Style Sheets) или попросту CSS определяют представление документа, его внешний вид. Рассмотрим вкратце применение стилей в контексте HTML5.
Стиль в CSS представляет правило, которое указывает веб-браузеру, как надо форматировать элемент. Форматирование может включать установку цвета фона элемента, установку цвета и типа шрифта и так далее.
Определение стиля состоит из двух частей:
-
селектор, который указывает на элемент
-
блок объявления стиля - набор команд, которые устанавливают правила форматирования
Например:
div {
background-color: red;
width: 100px;
height: 60px;
}В данном случае селектором является div . Этот селектор указывает, что этот стиль будет применяться ко всем элементам div .
После селектора в фигурных скобках идет блок объявления стиля. Между открывающей и закрывающей фигурными скобками определяются команды, указывающие, как форматировать элемент.
Каждая команда состоит из свойства и значения. Так, в следующем выражении:
background-color: red;background-color представляет свойство, а red - значение. Свойство определяет конкретный стиль. Свойств css существует множество. Например, background-color определяет цвет фона. После двоеточия идет значение для этого свойства. Например, выше указанная команда определяет для свойства background-color значение red . Иными словами, для фона элемента устанавливается цвет red , то есть красный.
После каждой команды ставится точка с запятой, которая отделяет данную команду от других.
Наборы таких стилей часто называют таблицами стилей или CSS (Cascading Style Sheets или каскадные таблицы стилей). Существуют различные способы определения стилей.
7.2. Атрибут style
Первый способ заключается во встраивании стилей непосредственно в элемент с помощью атрибута style:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Стили</title>
</head>
<body>
<h2 style="color:blue;">Стили</h2>
<div style="width: 100px; height: 100px; background-color: red;"></div>
</body>
</html>7.3. Inline-стили элементов html5
Здесь определены два элемента - заголовок h2 и блок div . У заголовка определен синий цвет текста с помощью свойства color . У блока div определены свойства ширины width , высоты height , а также цвета фона background-color .
Второй способ состоит в использования элемента style в документе html. Этот элемент сообщает браузеру, что данные внутри являются кодом css, а не html:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Стили</title>
<style>
h2 {
color: blue;
}
div {
width: 100px;
height: 100px;
background-color: red;
}
</style>
</head>
<body>
<h2>Стили</h2>
<div></div>
</body>
</html>Результат в данном случае будет абсолютно тем же, что и в предыдущем случае.
Часто элемент style определяется внутри элемента head , однако может также использоваться в других частях HTML-документа. Элемент style содержит наборы стилей. У каждого стиля указывается вначале селектор, после чего в фигурных скобках идет все те же определения свойств css и их значения, что были использованы в предыдущем примере.
Второй способ делает код html чище за счет вынесения стилей в элемент style . Но также есть и третий способ, который заключается в вынесении стилей во внешний файл.
Создадим в одной папке с html странице текстовый файл, который переименуем в styles.css и определим в нем следующее содержимое:
h2 {
color: blue;
}
div {
width: 100px;
height: 100px;
background-color: red;
}Это те же стили, что были внутри элемента style . И также изменим код html-страницы:
``html
<! DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Стили</title>
<link rel="stylesheet" type="text/css" href="styles.css"/>
</head>
<body>
<h2>Стили</h2>
<div></div>
</body>
</html>
Здесь уже нет элемента `style` , зато есть элемент `link` , который подключает выше созданный файл `styles.css` :
Таким образом, определяя стили во внешнем файле, мы делаем код html чище, структура страницы отделяется от ее стилизации.При таком определении стили гораздо легче модифицировать, чем если бы они были определены внутри элементов или в элементе `style` , и такой способ является предпочтительным в *HTML5*. Использование стилй во внешних файлов позволяет уменьшить нагрузку на веб-сервер с помощью механизма кэширования.Поскольку веб-браузер может кэшировать css-файл и при последующем обращении к веб-странице извлекать нужный css-файл из кэша. Также возможна ситуация, когда все эти подходы сочетаются, а для одного элемента одни свойства css определены внутри самого элемента, другие свойства css определены внутри элемента style, а третьи находятся во внешнем подключенном файле.Например:
<!DOCTYPE html> <html>
</html>
А в файле `style.css` определен следующий стиль:
div { width: 50px; height: 50px; background-color: red; }
В данном случае в трех местах для элемента `div` определено свойство `width` , причем с разным значением.Какое значение будет применяться к элементу в итоге? Здесь у нас действует следующая система приоритетов: * Если у элемента определены *inline-стили*, то они имеют высший приоритет * далее в порядке приоритета идут стили, которые определены в элементе `style` * Наименее приоритетными стилями являются те, которые определены во внешнем файле. ## Атрибуты html и стили css Многие элементы html позволяют устанавливать стили отображения с помощью атрибутов.Например, у ряда элементов мы можем применять атрибуты `width` и `height` для установки ширины и высоты элемента соответственно.Однако подобного подхода следует избегать и вместо встроенных атрибутов следует применять стили CSS.Важно четко понимать, что разметка HTML должна предоставлять только структуру html-документа, а весь его внешний вид, стилизацию должны определять стили CSS. ## Валидация кода CSS В процессе написания стилей CSS могут возникать вопросы, а правильно ли так определять стили, корректны ли они.И в этом случае мы можем воспользоваться валидатором css, который доступен по адресу https://jigsaw.w3.org/css-validator/. ## Селекторы Определение стиля начинается с селектора.Например:
div { width: 50px; /* ширина / height: 50px; / высота / background-color: red; / цвет фона / margin: 10px; / отступ от других элементов */ }
В данном случае селектором является `div` .Ряд селекторов наследуют название форматируемых элементов, например, `div` , `p` , `h2` и т.д.При определении такого селектора его стиль будет применяться ко всем элементам соответствующих данному селектору.То есть выше определенный стиль будет применяться ко всем элементам `<div>` на веб-странице:
<!DOCTYPE html> <html>
</html>
Здесь на странице 3 элемента `div` , и все они будут стилизованы: ## Селекторы CSS: Классы Иногда для одних и тех же элементов требуется различная стилизация.И в этом случае мы можем использовать классы. Для определения селектора класса в CSS перед названием класса ставится точка:
background-color: red; }
Название класса может быть произвольным.Например, в данном случае название класса - `redBlock` .Однако при этом в имени класса разрешается использовать буквы, числа, дефисы и знаки подчеркивания, причем начинать название класса должно обязательно с буквы. Также стоит учитывать регистр имен: названия `article` и `ARTICLE` будут представлять разные классы. После определения класса мы можем его применить к элементу с помощью атрибута `class` .Например:
``
Определим и используем несколько классов:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Классы CSS</title>
<style>
div {
width: 50px;
height: 50px;
margin: 10px;
}
.redBlock {
background-color: red;
}
.blueBlock {
background-color: blue;
}
</style>
</head>
<body>
<h2>Классы CSS</h2>
<div class="redBlock"></div>
<div class="blueBlock"></div>
<div class="redBlock"></div>
</body>
</html>7.4. Классы в CSS3: Идентификаторы
Для идентификации уникальных на веб-станице элементов используются идентификаторы, которые определяются с помощью атрибутов id . Например, на странице может быть головной блок или шапка:
<div id="header"></div>Определение стилей для идентификаторов аналогично определению классов, только вместо точки ставится символ решетки # :
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Идентификаторы CSS</title>
<style>
div {
margin: 10px;
border: 1px solid #222;
}
#header {
height: 80px;
background-color: #ccc;
}
#content {
height: 180px;
background-color: #eee;
}
#footer {
height: 80px;
background-color: #ccc;
}
</style>
</head>
<body>
<div id="header">Шапка сайта</div>
<div id="content">Основное содержимое</div>
<div id="footer">Футер</div>
</body>
</html>7.5. Идентификаторы в CSS3
Однако стоит заметить, что идентификаторы в большей степени относятся к структуре веб-странице и в меньшей степени к стилизации. Для стилизации преимущественно используются классы, нежели идентификаторы.
7.5.1. Универсальный селектор
Кроме селекторов тегов, классов и идентификаторов в css также есть так называемый универсальный селектор, который представляет знак звездочки *. Он применяет стили ко всем элементам на html-странице:
* {
background-color: red;
}7.5.2. Стилизация группы селекторов
Иногда определенные стили применяются к целому ряду селекторов. Например, мы хотим применить ко всем заголовкам подчеркивание. В этом случае мы можем перечислить селекторы всех элементов через запятую:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Селекторы CSS</title>
<style>
h1, h2, h3, h4 {
color: red;
}
</style>
</head>
<body>
<h1>CSS3<h1>
<h2>Селекторы</h2>
<h3>Группа селекторов</h3>
<p>Некоторый текст...</p>
</body>
</html>7.5.3. Группа селекторов в CSS3
Группа селекторов может содержать как селекторы тегов, так и селекторы классов и идентификаторов, например:
h1, #header, .redBlock {
color: red;
}