1. StringBuffer и StringBuilder
Объекты String являются неизменяемыми, поэтому все операции, которые изменяют строки, фактически приводят к созданию новой строки, что сказывается на производительности приложения. Для решения этой проблемы, чтобы работа со строками проходила с меньшими издержками в Java были добавлены классы StringBuffer и StringBuilder. По сути они напоминает расширяемую строку, которую можно изменять без ущерба для производительности.
Эти классы похожи, практически двойники, они имеют одинаковые конструкторы, одни и те же методы, которые одинаково используются. Единственное их различие состоит в том, что класс StringBuffer синхронизированный и потокобезопасный. То есть класс StringBuffer удобнее использовать в многопоточных приложениях, где объект данного класса может меняться в различных потоках. Если же речь о многопоточных приложениях не идет, то лучше использовать класс StringBuilder, который не потокобезопасный, но при этом работает быстрее, чем StringBuffer в однопоточных приложениях.
StringBuffer определяет четыре конструктора:
StringBuffer()
StringBuffer(int capacity)
StringBuffer(String str)
StringBuffer(CharSequence chars)Аналогичные конструкторы определяет StringBuilder:
StringBuilder()
StringBuilder(int capacity)
StringBuilder(String str)
StringBuilder(CharSequence chars)Рассмотрим работу этих классов на примере функциональности StringBuffer.
При всех операциях со строками StringBuffer / StringBuilder перераспределяет выделенную память. И чтобы избежать слишком частого перераспределения памяти, StringBuffer/StringBuilder заранее резервирует некоторую область памяти, которая может использоваться. Конструктор без параметров резервирует в памяти место для 16 символов. Если мы хотим, чтобы количество символов было иным, то мы можем применить второй конструктор, который в качестве параметра принимает количество символов.
Третий и четвертый конструкторы обоих классов принимают строку и набор символов, при этом резервируя память для дополнительных 16 символов.
С помощью метода capacity() мы можем получить количество символов, для которых зарезервирована память. А с помощью метода ensureCapacity() изменить минимальную емкость буфера символов:
String str = "Java";
StringBuffer strBuffer = new StringBuffer(str);
System.out.println("Емкость: " + strBuffer.capacity()); // 20
strBuffer.ensureCapacity(32);
System.out.println("Емкость: " + strBuffer.capacity()); // 42
System.out.println("Длина: " + strBuffer.length()); // 4Так как в самом начале StringBuffer инициализируется строкой "Java", то его емкость составляет 4 + 16 = 20 символов. Затем мы увеличиваем емкость буфера с помощью вызова strBuffer.ensureCapacity(32) повышаем минимальную емкость буфера до 32 символов. Однако финальная емкость может отличаться в большую сторону. Так, в данном случае я получаю емкость не 32 и не 32 + 4 = 36, а 42 символа. Дело в том, что в целях повышения эффективности Java может дополнительно выделять память.
Но в любом случае вне зависимости от емкости длина строки, которую можно получить с помощью метода length(), в StringBuffer остается прежней - 4 символа (так как в "Java" 4 символа).
Чтобы получить строку, которая хранится в StringBuffer, мы можем использовать стандартный метод toString():
String str = "Java";
StringBuffer strBuffer = new StringBuffer(str);
System.out.println(strBuffer.toString()); // JavaПо всем своим операциям StringBuffer и StringBuilder напоминают класс String.
1.1. charAt() и setCharAt()
Метод charAt() получает, а метод setCharAt() устанавливает символ по определенному индексу:
StringBuffer strBuffer = new StringBuffer("Java");
char c = strBuffer.charAt(0); // J
System.out.println(c);
strBuffer.setCharAt(0, 'c');
System.out.println(strBuffer.toString()); // cava1.2. getChars()
Метод getChars() получает набор символов между определенными индексами:
StringBuffer strBuffer = new StringBuffer("world");
int startIndex = 1;
int endIndex = 4;
char[] buffer = new char[endIndex-startIndex];
strBuffer.getChars(startIndex, endIndex, buffer, 0);
System.out.println(buffer); // orl1.3. append()
Метод append() добавляет подстроку в конец StringBuffer:
StringBuffer strBuffer = new StringBuffer("hello");
strBuffer.append(" world");
System.out.println(strBuffer.toString()); // hello world1.4. insert()
Метод insert() добавляет строку или символ по определенному индексу в StringBuffer:
StringBuffer strBuffer = new StringBuffer("word");
strBuffer.insert(3, 'l');
System.out.println(strBuffer.toString()); // world
strBuffer.insert(0, "s");
System.out.println(strBuffer.toString()); // sworld1.5. delete() и deleteCharAt()
Метод delete() удаляет все символы с определенного индекса о определенной позиции, а метод deleteCharAt() удаляет один символ по определенному индексу:
StringBuffer strBuffer = new StringBuffer("assembler");
strBuffer.delete(0,2);
System.out.println(strBuffer.toString()); // sembler
strBuffer.deleteCharAt(6);
System.out.println(strBuffer.toString()); // semble1.6. substring()
Метод substring() обрезает строку с определенного индекса до конца, либо до определенного индекса:
StringBuffer strBuffer = new StringBuffer("hello java!");
String str1 = strBuffer.substring(6); // обрезка строки с 6 символа до конца
System.out.println(str1); //java!
String str2 = strBuffer.substring(3, 9); // обрезка строки с 3 по 9 символ
System.out.println(str2); //lo jav1.7. setLength()
Для изменения длины StringBuffer (не емкости буфера символов) применяется метод setLength(). Если StringBuffer увеличивается, то его строка просто дополняется в конце пустыми символами, если уменьшается - то строка по сути обрезается:
StringBuffer strBuffer = new StringBuffer("hello");
strBuffer.setLength(10);
System.out.println(strBuffer.toString()); // "hello "
strBuffer.setLength(4);
System.out.println(strBuffer.toString()); // "hell"1.8. replace()
Для замены подстроки между определенными позициями в StringBuffer на другую подстроку применяется метод replace():
StringBuffer strBuffer = new StringBuffer("hello world!");
strBuffer.replace(6, 11, "java");
System.out.println(strBuffer.toString()); // hello java!Первый параметр метода replace() указывает, с какой позиции надо начать замену, второй параметр - до какой позиции, а третий параметр указывает на подстроку замены.
1.9. reverse()
Метод reverse() меняет порядок в StringBuffer на обратный:
StringBuffer strBuffer = new StringBuffer("assembler");
strBuffer.reverse();
System.out.println(strBuffer.toString()); // relbmessa2. Регулярные выражения
Регулярные выражения представляют мощный инструмент для обработки строк. Регулярные выражения позволяют задать шаблон, которому должна соответствовать строка или подстрока.
Большая часть функциональности по работе с регулярными выражениями в Java сосредоточена в пакете java.util.regex.
Само регулярное выражение представляет шаблон для поиска совпадений в строке. Для задания подобного шаблона и поиска подстрок в строке, которые удовлетворяют данному шаблону, в Java определены классы Pattern и Matcher.
2.1. Pattern
2.1.1. matches()
Для простого поиска соответствий в классе Pattern определен статический метод matches(String pattern, CharSequence input). Данный метод возвращает true, если последовательность символов input полностью соответствует шаблону строки pattern:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
boolean found = Pattern.matches("Hello", input);
if(found) {
System.out.println("Найдено");
} else {
System.out.println("Не найдено");
}
}
}2.1.2. split()
С помощью метода split() класса Pattern можно разделить строку на массив подстрок по определенному разделителю. Например, мы хотим выделить из строки отдельные слова:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE.";
Pattern pattern = Pattern.compile("[ ,.!?]");
String[] words = pattern.split(input);
for (String word : words) {
System.out.println(word);
}
}
}И консоль выведет набор слов:
Hello
Java
Hello
JavaScript
JavaSEПри этом все символы-разделители удаляются. Однако, данный способ разбивки не идеален: у нас остаются некоторые пробелы, которые расцениваются как лексемы, а не как разделители. Для более точной и изощренной разбивки нам следует применять элементы регулярных выражений. Так, заменим шаблон на следующий:
Pattern pattern = Pattern.compile("\\s*(\\s|,|!|\\.)\\s*");Теперь у нас останутся только слова:
Hello
Java
Hello
JavaScript
JavaSE
82.2. Matcher
Но, как правило, для поиска соответствий применяется другой способ - использование класса Matcher.
Используем класс Matcher. Для этого вначале надо создать объект Pattern с помощью статического метода compile(), который позволяет установить шаблон:
Pattern pattern = Pattern.compile("Hello");В качестве шаблона выступает строка "Hello". Метод compile() возвращает объект Pattern, который мы затем можем использовать в программе.
В классе Pattern также определен метод matcher(), который в качестве параметра принимает строку, где надо проводить поиск, и возвращает объект Matcher:
String input = "Hello world! Hello Java!";
Pattern pattern = Pattern.compile("hello");
Matcher matcher = pattern.matcher(input);2.2.1. matches()
Затем у объекта Matcher вызывается метод matches() для поиска соответствий шаблону в тексте:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
Pattern pattern = Pattern.compile("Hello");
Matcher matcher = pattern.matcher(input);
boolean found = matcher.matches();
if (found) {
System.out.println("Найдено");
} else {
System.out.println("Не найдено");
}
}
}2.2.2. find() и group()
Рассмотрим более функциональный пример с нахождением не полного соответствия, а отдельных совпадений в строке:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE.";
Pattern pattern = Pattern.compile("Java(\\w*)");
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
}Допустим, мы хотим найти в строке все вхождения слова Java. В исходной строке это три слова: "Java", "JavaScript" и "JavaSE". Для этого применим шаблон "Java(\\w*)". Данный шаблон использует синтаксис регулярных выражений. Слово "Java" в начале говорит о том, что все совпадения в строке должны начинаться на Java. Выражение (\\w*) означает, что после "Java" в совпадении может находиться любое количество алфавитно-цифровых символов. Выражение \w означает алфавитно-цифровой символ, а звездочка после выражения указывает на неопределенное их количество - их может быть один, два, три или вообще не быть. И чтобы java не рассматривала \w как escape-последовательность, как \n, то выражение экранируется еще одним слэшем.
Далее применяется метод find() класса Matcher, который позволяет переходить к следующему совпадению в строке. То есть первый вызов этого метода найдет первое совпадение в строке, второй вызов найдет второе совпадение и т.д. То есть с помощью цикла while(matcher.find()) мы можем пройтись по всем совпадениям. Каждое совпадение мы можем получить с помощью метода matcher.group(). В итоге программа выдаст следующий результат:
Java
JavaScript
JavaSE2.2.3. replaceAll()
Можно сделать замену всех совпадений с помощью метода replaceAll():
String input = "Hello Java! Hello JavaScript! JavaSE.";
Pattern pattern = Pattern.compile("Java(\\w*)");
Matcher matcher = pattern.matcher(input);
String newStr = matcher.replaceAll("HTML");
System.out.println(newStr); // Hello HTML! Hello HTML! HTML.2.3. String
Некоторые методы класса String принимают регулярные выражения и используют их для выполнения операций над строками.
2.3.1. split()
Для разделения строки на подстроки применяется метод split(). В качестве параметра он может принимать регулярное выражение, которое представляет критерий разделения строки.
Например, разделим предложение на слова:
String text = "FIFA will never regret it";
String[] words = text.split("\\s*(\\s|,|!|\\.)\\s*");
for (String word : words) {
System.out.println(word);
}Для разделения применяется регулярное выражение "\\s*(\\s|,|!|\\.)\\s*". Подвыражение "\\s" по сути представляет пробел. Звездочка указывает, что символ может присутствовать от 0 до бесконечного количества раз. То есть добавляем звездочку и мы получаем неопределенное количество идущих подряд пробелов - "\\s*" (то есть неважно, сколько пробелов между словами). Причем пробелы может вообще не быть. В скобках указывает группа выражений, которая может идти после неопределенного количества пробелов. Группа позволяет нам определить набор значений через вертикальную черту, и подстрока должна соответствовать одному из этих значений. То есть в группе "\\s|,|!|\\." подстрока может соответствовать пробелу, запятой, восклицательному знаку или точке. Причем поскольку точка представляет специальную последовательность, то, чтобы указать, что мы имеем в виду именно знак точки, а не специальную последовательность, перед точкой ставим слэши.
2.3.2. matches()
Еще один метод класса String - matches() принимает регулярное выражение и возвращает true, если строка соответствует этому выражению. Иначе возвращает false.
Например, проверим, соответствует ли строка номеру телефона:
String input = "+12343454556";
boolean result = input.matches("(\\+*)\\d{11}");
if (result == true) {
System.out.println("It is a phone number");
} else {
System.out.println("It is not a phone number!");
}В данном случае в регулярном выражении сначала определяется группа "(\\+*)". То есть вначале может идти знак плюса, но также он может отсутствовать. Далее смотрим, соответствуют ли последующие 11 символов цифрам. Выражение "\\d" представляет цифровой символ, а число в фигурных скобках - {11} - сколько раз данный тип символов должен повторяться. То есть мы ищем строку, где вначале может идти знак плюс (или он может отсутствовать), а потом идет 11 цифровых символов.
2.3.3. replaceAll()
Также надо отметить, что в классе String также имеется метод replaceAll() с заменой всех выражений, удовлетворяющих регулярному выражению:
String input = "Hello Java! Hello JavaScript! JavaSE.";
String myStr =input.replaceAll("Java(\\w*)", "HTML");
System.out.println(myStr); // Hello HTML! Hello HTML! HTML.3. Класс Object
Хотя мы можем создать обычный класс, который не является наследником, но фактически все классы наследуют от класса Object. Все остальные классы, даже те, которые мы добавляем в свой проект, являются неявно производными от класса Object. Поэтому все типы и классы могут реализовать те методы, которые определены в классе Object.
3.1. hashCode()
3.1.1. Что такое хеш-код?
Если очень просто, то (хеш-код) — это число. Если более точно, то это битовая строка фиксированной длины, полученная из массива произвольной длины.
Выполним следующий код:
public class Main {
public static void main(String[] args) {
Object object = new Object();
int hCode;
hCode = object.hashCode();
System.out.println(hCode);
}
}В результате выполнения программы в консоль выведется целое 10-ти значное число. Это число и есть битовая строка фиксированной длины. В java она представлена в виде числа примитивного типа int, который равен 4-м байтам, и может помещать числа от -2_147_483_648 до 2_147_483_647. На данном этапе важно понимать, что хеш-код это число, у которого есть свой предел, который для java ограничен примитивным целочисленным типом int.
Вторая часть объяснения гласит: полученная из массива произвольной длины. Под массивом произвольной длины будет понимать объект. В примере выше в качестве массива произвольной длины выступает объект типа Object.
В итоге в терминах Java, хеш-код — это целочисленный результат работы метода, которому в качестве входного параметра передан объект.
Этот метод реализован таким образом, что для одного и того-же входного объекта, хеш-код всегда будет одинаковым. Следует понимать, что множество возможных хеш-кодов ограничено примитивным типом int, а множество объектов ограничено только нашей фантазией. Отсюда следует утверждение: Множество объектов мощнее множества хеш-кодов. Из-за этого ограничения, вполне возможна ситуация, что хеш-коды разных объектов могут совпасть.
Здесь главное понять, что:
-
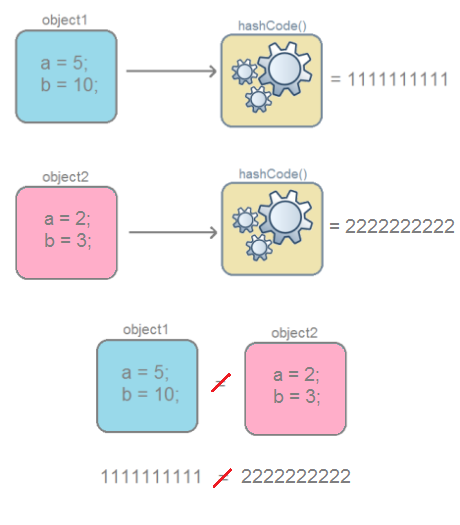
Если хеш-коды разные, то и входные объекты гарантированно будут разные.
-
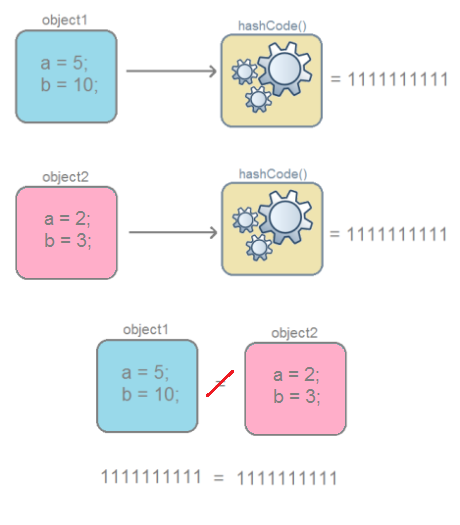
Если хеш-коды равны, то входные объекты не всегда равны.
Ситуация, когда у разных объектов одинаковые хеш-коды называется — коллизией. Вероятность возникновения коллизии зависит от используемого алгоритма генерации хеш-кода.
3.1.2. hashCode()
Person tom = new Person("Tom");
System.out.println(tom.hashCode()); // 2036368507Но мы можем задать свой алгоритм определения хэш-кода объекта:
class Person {
private String name;
public Person(String name) {
this.name = name;
}
@Override
public int hashCode(){
return 11 * name.hashCode() + 7;
}
}3.1.3. Подведём итог
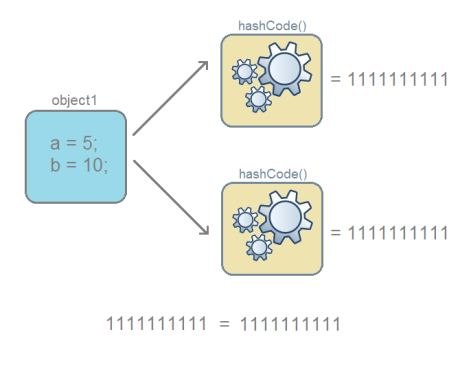
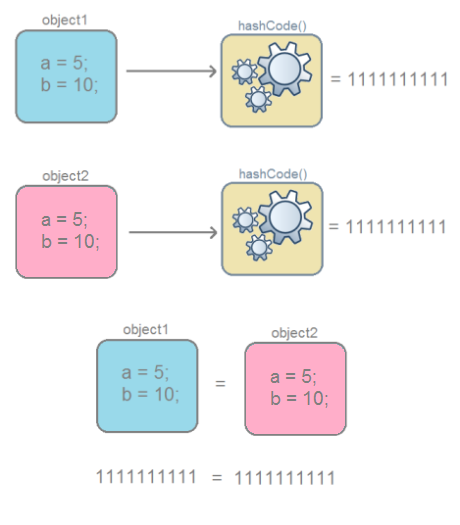
Одинаковые объекты — это объекты одного класса с одинаковым содержимым полей.
-
Для одного и того-же объекта, хеш-код всегда будет одинаковым
-
Если объекты одинаковые, то и хеш-коды будут одинаковые, но не наоборот.
-
Если хеш-коды равны, то входные объекты не всегда равны (коллизия).
-
Если хеш-коды разные, то и объекты гарантированно будут разные.
3.2. Понятие эквивалентности. Метод equals()
В java, каждый вызов оператора new порождает новый объект в памяти. Для иллюстрации создадим какой-нибудь класс, пускай он будет называться BlackBox.
Выполним следующий код:
public class BlackBox {
int varA;
int varB;
BlackBox(int varA, int varB){
this.varA = varA;
this.varB = varB;
}
}Создадим класс для демонстрации BlackBox.
public class DemoBlackBox {
public static void main(String[] args) {
BlackBox object1 = new BlackBox(5, 10);
BlackBox object2 = new BlackBox(5, 10);
}
}В этом примере, в памяти создастся два объекта.
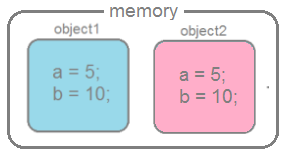
Но, как вы уже обратили внимание, содержимое этих объектов одинаково, то есть эквивалентно. Для проверки эквивалентности в классе Object существует метод equals(), который сравнивает содержимое объектов и выводит значение типа boolean true, если содержимое эквивалентно, и false — если нет.
object1.equals(object2); // должно быть true, поскольку содержимое объектов эквивалентноЭквивалентность и хеш-код тесно связанны между собой, поскольку хеш-код вычисляется на основании содержимого объекта (значения полей) и если у двух объектов одного и того же класса содержимое одинаковое, то и хеш-коды должны быть одинаковые.
Иными словами:
object1.equals(object2); // должно быть true
object1.hashCode() == object2.hashCode(); // должно быть true"Должно быть", потому что если вы выполните предыдущий пример, то на самом деле результатом выполнения всех операций будет false. Для пояснения причин, заглянем в исходные коды класса Object.
3.2.1. Пример
Метод equals() сравнивает два объекта на равенство:
public class Program {
public static void main(String[] args) {
Person tom = new Person("Tom");
Person bob = new Person("Bob");
System.out.println(tom.equals(bob)); // false
Person tom2 = new Person("Tom");
System.out.println(tom.equals(tom2)); // true
}
}class Person {
private String name;
public Person(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Person) {
Person p = (Person) obj;
return (this.name == p.name);
}
return false;
}
}Метод equals() принимает в качестве параметр объект любого типа, который мы затем приводим к текущему, если они являются объектами одного класса.
Оператор instanceof позволяет выяснить, является ли переданный в качестве параметра объект объектом определенного класса, в данном случае класса Person.
Затем сравниваем по именам. Если они совпадают, возвращаем true, что будет говорить, что объекты равны.
Если объекты принадлежат к разным классам, то их сравнение не имеет смысла, и возвращается значение false.
3.3. Класс Object
Как известно, все java-классы наследуются от класса Object. В этом классе уже определены методы hashCode() и equals().
Определяя свой класс, вы автоматически наследуете все методы класса Object. И в ситуации, когда в вашем классе не переопределены (overriding) hashCode() и equals(), то используется их реализация из Object.
Рассмотрим исходный код метода equals() в классе Object.
public boolean equals(Object obj) {
return (this == obj);
}При сравнении объектов, операция == вернет true лишь в одном случае — когда ссылки указывают на один и тот-же объект. В данном случае не учитывается содержимое полей.
Выполнив приведённый ниже код, equals() вернет true.
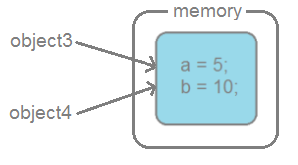
public class DemoBlackBox {
public static void main(String[] args) {
BlackBox object3 = new BlackBox(5, 10);
BlackBox object4 = object3; // Переменная object4 ссылается на
// тот-же объект что и переменная object3
object3.equals(object4); // true
}
}Теперь понято, почему Object.equals() работает не так как нужно, ведь он сравнивает ссылки, а не содержимое объектов.
Далее на очереди hashCode(), который тоже работает не так как полагается.
Заглянем в исходный код метода hashCode() в классе Object:
public native int hashCode();Вот собственно и вся реализация. Ключевое слово native означает, что реализация данного метода выполнена на другом языке, например на C, C или *ассемблере*. Конкретный `native int hashCode()` реализован на C, вот исходники функции get_next_hash.
При вычислении хэш-кода для объектов класса Object по умолчанию используется Park-Miller RNG алгоритм. В основу работы данного алгоритма положен генератор случайных чисел. Это означает, что при каждом запуске программы у объекта будет разный хэш-код.
Получается, что используя реализацию метода hashCode() от класса Object, мы при каждом создании объекта класса new BlackBox(), будем получать разные хеш-коды. Мало того, перезапуская программу, мы будем получать абсолютно разные значения, поскольку это просто случайное число.
Но, как мы помним, должно выполняться правило: если у двух объектов одного и того же класса содержимое одинаковое, то и хеш-коды должны быть одинаковые. Поэтому, при создании пользовательского класса, принято переопределять методы hashCode() и equals() таким образом, что бы учитывались поля объекта.
Это можно сделать вручную либо воспользовавшись средствами генерации исходного кода в IDE. Например, в Eclipse это Source → Generate hashCode() and equals()…
В итоге класс BlackBox приобретает вид:
public class BlackBox {
int varA;
int varB;
BlackBox(int varA, int varB) {
this.varA = varA;
this.varB = varB;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + varA;
result = prime * result + varB;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
BlackBox other = (BlackBox) obj;
if (varA != other.varA)
return false;
if (varB != other.varB)
return false;
return true;
}
}Теперь методы hashCode() и equals() работают корректно и учитывают содержимое полей объекта:
object1.equals(object2); // true
object1.hashCode() == object2.hashCode(); // trueПоэтому создавая пользовательский класс, нужно переопределять методы hashCode() и equals(), чтобы они корректно работали и учитывали данные объекта. Кроме того, если оставить реализацию из Object, то при использовании java.util.HashMap возникнут проблемы, поскольку HashMap активно используют hashCode() и equals() в своей работе.
3.4. toString()
Метод toString() служит для получения представления данного объекта в виде строки. При попытке вывести строковое представления какого-нибудь объекта, как правило, будет выводиться полное имя класса. Например:
public class Program {
public static void main(String[] args) {
Person tom = new Person("Tom");
System.out.println(tom.toString()); // Будет выводить что-то наподобие Person@7960847b
}
}class Person {
private String name;
public Person(String name) {
this.name = name;
}
}Полученное мной значение (в данном случае Person@7960847b) вряд ли может служить хорошим строковым описанием объекта. Поэтому метод toString() нередко переопределяют. Например:
public class Program {
public static void main(String[] args) {
Person tom = new Person("Tom");
System.out.println(tom.toString()); // Person Tom
}
}
class Person {
private String name;
public Person(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person " + name;
}
}3.5. getClass()
Метод getClass() позволяет получить тип данного объекта:
Person tom = new Person("Tom");
System.out.println(tom.getClass()); // class Person4. Enums
Кроме отдельных примитивных типов данных и классов в Java есть такой тип как enum (перечисление). Enum - это языковая конструкция, которая используется для определения типобезопасных перечислений. Эти перечисления которые можно использовать, когда требуется фиксированный набор именованных значений. Все enums неявно расширяют java.lang.Enum. Enums могут содержать одну или несколько enum constants, которые определяют уникальные экземпляры enum type. При объявлении перечисления определяется enum type, который очень похож на класс тем, что он может иметь такие члены, как поля, методы и конструкторы (с некоторыми ограничениями).
Объявление перечисления происходит с помощью ключевого слова enum, после которого идет название перечисления. Затем идет список констант перечисления через запятую:
enum Day {
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY
}Перечисление фактически представляет новый тип, поэтому мы можем определить переменную данного типа и использовать ее.
public class Program {
public static void main(String[] args) {
Day current = Day.MONDAY;
System.out.println(current);
}
}MONDAY
Перечисления могут использоваться в классах для хранения данных:
enum Type {
SCIENCE,
BELLES_LETTRES,
PHANTASY,
SCIENCE_FICTION
}class Book {
String name;
Type bookType;
String author;
Book(String name, String author, Type type) {
bookType = type;
this.name = name;
this.author = author;
}
}public class Program {
public static void main(String[] args) {
Book b1 = new Book("War and Peace", "L. Tolstoy", Type.BELLES_LETTRES);
System.out.printf("Book '%s' has a type %s", b1.name, b1.bookType);
switch (b1.bookType) {
case BELLES_LETTRES:
System.out.println("Belles-lettres");
break;
case SCIENCE:
System.out.println("Science");
break;
case SCIENCE_FICTION:
System.out.println("Science fiction");
break;
case PHANTASY:
System.out.println("Phantasy");
break;
}
}
}Belles-lettres
Само перечисление объявлено вне класса, оно содержит четыре жанра книг. Класс Book кроме обычных переменных содержит также переменную типа нашего перечисления. В конструкторе мы ее также можем присвоить, как и обычные поля класса.
С помощью конструкции switch…case можно проверить принадлежность значения bookType определенной константе перечисления.
4.1. Методы перечислений
Каждое перечисление имеет статический метод values(). Он возвращает массив всех констант перечисления:
enum Type {
SCIENCE,
BELLES_LETTRES,
PHANTASY,
SCIENCE_FICTION
}public class Program {
public static void main(String[] args) {
Type[] types = Type.values();
for (Type s : types) {
System.out.println(s);
}
}
}Метод ordinal() возвращает порядковый номер определенной константы (нумерация начинается с 0):
public class Program {
public static void main(String[] args) {
System.out.println(Type.BELLES_LETTRES.ordinal());
}
}1
4.2. Конструкторы, поля и методы перечисления
Перечисления, как и обычные классы, могут определять конструкторы, поля и методы. Например:
enum Color {
RED("#FF0000"), BLUE("#0000FF"), GREEN("#00FF00");
private String code;
Color(String code) {
this.code = code;
}
public String getCode() {
return code;
}
}public class Program {
public static void main(String[] args) {
System.out.println(Color.RED.getCode());
System.out.println(Color.GREEN.getCode());
}
}#FF0000 #00FF00
Перечисление Color определяет приватное поле code для хранения кода цвета, а с помощью метода getCode() оно возвращается. Через конструктор передается для него значение. Следует отметить, что конструктор по умолчанию приватный, то есть имеет модификатор private. Любой другой модификатор будет считаться ошибкой. Поэтому создать константы перечисления с помощью конструктора мы можем только внутри перечисления.
Также можно определять методы для отдельных констант:
enum Operation {
SUM {
public int action(int x, int y) {
return x + y;
}
},
SUBTRACT {
public int action(int x, int y) {
return x - y;
}
},
MULTIPLY {
public int action(int x, int y) {
return x * y;
}
};
public abstract int action(int x, int y);
}public class Program {
public static void main(String[] args) {
Operation op = Operation.SUM;
System.out.println(op.action(10, 4));
op = Operation.MULTIPLY;
System.out.println(op.action(6, 4));
}
}14 24
5. Wrapper Classes
5.1. Wrapper Classes
Очень часто необходимо создать класс, основное назначение которого содержать в себе какое-то примитивное значение. Например, как мы увидим в следующих занятиях, обобщенные классы и в частности коллекции работают только с объектами. Поэтому, чтобы каждый разработчик не изобретал велосипед, в Java уже добавлены такие классы, которые называются Wrapper Classes (оболочки типов/классы обертки/wrappers).
К оболочкам типов относятся классы Double, Float, Long, Integer, Short, Byte, Character, Boolean, Void.
Для каждого примитивного значения и ключевого слова void есть свой класс-двойник.
Имя класса, как вы видите, совпадает с именем примитивного значения.
Исключения составляют класс Integer (примитивный тип int) и класс Character (примитивный тип char).
Кроме содержания в себе значения, классы оболочки предоставляют обширный ряд методов.
Объекты классов оболочек неизменяемые (immutable). Это значит, что объект не может быть изменен.
Все классы-обертки числовых типов имеют переопределенный метод equals(Object), сравнивающий примитивные значения объектов.
5.1.1. Конструкторы оболочек
В следующей таблицы для каждого класса оболочки указан соответствующий примитивный тип и варианты конструкторов.
| Примитивный тип | Оболочка | Аргументы конструктора |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Как вы видите каждый класс имеет два конструктора, которые принимаю значения типа:
-
соответствующего примитива
-
String
Исключения: класс Character, у которого только один конструктор с аргументом char и класс Float, объявляющий три конструктора - для значения float, String и еще double.
Рассмотрим варианты вызова конструкторов на примере.
Чтобы создать объект класса Integer, передаем в конструктор либо значение типа int либо String.
Integer i1 = new Integer(42);
Integer i2 = new Integer("42");
Float f1 = new Float(3.14f);
Float f2 = new Float("3.14f");
Character c1 = new Character('c');Если передаваемая в конструктор строка не содержит числового значения, то выбросится исключение NumberFormatException.
При вызове конструктора с аргументом String класса Boolean, не обязательно передавать строки true или false.
Если аргумент содержит любую другую строку, просто будет создан объект, содержащий значение false.
Исключение выброшено не будет:
public class WrapperDemo1 {
public static void main(String[] args) {
Boolean boolean1 = new Boolean(true);
Boolean boolean2 = new Boolean("Some String");
System.out.println(boolean2);
}
}5.1.2. Методы классов оболочек
Как уже было сказано, классы оболочки содержат обширный ряд методов. Рассмотрим их.
Методы valueOf()
Метод valueOf() предоставляет второй способ создания объектов оболочек.
Метод перегруженный, для каждого класса существует два варианта - один принимает на вход значение соответствующего типа, а второй - значение типа String.
Так же как и с конструкторами, передаваемая строка должна содержать числовое значение.
Исключение составляет опять же класс Character - в нем объявлен только один метод, принимающий на вход значение char.
И в целочисленные классы Byte, Short, Integer, Long добавлен еще один метод, в который можно передать строку, содержащую число в любой системе исчисления.
Вторым параметром вы указываете саму систему исчисления.
В следующем примере показано использование всех трех вариантов для создания объектов класса Integer:
public class WrapperValueOf {
public static void main(String[] args) {
Integer integer1 = Integer.valueOf("6");
Integer integer2 = Integer.valueOf(6);
// преобразовывает 101011 к 43
Integer integer3 = Integer.valueOf("101011", 2);
System.out.println(integer1);
System.out.println(integer2);
System.out.println(integer3);
}
}Методы parse()
В каждом классе оболочке содержатся методы, позволяющие преобразовывать строку в соответствующее примитивное значение.
В классе Double - это метод parseDouble(), в классе Long - parseLong() и так далее.
Разница с методом valueOf() состоит в том, что метод valueOf() возвращает объект, а parse() - примитивное значение.
Также в целочисленные классы Byte, Short, Integer, Long добавлен метод, в который можно передать строку, содержащую число в любой системе исчисления.
Вторым параметром вы указываете саму систему исчисления.
Следующий пример показывает использование метода parseLong():
public class WrapperDemo3 {
public static void main(String[] args) {
Long long1 = Long.valueOf("45");
long long2 = Long.parseLong("67");
long long3 = Long.parseLong("101010", 2);
System.out.println("long1 = " + long1);
System.out.println("long2 = " + long2);
System.out.println("long3 = " + long3);
}
}Методы toString()
Все типы-оболочки переопределяют toString().
Этот метод возвращает читабельную для человека форму значения, содержащегося в оболочке.
Это позволяет выводить значение, передавая объект оболочки типа методу println():
Double double1 = Double.valueOf("4.6");
System.out.println(double1);Также все числовые оболочки типов предоставляют статический метод toString(), на вход которого передается примитивное значение.
Метод возвращает значение String:
String string1 = Double.toString(3.14);Integer и Long предоставляют третий вариант toString() метода, позволяющий представить число в любой системе исчисления.
Он статический, первый аргумент – примитивный тип, второй - основание системы счисления:
String string2 = Long.toString(254, 16); // string2 = "fe"Методы toHexString(), toOctalString(), toBinaryString()
Integer и Long позволяют преобразовывать числа из десятичной системы исчисления к шестнадцатеричной, восьмеричной и двоичной.
Например:
public class WrapperToXString {
public static void main(String[] args) {
String string1 = Integer.toHexString(254);
System.out.println("254 в 16-ой системе = " + string1);
String string2 = Long.toOctalString(254);
System.out.println("254 в 8-ой системе = " + string2);
String string3 = Long.toBinaryString(254);
System.out.println("254 в 2-ой системе = " + string3);
}
}В классы Double и Float добавлен только метод toHexString().
5.1.3. Класс Number
Все оболочки числовых типов наследуют абстрактный класс Number. Number объявляет методы, которые возвращают значение объекта в каждом из различных числовых форматов.
Пример приведения типов
public class WrapperDemo2 {
public static void main(String[] args) {
Integer iOb = new Integer(1000);
System.out.println(iOb.byteValue());
System.out.println(iOb.shortValue());
System.out.println(iOb.intValue());
System.out.println(iOb.longValue());
System.out.println(iOb.floatValue());
System.out.println(iOb.doubleValue());
}
}5.1.4. Статические константы классов оболочек
Каждый класс оболочка содержит статические константы, содержащие максимальное и минимальное значения для данного типа.
Например в классе Integer есть константы Integer.MIN_VALUE – минимальное int значение и Integer.MAX_VALUE – максимальное int значение.
Классы-обертки числовых типов Float и Double, помимо описанного для целочисленных примитивных типов, дополнительно содержат определения следующих констант:
-
NEGATIVE_INFINITY– отрицательная бесконечность -
POSITIVE_INFINITY– положительная бесконечность -
NaN– не числовое значение (расшифровывается как Not a Number)
Следующий пример демонстрирует использование трех последних переменных.
При делении на ноль возникает ошибка - на ноль делить нельзя.
Чтобы этого не происходило, и ввели переменные NEGATIVE_INFINITY и POSITIVE_INFINITY.
Результат умножения бесконечности на ноль - это значение NaN:
public class InfinityDemo {
public static void main(String[] args) {
int a = 7;
double b = 0.0;
double c = -0.0;
double g = Double.NEGATIVE_INFINITY;
System.out.println("7 / 0.0 = " + a / b);
System.out.println("7 / -0.0 = " + a / c);
System.out.println("0.0 == -0.0 = " + (b == c));
System.out.println("-Infinity * 0 = " + g * 0);
}
}Результат выполнения кода:
7 / 0.0 = Infinity
7 / -0.0 = -Infinity
0.0 == -0.0 = true
-Infinity * 0 = NaN5.2. Autoboxing and unboxing
Autoboxing and unboxing (авто-упаковка и распаковка) — это процесс преобразования примитивных типов в объектные и наоборот. Весь процесс выполняется автоматически средой выполнения Java (JRE). Эта возможность доступна в Java версии 5 и выше.
public class AutoBoxDemo1 {
public static void main(String[] args) {
Integer iOb = 100; // упаковать значение int
int i = iOb; // распаковать
System.out.println(i + " " + iOb);
}
}Autoboxing происходит при прямом присвоении примитива классу-обертке (с помощью оператора =), либо при передаче примитива в параметры метода.
Unboxing происходит при прямом присвоении классу-обертке примитива.
Компилятор использует метод valueOf() для упаковки, а методы intValue(), doubleValue() и так далее, для распаковки.
Autoboxing в классы-обертки могут быть подвергнуты как переменные примитивных типов, так и литералы:
Integer iOb1 = 100;
int i = 200;
Integer iOb2 = i;Autoboxing переменных примитивных типов требует точного соответствия типа исходного примитива — типу класса-обертки.
Например, попытка autoboxing переменную типа byte в Short, без предварительного явного приведения byte в short вызовет ошибку компиляции:
byte b = 4;
// Short s1 = b;
Short s2 = (short) b;Автоупаковку можно использовать при вызове метода:
public class AutoBoxAndMethods {
static int someMethod(Integer value) {
return value;
}
public static void main(String[] args) {
Integer iOb = someMethod(100);
System.out.println(iOb);
}
}Внутри выражения числовой объект автоматически распаковывается. Выходной результат выражения при необходимости упаковывается заново:
public class AutoBoxAndOperations {
public static void main(String[] args) {
Integer iOb1, iOb2;
int i;
iOb1 = 100;
iOb2 = iOb1 + iOb1 / 3;
System.out.println("iOb2 после выражения: " + iOb2);
i = iOb1 + iOb1 / 3;
System.out.println("i после выражения: " + i);
}
}C появлением autoboxing/unboxing стало возможным применять объекты Boolean для управления в операторе if и других циклических конструкциях Java:
public class AutoBoxAndCharacters {
public static void main(String[] args) {
Boolean b = true;
if (b) {
System.out.println("В if тоже можно использовать распаковку.");
}
Character ch = 'x';
char ch2 = ch;
System.out.println("ch2 = " + ch2);
}
}До Java 5 работа с классами обертками была более трудоемкой:
public class AutoBoxDemo2 {
public static void main(String[] args) {
Integer y = new Integer(567);
int x = y.intValue();
x++;
y = new Integer(x);
System.out.println("y = " + y);
}
}Перепишет тот же пример для работы с классами начиная с Java 5:
public class AutoBoxDemo3 {
public static void main(String[] args) {
Integer y = new Integer(567);
y++;
System.out.println("y = " + y);
}
}5.2.1. Объекты классов оболочек неизменяемые
Объекты классов оболочек неизменяемые (immutable):
public class AutoBoxImmutability {
public static void main(String[] args) {
Integer y = 567;
Integer x = y;
// проверяем, что x и y указывают на один объект
System.out.println(y == x);
y++;
System.out.println(x + " " + y);
// проверяем, что x и y указывают на один объект
System.out.println(y == x);
}
}Рассмотрим следующий пример:
Integer y = 567;Переменная y указывает на объект в памяти:
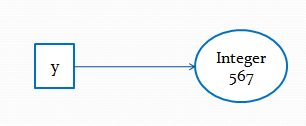
Если мы попытаемся изменить y, у нас создастся еще один объект в памяти, на который теперь и будет указывать y:
Integer y = 567;
y++;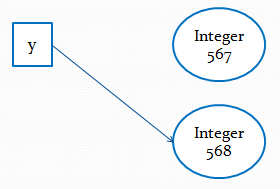
5.2.2. Кэширование объектов классов оболочек
Метод valueOf() не всегда создает новый объект.
Он кэширует следующие значения:
-
Boolean, -
Byte, -
Characterот\u0000до\u007f(7fэто127), -
ShortиIntegerот-128до127.
Если передаваемое значение выходит за эти пределы, то новый объект создается, а если нет, то нет.
Если мы пишем new Integer(), то гарантированно создается новый объект.
Рассмотрим это на следующем примере:
public class AutoBoxDemoCaching {
public static void main(String[] args) {
Integer i1 = 23;
Integer i2 = 23;
System.out.println(i1 == i2);
System.out.println(i1.equals(i2));
Integer i3 = 2300;
Integer i4 = 2300;
System.out.println(i3 == i4);
System.out.println(i3.equals(i4));
}
}5.3. Перегрузка с дополнительными факторами
Перегрузка методов усложняется при одновременном использовании следующих факторов:
-
расширение
-
автоупаковка/распаковка
-
аргументы переменной длины
5.3.1. Расширение примитивных типов
При расширение примитивных типов используется наименьший возможный вариант из всех методов.
public class EasyOver {
static void go(int x) {
System.out.print("int ");
}
static void go(long x) {
System.out.print("long ");
}
static void go(double x) {
System.out.print("double ");
}
public static void main(String[] args) {
byte b = 5;
short s = 5;
long l = 5;
float f = 5.0f;
go(b);
go(s);
go(l);
go(f);
}
}5.3.2. Расширение и boxing
Между расширением примитивных типов и boxing всегда выигрывает расширение. Исторически это более старый вид преобразования.
public class AddBoxing {
public static void go(Integer x) {
System.out.println("Integer");
}
public static void go(long x) {
System.out.println("long");
}
public static void main(String[] args) {
int i = 5;
go(i); // какой go() вызовется?
}
}5.3.3. Упаковка и расширение
Можно упаковать, а потом расширить.
Значение типа int может стать Object, через преобразование Integer.
public class BoxAndWiden {
public static void go(Object o) {
Byte b2 = (Byte) o;
System.out.println(b2);
}
public static void main(String[] args) {
byte b = 5;
go(b); // можно ли преобразовать byte в Object?
}
}5.3.4. Расширение и упаковка
Нельзя расширить и упаковать.
Значение типа byte не может стать Long.
Нельзя расширить от одного класса обертки к другой.
(IS-A не работает.)
public class WidenAndBox {
static void go(Long x) {
System.out.println("Long");
}
public static void main(String[] args) {
byte b = 5;
// go(b); // нужно расширить до long и упаковать, что невозможно
}
}5.3.5. Расширение и аргументы переменной длины
Между расширением примитивных типов и var-args всегда проигрывает var-args:
public class AddVarargs { public static void go(int x, int y) { System.out.println("int,int"); }
public static void go(byte... x) {
System.out.println("byte... ");
}
public static void main(String[] args) {
byte b = 5;
go(b, b); // какой go() вызовется?
}
}
5.3.6. Упаковка и аргументы переменной длины
Упаковка и var-args совместимы с перегрузкой методов. Var-args всегда проигрывает:
public class BoxOrVararg {
public static void go(Byte x, Byte y) {
System.out.println("Byte, Byte");
}
public static void go(byte... x) {
System.out.println("byte... ");
}
public static void main(String[] args) {
byte b = 5;
go(b, b); // какой go() вызовется?
}
}5.3.7. Правила перегрузки методов при использовании расширения, упаковки и аргументов переменной длины
Подытожим все правила:
-
При расширение примитивных типов используется наименьший возможный вариант из всех методов.
-
Между расширением примитивных типов и упаковкой всегда выигрывает расширение. Исторически это более старый вид преобразования.
-
Можно упаковать, а потом расширить. (Значение типа
intможет статьObject, через преобразованиеInteger.) -
Нельзя расширить и упаковать. Значение типа
byteне может статьLong. Нельзя расширить от одного класса обертки к другой. (IS-A не работает.) -
Можно комбинировать var-args с расширением или упаковкой. var-args всегда проигрывает.
6. Javadoc
6.1. Введение
Javadoc является стандартным выводом для Java API. Создание Javadoc довольно простое. Javadoc генерируется с помощью так называемого doclet. Doclet — программы работающие со средством Javadoc для генерации документации по исходному коду написанному на Java. Различные doclets могут по-разному анализировать теги Java и создавать разные выходные данные. Но по большому счету почти каждая документация по Java использует стандартный doclet. Выходные данные Javadoc знакомы разработчикам Java и приветствуются ими.
Javadoc поддерживается Oracle. Разработчики могут интегрировать вывод Javadoc непосредственно в свою IDE, что делает документацию удобной и легко доступной. Фактически, Javadoc часто доставляется таким образом, а не разворачивается и загружается на сервер. Javadoc содержит только справочную документацию. В документацию нельзя добавлять какие-либо концептуальные файлы справки или изменять макет.
6.1.1. Javadoc и проверка ошибок
Javadoc можно генерировать вручную с помощью IDE.
Javadoc также проверяет теги по фактическому коду. Если есть параметры, исключения или return, которые не соответствуют параметрам, исключениям или return в фактическом коде, то Javadoc будет показывать предупреждения.
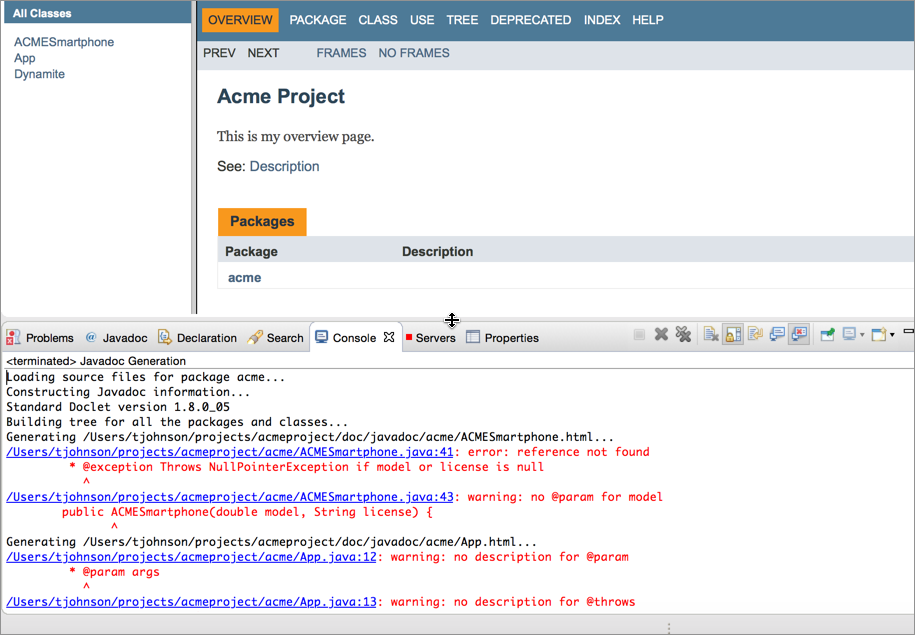
6.1.2. Изучение параметров Javadoc
Можно попробовать удалять некоторые параметры из метода и снова генерировать Javadoc. Перед этим нужно убедиться, что окно консоли открыто, чтобы можно было видеть предупреждения об ошибках.
6.1.3. Автоматическое создание Javadoc
В большинстве проектов файл Javadoc никогда не создается вручную. Javadoc позволяет строить его из командной строки, передавая ему файл конфигурации. У большинства разработчиков есть инструмент управления сборкой, где они могут настраивать выходные данные из своего кода, включая Javadoc. Если разработчики попросят собрать Javadoc, скорее всего, их система управления сборкой может быть несколько примитивной. Тем не менее, может быть полезно создать выходные данные Javadoc самостоятельно, чтобы протестировать и просмотреть выходные данные, прежде чем создавать их с помощью инструмента управления сборкой.
6.2. Теги Javadoc
Javadoc - это генератор документов, который просматривает исходные файлы Java для конкретных тегов. Он анализирует теги в выводе Javadoc. Знать теги очень важно, потому что именно так создается Javadoc.
6.2.1. Комментарии или теги Javadoc
Обычно комментарии в Java выглядят так:
// sample comment...
/*
sample comment
*/Javadoc ничего не делает с такими комментариями.
Чтобы включить контент в Javadoc, добавляем две звездочки в начале, перед классом или методом:
/**
*
*
*
*
*/Формат для добавления различных элементов выглядит следующим образом:
/**
* [short description]
* <p>
* [long description]
*
* [author, version, params, returns, throws, see, other tags]
* [see also]
*/Реальный пример комментариев метода в Javadoc:
/**
* Zaps the roadrunner with the number of volts you specify.
* <p>
* Do not exceed more than 30 volts or the zap function will backfire.
* For another way to kill a roadrunner, see the {@link Dynamite#blowDynamite()} method.
*
* @exception IOException if you don't enter a data type amount for the voltage
* @param voltage the number of volts you want to send into the roadrunner's body
* @see #findRoadRunner
* @see Dynamite#blowDynamite
*/
public void zapRoadRunner(int voltage) throws IOException {
if (voltage < 31) {
System.out.println("Zapping roadrunner with " + voltage + " volts!!!!");
} else {
System.out.println("Backfire!!! zapping coyote with 1,000,000 volts!!!!");
}
}Описание Javadoc и теги помещаем перед классом или методом (нет необходимости в пробелах между описанием и классом или методом).
6.2.2. Общие теги Javadoc
Ниже приведены наиболее распространенные теги, используемые в Javadoc. У каждого тега есть слово, которое следует за ним. Например, @param latitude означает, что параметром является «широта».
Рассмотрим несколько общих тегов Javadoc:
-
@author- человек, который внес значительный вклад в код. Применяется только на уровне класса, пакета или обзора. Не включен в вывод Javadoc. Не рекомендуется включать этот тег, поскольку авторство часто меняется. -
@param- параметр, который принимает метод или конструктор. -
@deprecated- этим тегом помечаются класс или метод, которые больше не используются. Такой тег будет размещен на видном месте в Javadoc. Сопровождается тегом@seeили{@link}. -
@return- что возвращает метод. -
@see- создает список "см. также". Используется в паре с тегом{@link}для связи с содержимым. -
{@link}- используется для создания ссылок на другие классы или методы. Пример:{@link Foo# bar}ссылается на методbar, который принадлежит классуFoo. Для ссылки на метод в том же классе, просто добавляется#bar. -
@since 2.0- версия с момента добавления функции. -
@throws- вид исключения, которое выдает метод. Обратим внимание, что для проверки этого тега в коде должно быть указано исключение. В противном случае Javadoc выдаст ошибку. Тэг@exceptionявляется альтернативным тегом.
6.2.3. К каким элементам добавлять теги Javadoc?
Теги Javadoc добавляют к классам, методам и полям:
-
теги
@authorи@versionдобавляются только к классам и интерфейсам -
тег
@paramтолько для методов и конструкторов -
тег
@returnтолько для методов -
тег
@throwsдля классов и методов
6.2.4. Модификаторы public и private в Javadoc
Javadoc включает классы, методы и т.д., модификатором public. Элементы, помеченные как private, не включаются в Javadoc, если специально не выбран private при создании Javadoc. Если опустить public из исходного кода, по умолчанию класс или метод доступны только для пакета. В этом случае он не будет включен в Javadoc.
6.2.5. Описание
Javadoc предоставляет как краткое, так и длинное описание. Вот пример, показывающий, как отформатирована часть описания:
/**
* Short one line description.
* <p>
* Longer description. If there were any, it would be
* here.
* <p>
* And even more explanations to follow in consecutive
* paragraphs separated by HTML paragraph breaks.
*
* @param variable Description text text text.
* @return Description text text text.
*/
public int methodName (...) {
// method body with a return statement
}Краткое описание является первым предложением с кратким описанием класса или метода в Javadoc. После точки анализатор перемещает остальную часть описания в длинное описание. Для обозначения начала нового абзаца используется HTML-тег <p>. Окружать абзацы открывающими и закрывающими тегами <p> не нужно, потому что компилятор Javadoc автоматически добавляет их. HTML можно использовать в описаниях, таких как неупорядоченный список, кодовые теги, полужирные теги или другие.
После описания вводится пустая строка (для удобства чтения), а затем добавляются теги. Под тегами добавить описание контента невозможно. Только методы и классы могут иметь теги, а не поля. Поля (переменные) имеют только описания.
Предполагается, что это первое предложение является кратким описанием всего класса или метода. Если в одном из ваших слов есть точка (например, Dr. Jones), после точки нужно удалить пробел, добавив Dr. Jones для его соединения.
Лучше избегать использования ссылок в первом предложении. После точки следующее предложение будет длинным абзацем, поэтому нужно загрузить первое предложение, чтобы оно было описательным. Время глаголов должно быть в настоящем времени. Например, получает, помещает, отображает, вычисляет.
Если метод настолько очевиден, например, printPage(), что описание печатает страницу становится избыточным и выглядит бесполезным? В этих случаях Oracle говорит, что можно опустить фразу печатать страницу и вместо этого попытаться предложить другое понимание. Oracle предлагает:
Добавить описание под именем API. Лучшие имена API являются «само документируемыми», то есть они в основном говорят вам, что делает API. Если комментарий к документу просто повторяет имя API в форме предложения, он не предоставляет больше информации. Например, если в описании метода используются только слова, которые встречаются в имени метода, то это вообще ничего не добавляет к тому, что вы могли бы вывести. Идеальный комментарий выходит за рамки этих слов и всегда должен вознаградить вас некоторой информацией, которая не сразу была очевидна из названия API.
https://www.oracle.com/technetwork/articles/java/index-137868.html
6.2.6. Избегаем @author
Используя лучшие практики Javadoc, не рекомендуют использовать @author, потому что значение автора легко теряет актуальность, а системы управления исходным кодом обеспечивает лучшее указание на последнего автора. (См. Javadoc coding standards для подробной информации.)
6.2.7. Порядок тегов
Oracle предлагает следующий порядок тегов:
@author (classes and interfaces)
@version (classes and interfaces)
@param (methods and constructors)
@return (methods)
@throws (@exception is an older synonym)
@see
@since
@serial
@deprecated6.2.8. @param теги
Теги @param применяются только к методам и конструкторам, которые принимают параметры. После тега @param добавляется имя параметра, а затем описание параметра в нижнем регистре без точки, например:
@param url the web address of the siteОписание параметра — это фраза, а не полное предложение. Порядок нескольких тегов @param должен соответствовать их порядку в методе или конструкторе.
Стивен Коулборн рекомендует добавить дополнительный пробел после имени параметра, чтобы повысить удобочитаемость.
Что касается включения типа данных в описание параметра, Oracle говорит:
По соглашению, первым существительным в описании является тип данных параметра. (Артикли «a», «an» и «the» могут предшествовать существительному.) Исключение делается для примитива
int, где тип данных обычно опускается.
https://www.oracle.com/technetwork/java/javase/documentation/index-137868.html#tag
Пример, который дает Oracle, выглядит следующим образом:
@param ch the character to be testedТип данных также виден и из параметров в методе. Поэтому, даже если не включать типы данных, пользователям будет видно, что они собой представляют.
После имени параметра может быть несколько пробелов, чтобы все определения параметров были выстроены в линию.
Теги @param должны быть предоставлены для каждого параметра в методе или конструкторе. Невыполнение этого требования приведет к ошибке и предупреждению при рендеринге Javadoc.
Обычно у классов нет параметров. Есть одно исключение: generics. Параметризованные классы (generics) — это классы, которые работают с различными типами объектов. Объект указывается в качестве параметра в классе в скобках: <>. Хотя руководство Javadoc от Oracle не упоминает их, можно добавить тег @param для универсального класса, чтобы отметить параметры для универсального класса. Детали в посте на StackOverflow. Вот пример с этой страницы:
/**
* @param <T> This describes my type parameter
*/
class MyClass<T> {
}6.2.9. @return теги
Возвращают значения только методы, поэтому только методы получают тег @return. Если метод имеет модификатор void, он ничего не возвращает. Если в нем нет void, нужно включить тег @return, чтобы избежать ошибки при компиляции Javadoc.
6.2.10. @throws теги
Теги @throws добавляются в методы или классы только в том случае, если метод или класс генерируют ошибку определенного типа. Вот пример:
@throws IOException if your input format is invalidСтивен Коулборн рекомендует начинать описание тега throws с предложения «if» для удобства чтения. Он говорит:
За функцией
@throwsобычно следует if … и остальная часть фразы, описывающая условие. Например,@throws, if the file could not be found. Это способствует удобочитаемости исходного кода и при его создании.
Несколько тегов @throws располагают в алфавитном порядке.
6.2.11. Комментарии к конструкторам
Рекомендуется включать конструктор в класс. Однако, если конструктор отсутствует, Javadoc автоматически создает конструктор в Javadoc, но исключает любое описание конструктора.
Конструкторы имеют теги @param, но не теги @return. Все остальное так же, как и с методами.
6.2.12. Комментарии к полям
Поля имеют только описания. Можно добавлять комментарии в поле, если бы поле было чем-то, что пользователь будет использовать.
6.2.13. Кейсы, где комментарии не нужны
Oracle говорит, что есть три сценария, где комментарии к документу наследуются, поэтому вам не нужно включать комментарии в эти сценарии:
-
когда метод в классе переопределяет метод в суперклассе;
-
когда метод в интерфейсе переопределяет метод в суперинтерфейсе;
-
когда метод в классе реализует метод в интерфейсе
6.2.14. @see теги
Тэг @see предоставляет ссылку. Существуют различные способы обозначить то, на что надо ссылаться, чтобы создать ссылку. При ссылке на поле, конструктор или метод в том же поле, используется #.
При ссылке на другой класс, сначала пишется имя этого класса, затем # и имя конструктора, метода или поля.
При ссылке на класс в другом пакете, сначала указывается имя пакета, затем класс и так далее. Пример из Oracle:
@see #field
@see #Constructor(Type, Type...)
@see #Constructor(Type id, Type id...)
@see #method(Type, Type,...)
@see #method(Type id, Type, id...)
@see Class
@see Class#field
@see Class#Constructor(Type, Type...)
@see Class#Constructor(Type id, Type id)
@see Class#method(Type, Type,...)
@see Class#method(Type id, Type id,...)
@see package.Class
@see package.Class#field
@see package.Class#Constructor(Type, Type...)
@see package.Class#Constructor(Type id, Type id)
@see package.Class#method(Type, Type,...)
@see package.Class#method(Type id, Type, id)Для подробной информации см. How to write Javadoc comments
6.2.15. Ссылки
Создавать ссылки на другие классы и методы можно используя тег {@link}.
Пример создания ссылки из Javadoc coding standards:
/**
* First paragraph.
* <p>
* Link to a class named 'Foo': {@link Foo}.
* Link to a method 'bar' on a class named 'Foo': {@link Foo#bar}.
* Link to a method 'baz' on this class: {@link #baz}.
* Link specifying text of the hyperlink after a space: {@link Foo the Foo class}.
* Link to a method handling method overload {@link Foo#bar(String,int)}.
*/
public ...Для ссылки на другой метод в том же классе используется формат: {@link #baz}. Чтобы связать метод с другим классом, используется формат: {@link Foo # baz}. Но не следует мудрить с гиперссылкой. При обращении к другим классам можно использовать теги <code>.
Для изменения связанного текста, после слова #baz пишется: @see #baz Baz Method.
6.2.16. Предпросмотр комментариев Javadoc
Во многих IDE присутствует вкладка Javadoc, которую можно использовать для просмотра информации Javadoc, включенную для просматриваемого класса.
6.2.17. Зачем такие подробности о тегах Javadoc?
Для чего здесь добавлено много конкретных деталей и рекомендаций по стилю тегов Javadoc? Для понимания того, что теги для Javadoc следуют множеству стилевых соглашений и лучших практик. Эти соглашения и рекомендации не всегда могут быть очевидны или соблюдаются в файлах Java, с которыми приходится работать. Можно добавить большую ценность, просто убедившись, что содержимое соответствует таким стилевым соглашениям.
6.3. Отображение Javadoc
Выходные данные Javadoc не сильно изменились за последние 20 лет, поэтому в некотором смысле они предсказуемы и знакомы. С другой стороны, выходные данные устарели и в них отсутствуют некоторые важные функции, такие как поиск или возможность добавления дополнительных страниц. Как же организован Javadoc?
6.3.1. Резюме класса
Открываем файл `index.html`в директории с Javadoc, которую сгенерировали.
Вкладка Резюме класса показывает краткую версию каждого из классов. Описание, которое писали для каждого класса, отображается здесь. Это своего рода краткое справочное руководство по API.
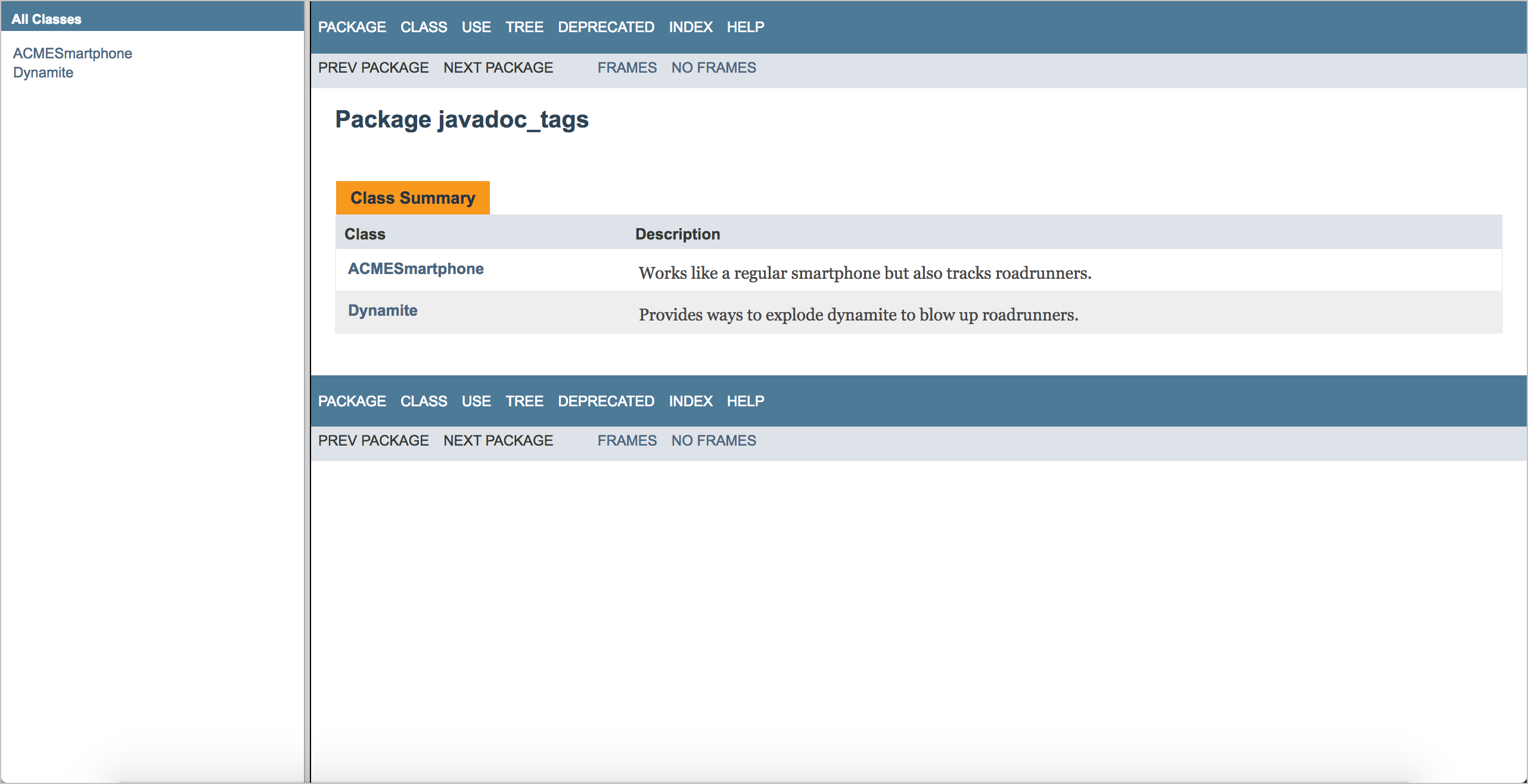
Для отображения деталей класса кликаем по его имени (в нашем примере это ACMESmartphone или Dynamite)
6.3.2. Детали класса
При просмотре страницы класса, мы получаем сводку полей, конструкторов и методов для класса. Опять же, это просто обзор. Если прокрутить вниз, то увидим полную информацию о каждом из этих элементов.
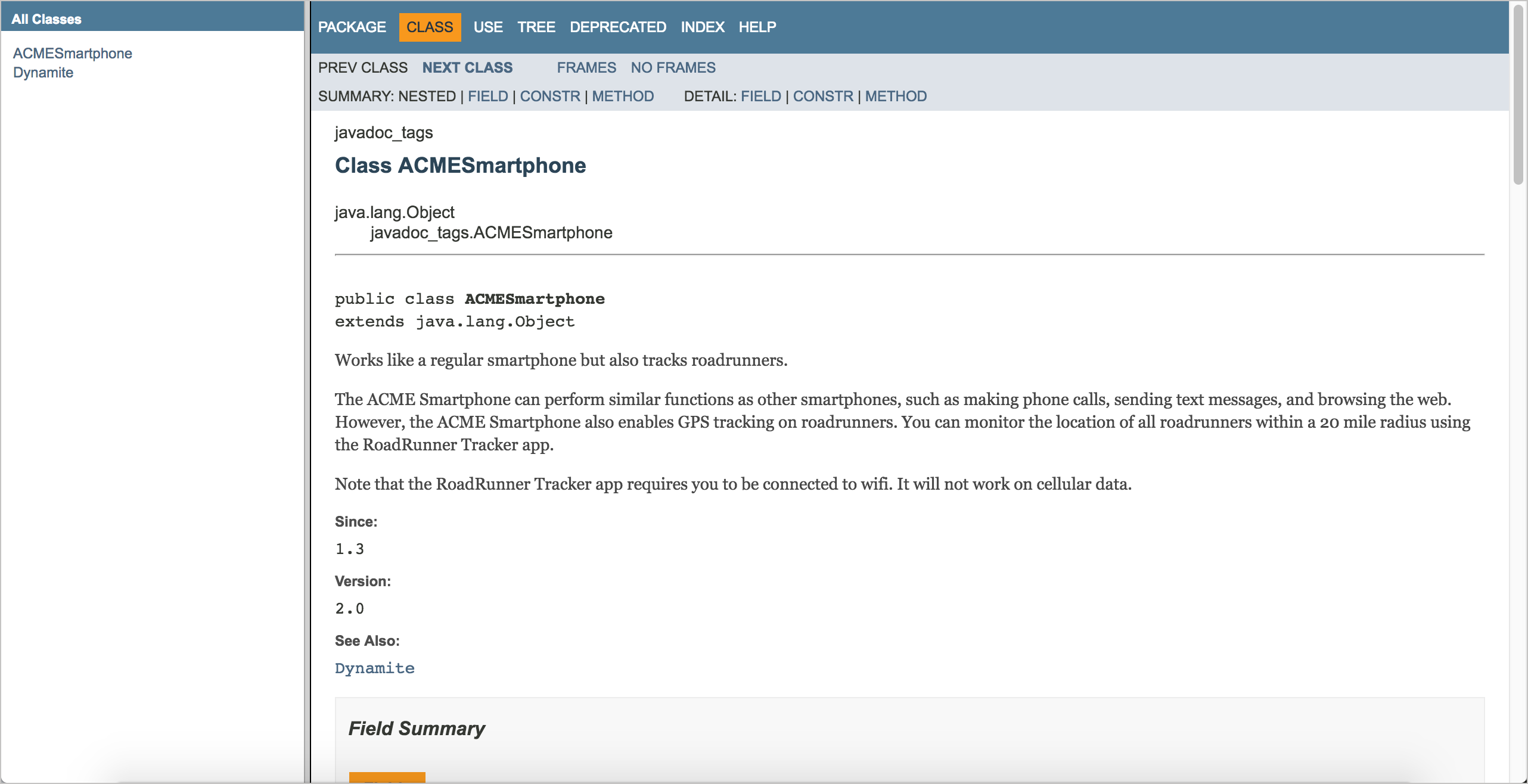
6.3.3. Другая навигация
Если кликнуть на вкладку Package вверху, можно просмотреть классы по пакетам. Или можно перейти к классу, щелкнув имя класса в левом столбце. Также можно просмотреть все, кликнув Index.
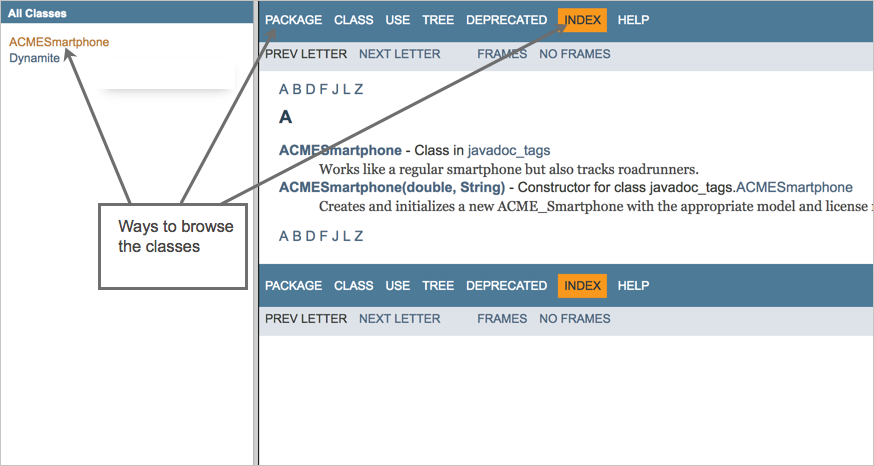
Для получения справки по организации Javadoc нужно кликнуть на вкладку Help вверху на навигационной панели.
6.4. Редактирование тегов Javadoc
Разработчики довольно часто добавляют теги Javadoc и краткие комментарии, когда они создают код Java. Фактически, если они не добавляют некоторые теги, среда IDE обычно выдает предупреждение об ошибке.
Однако комментарии, которые добавляют разработчики, могут быть плохими, неполными или непонятными. Работа технического писателя с Javadoc часто заключается в редактировании уже существующего контента, обеспечивая большую ясность, структуру, вставляя правильные теги и многое другое.
6.4.1. На что обращать внимание при редактировании Javadoc
При редактировании Javadoc обращаем внимание на:
-
отсутствие документации (большая часть Javadoc неполная, нужно искать недостающую документацию)
-
последовательный стиль (соответствуют ли существующие теги соглашениям стиля Java с тегами)
-
ясность (некоторые описания неразборчивы из-за проклятия знаний, и без хорошего понимания Java может быть трудно разобраться в них)
6.4.2. Редактируем Javadoc
Сделаем несколько изменений в классе и методе. Затем заново сгенерируем Javadoc и посмотрим на изменения, как они отображаются на выходе.
7. Ссылочные типы и клонирование объектов
При работе с объектами классов надо учитывать, что они все представляют ссылочные типы, то есть указывают на какой-то объект, расположенный в памяти. Чтобы понять возможные трудности, с которыми мы можем столкнуться, рассмотрим пример:
public class Program {
public static void main(String[] args) {
Person tom = new Person("Tom", 23);
tom.display(); // Person Tom
Person bob = tom;
bob.setName("Bob");
tom.display(); // Person Bob
}
}
class Person {
private String name;
private int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
void setName(String name) {
this.name = name;
}
void setAge(int age) {
this.age = age;
}
void display() {
System.out.printf("Person Name: %s \n", name);
}
}Здесь создаем два объекта Person и один присваиваем другому. Но, несмотря на то, что мы изменяем только объект bob, вместе с ним изменяется и объект tom. Потому что после присвоения они указывают на одну и ту же область в памяти, где собственно данные об объекте Person и его полях и хранятся.
Чтобы избежать этой проблемы, необходимо создать отдельный объект для переменной bob, например, с помощью метода clone:
class Person implements Cloneable {
private String name;
private int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
void setName(String name) {
this.name = name;
}
void setAge(int age) {
this.age = age;
}
void display() {
System.out.printf("Person %s \n", name);
}
public Person clone() throws CloneNotSupportedException {
return (Person) super.clone();
}
}Для реализации клонирования класс Person должен применить интерфейс Cloneable, который определяет метод clone(). Реализация этого метода просто возвращает вызов метода clone() для родительского класса - то есть класса Object с преобразованием к типу Person.
Кроме того, на случай если класс не поддерживает клонирование, метод должен выбрасывать исключение CloneNotSupportedException, что определяется с помощью оператора throws.
Затем с помощью вызова этого метода мы можем осуществить копирование:
try {
Person tom = new Person("Tom", 23);
Person bob = tom.clone();
bob.setName("Bob");
tom.display(); // Person Tom
} catch (CloneNotSupportedException ex) {
System.out.println("Clonable not implemented");
}Однако данный способ осуществляет неполное копирование и подойдет, если клонируемый объект не содержит сложных объектов. Например, пусть класс Book имеет следующее определение:
class Book implements Cloneable {
private String name;
private Author author;
public void setName(String n) {
name = n;
}
public String getName() {
return name;
}
public void setAuthor(String n) {
author.setName(n);
}
public String getAuthor() {
return author.getName();
}
Book(String name, String author) {
this.name = name;
this.author = new Author(author);
}
public String toString() {
return "Книга '" + name + "' (автор " + author + ")";
}
public Book clone() throws CloneNotSupportedException {
return (Book) super.clone();
}
}
class Author {
private String name;
public void setName(String n) {
name = n;
}
public String getName() {
return name;
}
public Author(String name) {
this.name = name;
}
}Если мы попробуем изменить автора книги, нас последует неудача:
try {
Book book = new Book("War and Peace", "Leo Tolstoy");
Book book2 = book.clone();
book2.setAuthor("Ivan Turgenev");
System.out.println(book.getAuthor());
} catch (CloneNotSupportedException ex) {
System.out.println("Cloneable not implemented");
}В этом случае, хотя переменные book и book2 будут указывать на разные объекты в памяти, но эти объекты при этом будут указывать на один объект Author.
И в этом случае нам необходимо выполнить полное копирование. Для этого, во-первых, надо определить метод клонирования у класса Author:
class Author implements Cloneable {
// остальной код класса
public Author clone() throws CloneNotSupportedException {
return (Author) super.clone();
}
}И затем исправим метод clone() в классе Book следующим образом:
public Book clone() throws CloneNotSupportedException {
Book newBook = (Book) super.clone();
newBook.author = (Author) author.clone();
return newBook;
}8. Java Memory Management
8.1. Почему необходимо заботиться об управлении памятью?
Многие разработчики не заботятся об управлении памятью, так как в Java ж е есть Garbage Collection (GC/Сборка мусора). Garbage Collection - это процесс, с помощью которого Java программы выполняют автоматическое управление памятью. По сути, код, который пишется на Java (и других языках для JVM), компилируется в byte-код (файл .class) и запускается на JVM (виртуальной машине Java). Когда приложение работает на JVM, большинство объектов создается в HEAP (Куча). В процессе работы, некоторые объекты больше не понадобятся (недоступные/неиспользуемые объекты). Garbage Collector (Сборщик мусора) освободит неиспользуемую память, чтобы вернуть память для программы, других приложений и операционной системы.
Memory management is the process of allocating new objects and removing unused objects to make space for those new object allocations
В некоторых языках, таких как C, необходимо управлять памятью вручную. Таким образом, написать приложение на C очень сложно. Мы должны тщательно выделять/освобождать переменные и объекты, потому что это может привести к memory leak (утечке памяти).
Проще говоря когда в HEAP выделена память для объекта, он не используется и эта память не может освободиться, в этом случае это memory leak. Memory leak следует избегать, потому что они приводят к падению приложения или заставляют его работать медленно.
Предположим, нам нужно получить метаданные изображения, когда у нас есть URL-адрес этого файла. Для простоты можно использовать файл на локальном компьютере.
Основная программа:
package com.rakovets.jmm.main;
import com.rakovets.jmm.entity.Metadata;
import com.rakovets.jmm.utils.ImageMetadataUtils;
public class ImageMetadataExample {
public static void main(String[] args) {
try {
final String url = "/home/rakovets/pics/2000x2000px_keepcalm.jpg";
for (int i = 0; i < 2000; i ++) {
Metadata metadata = ImageMetadataUtils.getMetadataLocalFile(url);
System.out.println(String.format("Count %d URL: %s, metadata: %s", i, url, metadata.toString()));
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}MetadataUtils класс:
package com.rakovets.jmm.utils;
import java.awt.image.BufferedImage;
import java.io.File;
import java.util.Map;
import java.util.Set;
import javax.imageio.ImageIO;
import com.rakovets.jmm.entity.Metadata;
import lombok.experimental.UtilityClass;
@UtilityClass
public class ImageMetadataUtils {
public static Metadata getMetadataLocalFile(String url) {
try {
final File outputFile = new File(url);
final BufferedImage buf = ImageIO.read(outputFile);
final int width = buf.getWidth();
final int height = buf.getHeight();
final long fileSize = outputFile.length();
return new Metadata(url, width, height, fileSize);
} catch (Exception e) {
e.printStackTrace();
System.out.printf("[ERROR] Get metadata from url %s: %s\n", url, e.getMessage());
return null;
}
}
}Класс Metadata:
package com.rakovets.jmm.entity;
public class Metadata {
private String url;
private Integer width;
private Integer height;
private Long fileSizeInBytes;
public Metadata(String url, Integer width, Integer height, Long fileSizeInBytes) {
this.url = url;
this.width = width;
this.height = height;
this.fileSizeInBytes = fileSizeInBytes;
}
public String toString() {
return new StringBuilder()
.append("Width ").append(width)
.append(", Height: ").append(height)
.append(", Size: ").append(fileSizeInBytes)
.toString();
}
}Есть ли в вышеприведенном коде какие-то проблемы? Как определить что в программе есть проблемы с памятью? Для этого можно использовать специализированные инструменты для мониторинга Java-приложений. Один из которых и будет далее использоваться: JVisualVM.
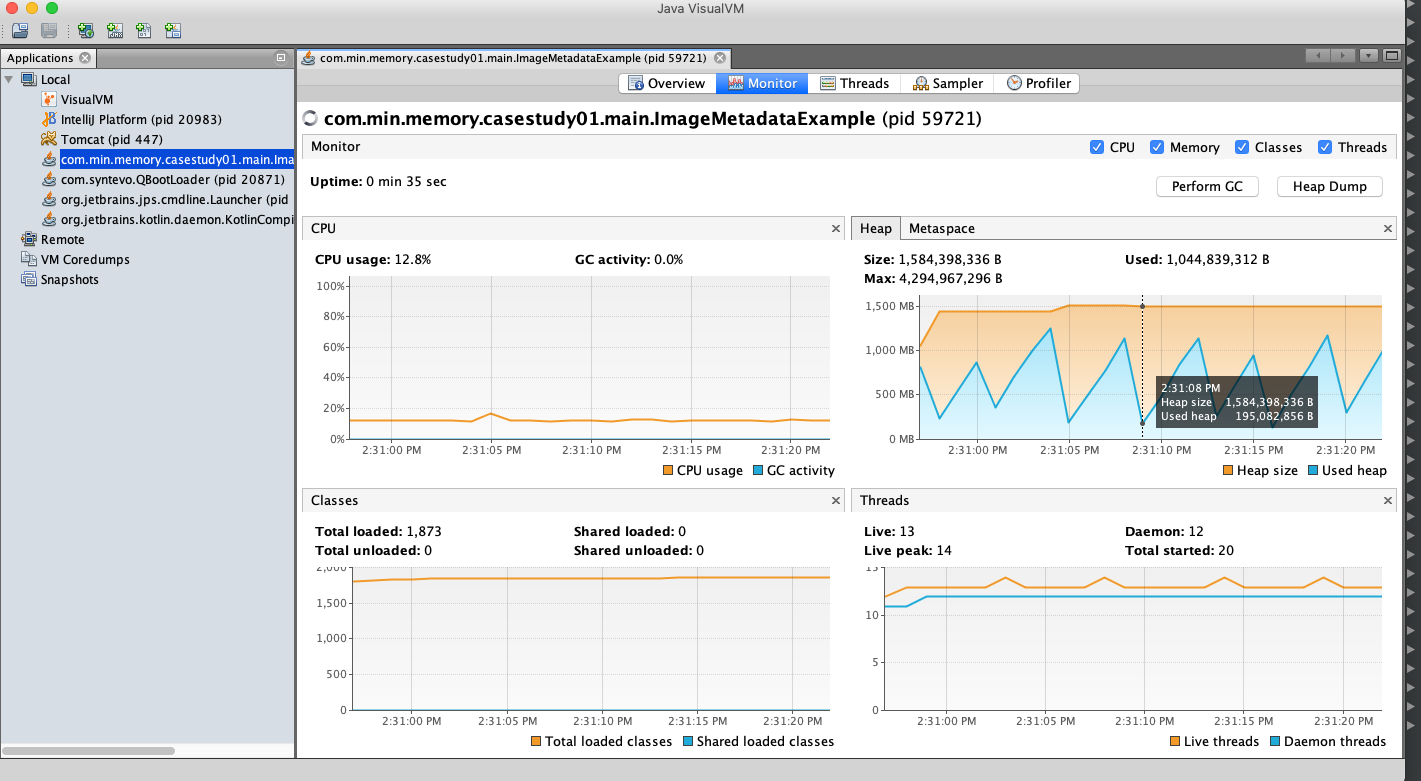
В раздел HEAP можно увидеть что небольшая программа потребляет 1 044 839 312 byte (~ 1Gb) памяти в HEAP.
Почему?
Посмотрим Heap Dump.
BufferImage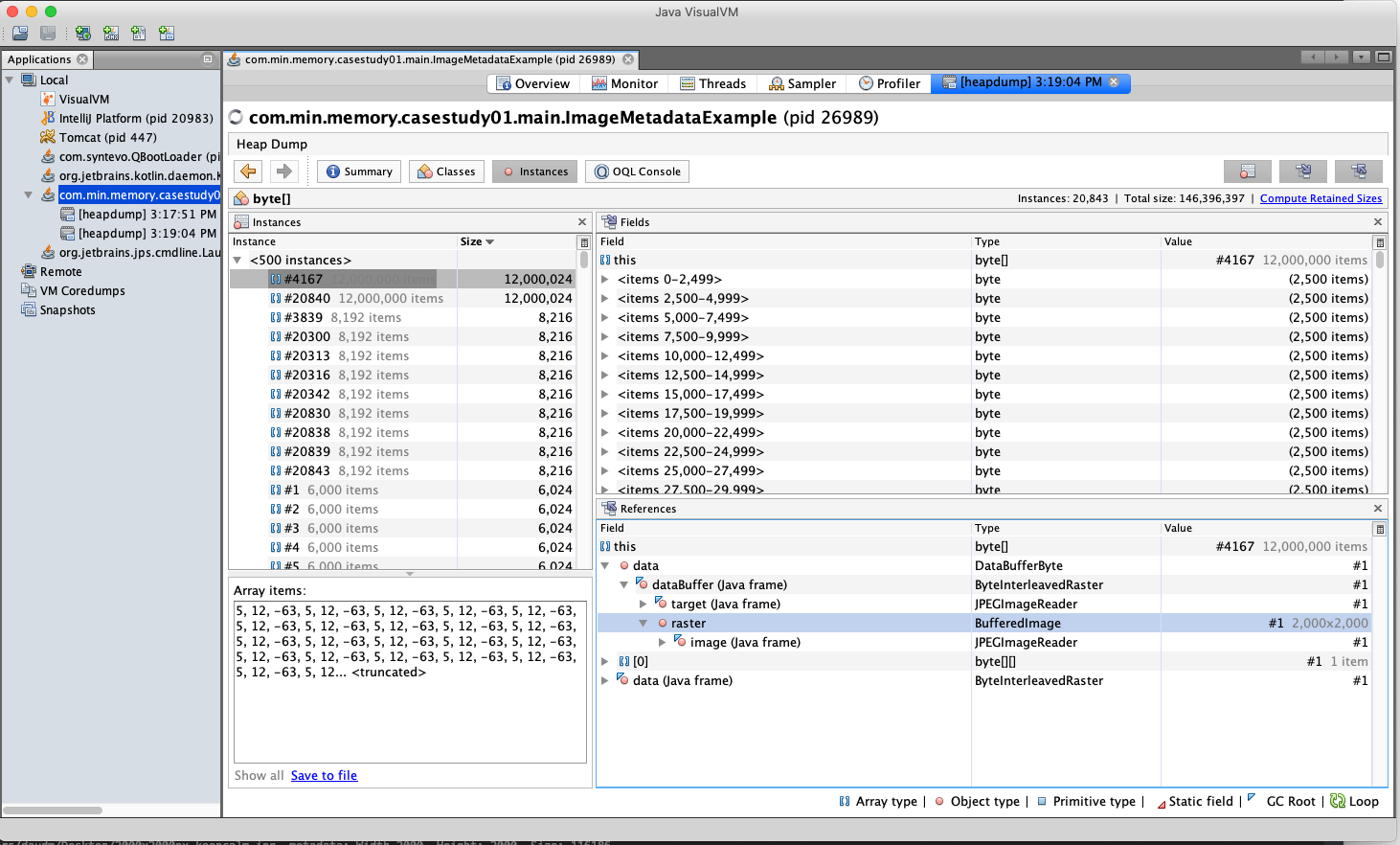
Объект BufferImage очень большой и занимает 12Mb в HEAP. Поскольку один пиксель занимает 3 байта памяти, а используется изображение размером 2000x2000 пикселей (3 * 2000 * 2000 = 12Mb).
Проблема обнаружена, соответственно можно выработать решение для данной проблемы.
Используем класс com.drew.imaging.ImageMetadataReader в библиотеке metadata-extractor для получения метаданных изображения.
Обновленный код для класса ImageMetadataUtils и основной программы будет выглядеть следующим образом:
package com.rakovets.jmm.utils;
import java.awt.image.BufferedImage;
import java.io.File;
import java.util.Map;
import java.util.Set;
import javax.imageio.ImageIO;
import com.drew.metadata.Directory;
import com.drew.metadata.bmp.BmpHeaderDirectory;
import com.drew.metadata.exif.ExifIFD0Directory;
import com.drew.metadata.gif.GifHeaderDirectory;
import com.drew.metadata.jpeg.JpegDirectory;
import com.drew.metadata.png.PngDirectory;
import com.google.common.collect.ImmutableMap;
import com.rakovets.jmm.entity.Metadata;
import com.drew.imaging.ImageMetadataReader;
import lombok.Builder;
import lombok.Data;
import lombok.experimental.UtilityClass;
@UtilityClass
public class ImageMetadataUtils {
@Data
@Builder
private static class NeededImageTag {
private int height;
private int width;
}
private static final Map<Class<? extends Directory>, NeededImageTag> SUPPORTED_TYPES_MAP
= new ImmutableMap.Builder<Class<? extends Directory>, NeededImageTag>()
.put(JpegDirectory.class, NeededImageTag.builder().height(JpegDirectory.TAG_IMAGE_HEIGHT).width(JpegDirectory.TAG_IMAGE_WIDTH).build())
.put(PngDirectory.class, NeededImageTag.builder().height(PngDirectory.TAG_IMAGE_HEIGHT).width(PngDirectory.TAG_IMAGE_WIDTH).build())
.put(GifHeaderDirectory.class, NeededImageTag.builder().height(GifHeaderDirectory.TAG_IMAGE_HEIGHT).width(GifHeaderDirectory.TAG_IMAGE_WIDTH).build())
.put(BmpHeaderDirectory.class, NeededImageTag.builder().height(BmpHeaderDirectory.TAG_IMAGE_HEIGHT).width(BmpHeaderDirectory.TAG_IMAGE_WIDTH).build())
.put(ExifIFD0Directory.class, NeededImageTag.builder().height(ExifIFD0Directory.TAG_IMAGE_HEIGHT).width(ExifIFD0Directory.TAG_IMAGE_WIDTH).build())
.build();
private static final Set<Class<? extends Directory>> SUPPORTED_TYPES = SUPPORTED_TYPES_MAP.keySet();
public static Metadata getMetadata(String url) {
try {
final File outputFile = new File(url);
final long fileSize = outputFile.length();
final com.drew.metadata.Metadata metadata = ImageMetadataReader.readMetadata(outputFile);
for (final Class<? extends Directory> type : SUPPORTED_TYPES) {
if (metadata.containsDirectoryOfType(type)) {
final Directory directory = metadata.getFirstDirectoryOfType(type);
final NeededImageTag tag = SUPPORTED_TYPES_MAP.get(type);
return new Metadata(url, directory.getInt(tag.width), directory.getInt(tag.height), fileSize);
}
}
return null;
} catch (Exception e) {
e.printStackTrace();
System.out.printf("[ERROR] Get metadata from url %s: %s\n", url, e.getMessage());
return null;
}
}
}Основная программа:
package com.rakovets.jmm.main;
import com.rakovets.jmm.entity.Metadata;
import com.rakovets.jmm.utils.ImageMetadataUtils;
public class ImageMetadataExample {
public static void main(String[] args) {
try {
// This application runs very fast and difficult to monitor so, I will sleep in 10 seconds.
System.out.println("Sleep in 10 seconds");
Thread.sleep(10000);
final String url = "/Users/daudm/Desktop/2000x2000px_keepcalm.jpg";
for (int i = 0; i < 2000; i ++) {
Metadata metadata = ImageMetadataUtils.getMetadata(url);
System.out.printf("Count %d URL: %s, metadata: %s\n", i, url, metadata.toString());
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}После этого можно запустить приложение и отследить его с помощью JVisualVM:
Приложение работает очень быстро и потребляет всего 21Mb в HEAP.
Умение управление памятью очень важно для каждого разработчика. Это не зависит от языка программирования: Java, C и т.д. Более глубокое понимание управления памятью поможет написать приложение с высокой производительностью, которое может работать на маломощных машинах. По сути, приложение написанное на Java будет работать на JVM. Для того что бы управлять памятью в Java, необходимо сначала понять архитектуру JVM.
8.2. Архитектура виртуальной машины Java (архитектура JVM)
JVM - это всего лишь спецификация, и она имеет множество различных реализаций. Можно провести аналогию с интерфейсом и несколькими реализациями в Java программе. Чтобы узнать информацию о JVM, можно воспользоваться командой java -version в терминале.
Если установлена AdoptOpenJDK, то отобразится следующая информация:
openjdk 11.0.7 2020-04-14 OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.7+10) OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.7+10, mixed mode)
Как же выглядит архитектура JVM?
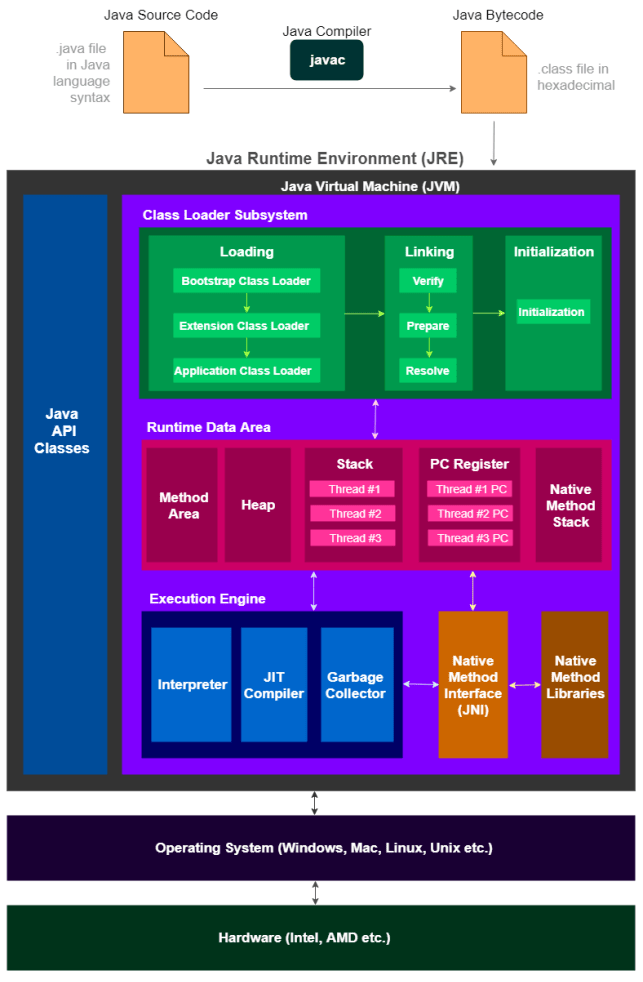
-
Class Loader Subsystem (Система загрузчиков классов): JVM работает с RAM. Во время выполнения с использованием Class Loader Subsystem файлы классов переносятся в RAM. Эта функция называется динамической загрузкой классов в Java. Она загружает, связывает и инициализирует
.class-файлы, когда идет первое обращение к классу во время выполнения. В конце будет выполнена логика инициализации каждого загруженного класса (например, вызов конструктора класса), всем статическим переменным будут присвоены исходные значения, и будет выполнен статический блок. -
Runtime Data Area (Область данных времени выполнения): области памяти, которая выдается JVM при запуске программы в ОС.
-
Method Area (Область метода) общая для потоков. Хранит все данные уровня класса (пул констант времени выполнения, статические переменные, данные полей, методы (данные, код)). Только один Method Area на JVM.
-
Heap Area (Область кучи) общая для потоков: здесь будут храниться все переменные, объекты, массивы. Один Heap на каждую JVM. За Heap Area и его очистку от неиспользуемых объектов отвечает GC.
-
Stack Area (Область стека) для каждого thread (потока) своя: для каждого потока в runtime будет создан новый stack area, для каждого вызова метода в стек будет добавлена одна запись, называемая stack frame. Каждый stack frame имеет ссылку на массив локальных переменных, стек операндов и пул констант времени выполнения класса, к которому принадлежит выполняемый метод.
-
-
Execution Engine (Механизм выполнения): будет выполнять byte-код, описанный в программе.
-
Interpreter (Интерпретатор): быстро интерпретирует byte-код, но медленно выполняет его. Недостатком является то, что когда один метод вызывается несколько раз, каждый раз требуется новая интерпретация и более медленное выполнение.
-
JIT Compiler (JIT-компилятор): устраняет недостатки interpreter, когда он обнаруживает повторяющийся код, он использует JIT Compiler. Он скомпилирует byte-код в машинный код. Код хранится в кеше, а не интерпретируется, поэтому скомпилированный код можно выполнить быстрее.
-
Garbage Collector (Сборщик мусора): собирает и удаляет объекты, которые не используются (т.е. на которые нет ссылок). Пока на объект ссылаются, JVM считает его живым. Когда на объект больше не ссылаются и, следовательно, он недоступен для кода приложения, Garbage Collector удаляет его и освобождает неиспользуемую память. В общем, Garbage Collector - это автоматический процесс. Однако его можно запустить, вызвав метод
System.gc()илиRuntime.getRuntime().gc(). Но выполнение не гарантируется, поэтому следует вызватьThread.sleep(1000)и дождаться завершения GC.
-
8.3. Модель памяти (HEAP, без HEAP, другая память)
JVM использует доступное пространство памяти в операционной системе. JVM включает области памяти:
-
HEAP
-
Non-HEAP
-
Other Memory
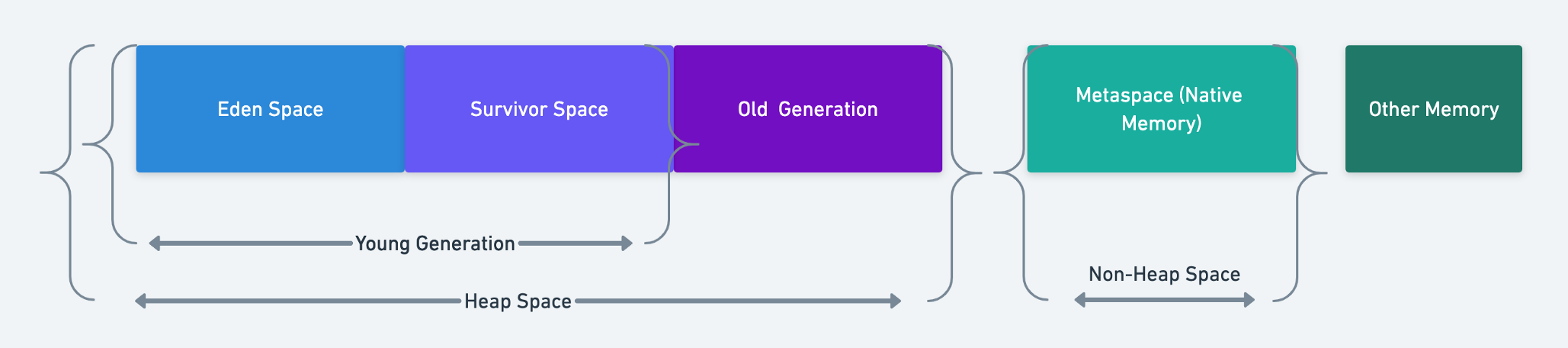
8.3.1. HEAP
HEAP состоит из двух частей:
-
Young Generation (Young Gen/Молодое поколение)
-
Old Generation (Old Gen/Старое поколение)
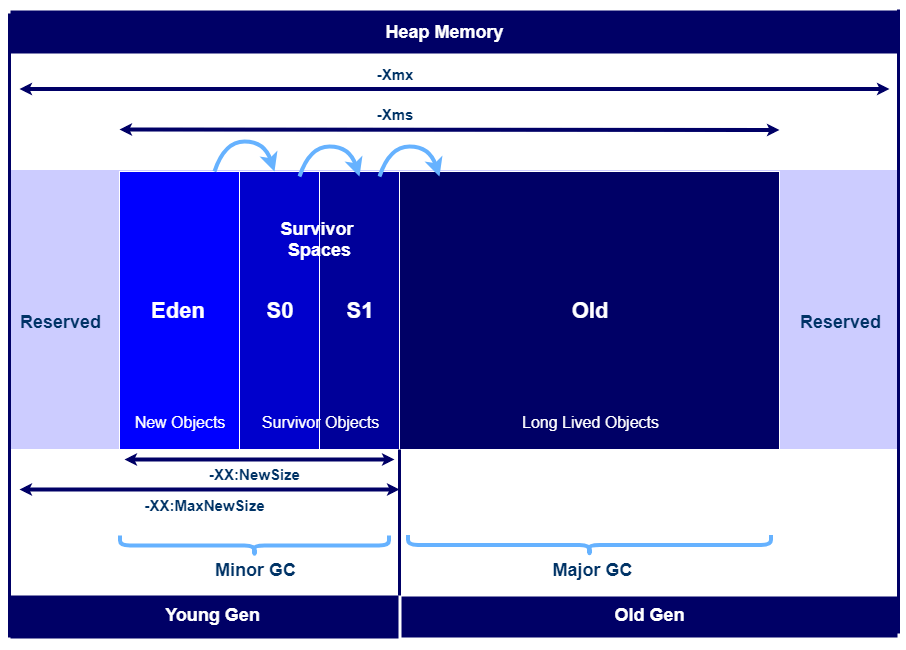
-
Young Generation: здесь создаются все новые объекты. Когда Young Generation заполнено, выполняется сборщик мусора (Minor GC). Он разделен на три части: одно Eden Space и два Survivor Spaces (S0, S1). Некоторые тонкости:
-
Большинство только что созданных объектов находится в Eden Space.
-
Если Eden Space заполнен объектами, Minor GC будет выполнен, и все выжившие объекты перемещается к одному из оставшихся в Survivor Spaces.
-
Объекты, уцелевшие после многих циклов Minor GC, перемещаются в пространство Old Generation space. Обычно это делается путем установления порога возраста объектов Young Generation, прежде чем они станут подходящими для продвижения к Old Generation.
-
-
Old Generation: зарезервировано для содержания долгоживущие объектов, которые выживают после многих раундов в Minor GC. Когда Old Generation полно, будет выполнен Major GC, но как правило, он занимает больше времени.
8.3.2. Non-HEAP
Non-HEAP (Off-HEAP): иногда называют Off-HEAP. В Java 7 и более ранних версиях это пространство называется Permanent Generation (Perm Gen). Начиная с Java 8, Perm Gen заменяется Metaspace.
Metaspace хранит структуры для каждого класса, такие как пул констант времени выполнения, данные полей и методов, а также код методов и конструкторов, а также интернированные строки.
Metaspace по умолчанию автоматически увеличивает свой размер (до того, что предоставляет базовая ОС), в то время как Perm Gen всегда имеет фиксированный максимальный размер. Для установки размера метапространства можно использовать два новых флага: -XX:MetaspaceSize и -XX:MaxMetaspaceSize.
8.3.3. Other memory
-
CodeCache содержит complied-код (т.е. native-код), созданный JIT-компилятором, внутренние структуры JVM, загруженный код агента профилировщика, данные и т.д.
-
Thread Stacks относятся к интерпретируемым, скомпилированным и собственным stack frames.
-
Direct Memory используется для выделения прямого буфера (например, NIO Buffer/ByteBuffer)
-
C-Heap используется, например, JIT-компилятором или GC для выделения памяти для внутренних структур данных.
8.4. Garbage Collection
GC помогает разработчикам писать код без выделения/освобождения памяти и позволяет не заботиться о проблемах с памятью. Однако в реальном проекте иногда имеются проблем с памятью. Они заставляют приложение работать с неэффективно и очень медленно.
Таким образом, мы должны понять, как работает GC. Все объекты размещаются в HEAP, управляемой JVM. Пока на объект ссылаются, JVM считает его живым. Когда на объект больше не ссылаются и, следовательно, он недоступен для кода приложения, garbage collector удаляет его и освобождает неиспользуемую память.
Как GC управляет объектами в HEAP? Ответ заключается в том, что он строит Tree (дерево), называемое Garbage Collection Roots (GC roots/корни сборки мусора). Он содержит множество ссылок между кодом приложения и объектами в HEAP.
Существует четыре типа Garbage Collection Roots:
-
Local variables (локальные переменные)
-
Active threads (активные потоки)
-
Static variables (статические переменные)
-
JNI references (JNI ссылки).
Пока на наш объект прямо или косвенно ссылается один из этих корней GC, а корень GC остается живым, наш объект можно рассматривать как достижимый объект. В тот момент, когда объект теряет ссылку на Garbage Collection Root, он становится недоступным, следовательно, может быть удален когда произойдет GC.
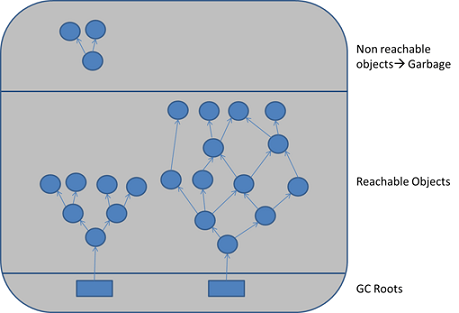
Garbage Collection Roots - это объекты, на которые сама JVM ссылается и, таким образом, предотвращает сборку мусора для всех остальных объектов.
8.4.1. Mark and Sweep Model
Чтобы определить, какие объекты больше не используются, JVM использует алгоритм mark-and-sweep.
-
Алгоритм просматривает все ссылки на объекты, начиная с Garbage Collection Roots, и отмечает каждый найденный объект как живой.
-
Требуется вся память *HEAP, которая не занятая отмеченными объектами.
Возможны случаи, когда есть неиспользуемые объекты, но которые все еще доступны для приложения, потому что разработчики просто забыли разыменовать их. В этом случае происходит memory-leak (утечка памяти). Поэтому следует отслеживать/анализировать приложение, чтобы определить проблему.
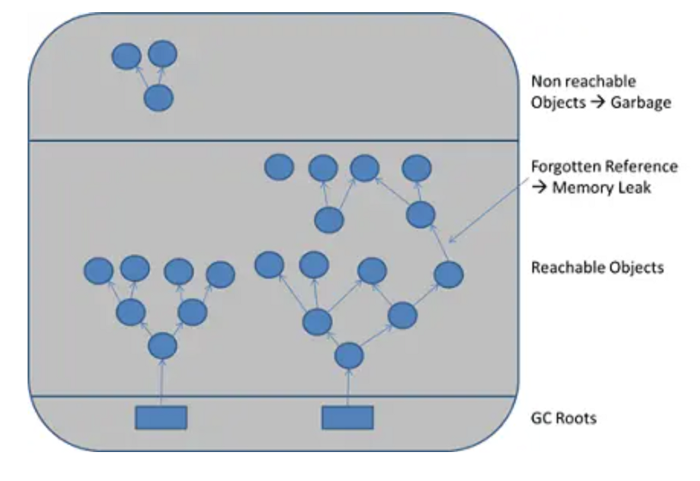
Когда на объекты больше не ссылается прямо или косвенно корень сборщика мусора, они будут удалены.
8.4.2. Stop the World Event
При выполнении GC все потоки приложений останавливаются до завершения операции. Поскольку Young Generation хранит недолговечные объекты, Minor GC работает очень быстро, и это не влияет на приложение. Однако Major GC занимает много времени, потому что он проверяет все живые объекты. Количество Major GC следует свести к минимуму, поскольку он приведет к тому, что приложение не будет отвечать на все время GC.
8.5. Мониторинг и настройка GC
Можно отслеживать приложение Java с помощью командной строки и различных инструментов. На самом деле существует множество инструментов: JVisualVM, JProfile, Eclipse MAT, JetBrains JVM Debugger, Netbeans Profiler, … Рекомендуется использовать JVisualVM, который встроен в JDK. Этого достаточно для мониторинга приложения.
8.5.1. jstat
jstat - Java Virtual Machine Statistics Monitoring Tool. jstat можно использовать для мониторинга памяти JVM и активности GC. Например, можно печать потребление памяти и данных GC каждую секунду:
jstat -gc <pid> 1000jstat
| Column | Description |
|---|---|
S0C |
Current survivor space 0 capacity (KB). |
S1C |
Current survivor space 1 capacity (KB). |
S0U |
Survivor space 0 utilization (KB). |
S1U |
Survivor space 1 utilization (KB). |
EC |
Current eden space capacity (KB). |
EU |
Eden space utilization (KB). |
OC |
Current old space capacity (KB). |
OU |
Old space utilization (KB). |
PC |
Current permanent space capacity (KB). |
PU |
Permanent space utilization (KB). |
YGC |
Number of young generation GC Events. |
YGCT |
Young generation garbage collection time. |
FGC |
Number of full GC events. |
FGCT |
Full garbage collection time. |
GCT |
Total garbage collection time. |
|
Note
|
Если не получается запустить команду или выдает ошибку: Не удалось подключиться к <pid>, тогда следует запустить команду от имени root пользователя.
|
8.5.2. JVisualVM
Можно открыть GUI Tool через terminal с помощью команды jvisualvm. Этот инструмент, использовался в начале. Рекомендую использовать JVisualVM для мониторинга/настройки GC перед релизом каких-либо функций в testing/staging/production environment. Необходимо проверять, есть ли проблемы с памятью, чтобы:
-
гарантировать, что приложение потребляет мало памяти
-
гарантировать, что приложение работает очень быстро и не имеет проблем с memory-leak.
Важно, что приложение может использовать native memory (Metaspace, Direct Memory), которая не управляется GC. В этом случае необходимо выделить/освободить память вручную. Когда используются сторонние библиотеки, необходимо внимательно проверять их перед использованием.
Иногда, используя сторонние библиотеки, можно ожидать что они будут использовать HEAP и создавать в нем объекты, но на самом деле, они могут использовать native memory (ByteBuffer). Когда приложение будет тестироваться, то все будет работать нормально, только тестирование производительности (например с помощью Jmeter) выявит проблему с недостатком памяти.
8.5.3. Java Non-Standard Options
Для повышения производительности приложения можно проверить и установить нестандартные параметры для JVM. Их можно просмотреть через командную строку с помощью команды:
java -X -Xbatch disable background compilation
-Xbootclasspath/a:<directories and zip/jar files separated by :>
append to end of bootstrap class path
-Xcheck:jni perform additional checks for JNI functions
-Xcomp forces compilation of methods on first invocation
-Xdebug provided for backward compatibility
-Xdiag show additional diagnostic messages
-Xfuture enable strictest checks, anticipating future default
-Xint interpreted mode execution only
-Xinternalversion
displays more detailed JVM version information than the
-version option
-Xloggc:<file> log GC status to a file with time stamps
-Xmixed mixed mode execution (default)
-Xmn<size> sets the initial and maximum size (in bytes) of the heap
for the young generation (nursery)
-Xms<size> set initial Java heap size
-Xmx<size> set maximum Java heap size
-Xnoclassgc disable class garbage collection
-Xrs reduce use of OS signals by Java/VM (see documentation)
-Xshare:auto use shared class data if possible (default)
-Xshare:off do not attempt to use shared class data
-Xshare:on require using shared class data, otherwise fail.
-XshowSettings show all settings and continue
-XshowSettings:all
show all settings and continue
-XshowSettings:locale
show all locale related settings and continue
-XshowSettings:properties
show all property settings and continue
-XshowSettings:vm
show all vm related settings and continue
-XshowSettings:system
(Linux Only) show host system or container
configuration and continue
-Xss<size> set java thread stack size
-Xverify sets the mode of the bytecode verifier
--add-reads <module>=<target-module>(,<target-module>)*
updates <module> to read <target-module>, regardless
of module declaration.
<target-module> can be ALL-UNNAMED to read all unnamed
modules.
--add-exports <module>/<package>=<target-module>(,<target-module>)*
updates <module> to export <package> to <target-module>,
regardless of module declaration.
<target-module> can be ALL-UNNAMED to export to all
unnamed modules.
--add-opens <module>/<package>=<target-module>(,<target-module>)*
updates <module> to open <package> to
<target-module>, regardless of module declaration.
--illegal-access=<value>
permit or deny access to members of types in named modules
by code in unnamed modules.
<value> is one of "deny", "permit", "warn", or "debug"
This option will be removed in a future release.
--limit-modules <module name>[,<module name>...]
limit the universe of observable modules
--patch-module <module>=<file>(:<file>)*
override or augment a module with classes and resources
in JAR files or directories.
--disable-@files disable further argument file expansion
--source <version>
set the version of the source in source-file mode.
These extra options are subject to change without notice.
В некоторых вариантах часто используются:
-
-Xms <size>[unit](gдля GB,mдля MB иkдля KB): для установки начального размера кучи при запуске JVM. По умолчанию: начальный размер кучи 1/64 физической памяти до 1 GB. -
-Xmx <size>[unit](gдля GB,mдля MB иkдля KB): для установки максимального размера кучи. По умолчанию: максимальный размер кучи составляет 1/4 физической памяти до 1 GB. -
-Xss <size>[unit](gдля GB,mдля MB иkдля KB): установить размер стека потока Java. Значение по умолчанию зависит от ОС. Это можно проверить через командную строку:
java -XX: + PrintFlagsFinal -version | grep ThreadStackSize intx CompilerThreadStackSize = 1024 {pd product} {default}
intx ThreadStackSize = 1024 {pd product} {default}
intx VMThreadStackSize = 1024 {pd product} {default}
openjdk version "11.0.7" 2020-04-14
OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.7+10)
OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.7+10, mixed mode)
8.6. Советы для повышения производительности при разработке веб-приложения
-
Следует ограничить, создание новых объектов и как можно скорее освободить память.
-
Использовать JVisualVM для мониторинга приложения перед релизом приложения на testing/staging/production environment.
-
Внимательно проверить сторонние библиотеки, перед использованием.
-
Изучить и применять лучшие практики борьбы с memory-leak: изменяемые статические поля и коллекции, локальные переменные потока, Circular and Complex Bi-Directional References,
ByteBuffer,BufferImage, незакрытый поток, незакрытое соединение, … -
Внимательно проверять код.
9. Properties
Класс Properties – это подкласс Hashtable.
Он используется для хранения списков значений, в которых ключ является String, а значение также является String.
Класс Properties в Java используется множеством других классов.
Например, это тип объекта, возвращаемый System.getProperties(), когда тот получает внешние значения.
Properties определяет следующие переменную экземпляра.
Properties defaults;Эта переменная содержит список свойств по умолчанию, связанный с объектом Properties.
9.1. Конструкторы
Вот список конструкторов, предоставляемые классом Properties.
-
Properties()конструктор создает объектProperties, который не имеет значений по умолчанию. -
Properties(Properties propDefault)создаёт объект, который использует propDefault для своих значений по умолчанию. В обоих случаях список свойств пустой.
9.2. Методы
Помимо методов, определённых Hashtable, Properties определяет следующие методы:
-
String getProperty(String key)возвращает значение, связанное с ключом. Возвращается нулевой объект, если ключ не находится ни в списке, ни в списке свойств по умолчанию. -
String getProperty(String key, String defaultProperty)возвращает значение, связанное с ключом; ВозвращаетсяdefaultProperty, если ключ не находится ни в списке, ни в списке свойств по умолчанию. -
void list(PrintStream streamOut)отправляет список свойств в выходной поток, связанный сstreamOut. -
void list(PrintWriter streamOut)отправляет список свойств в выходной поток, связанный сstreamOut. -
void load(InputStream streamIn) throws IOExceptionвводит список свойств из входного потока, связанного сstreamIn. -
Enumeration propertyNames()возвращает перечисление ключей, включая ключи, найденные в списке свойств по умолчанию. -
Object setProperty(String key, String value)связывает значение с ключом. Возвращает предыдущее значение, связанное с ключом, или возвращаетnull, если такой связи не существует. -
void store(OutputStream streamOut, String description)после записи строки, указанной в описании, список свойств записывается в выходной поток, связанный сstreamOut.
9.3. Примеры
9.3.1. Пример: системные свойства
Получим и выведем все системные свойства:
import java.util.Map;
import java.util.Properties;
import java.util.Set;
/**
* Java program to demonstrate Properties class to get all the system properties
*/
public class PropertiesExample2GetSystemProperties {
/**
* Main method for Demo
*
* @param args input arguments
*/
public static void main(String[] args) {
// get all the system properties
Properties p = System.getProperties();
// stores set of properties information
Set<Map.Entry<Object, Object>> set = p.entrySet();
// iterate over the set
for (Map.Entry<Object, Object> entry : set) {
// print each property
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
}
}Будет выведено следующее:
java.specification.version=15 sun.management.compiler=HotSpot 64-Bit Tiered Compilers sun.jnu.encoding=UTF-8 java.runtime.version=15.0.1+9 java.class.path=/home/rakovets/dev/course-java-basics/build/classes/java/main:/home/rakovets/dev/course-java-basics/build/resources/main user.name=rakovets java.vm.vendor=AdoptOpenJDK path.separator=: sun.arch.data.model=64 os.version=5.8.0-34-generic user.variant= java.runtime.name=OpenJDK Runtime Environment file.encoding=UTF-8 java.vendor.url=https://adoptopenjdk.net/ java.vm.name=OpenJDK 64-Bit Server VM java.vm.specification.version=15 os.name=Linux java.vendor.version=AdoptOpenJDK user.country=US sun.java.launcher=SUN_STANDARD sun.boot.library.path=/home/rakovets/.sdkman/candidates/java/15.0.1.hs-adpt/lib sun.java.command=com.rakovets.course.javabasics.example.properties.PropertiesExample2GetSystemProperties java.vendor.url.bug=https://github.com/AdoptOpenJDK/openjdk-support/issues java.io.tmpdir=/tmp jdk.debug=release sun.cpu.endian=little java.version=15.0.1 user.home=/home/rakovets user.dir=/home/rakovets/dev/course-java-basics user.language=en os.arch=amd64 java.specification.vendor=Oracle Corporation java.vm.specification.name=Java Virtual Machine Specification java.version.date=2020-10-20 java.home=/home/rakovets/.sdkman/candidates/java/15.0.1.hs-adpt file.separator=/ java.vm.compressedOopsMode=Zero based line.separator= java.library.path=/usr/java/packages/lib:/usr/lib64:/lib64:/lib:/usr/lib java.vm.info=mixed mode, sharing java.vm.specification.vendor=Oracle Corporation java.specification.name=Java Platform API Specification java.vendor=AdoptOpenJDK java.vm.version=15.0.1+9 sun.io.unicode.encoding=UnicodeLittle java.class.version=59.0
9.3.2. Пример: чтение свойств из файла
Файл account.properties содержит следующий списком свойств:
username=rakovets
password=Fc9S42SMEfJbNVtMПрочитаем его и выведем все свойства:
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Properties;
/**
* Java program to demonstrate Properties class to get information from the properties file
*/
public class PropertiesExample1 {
/**
* Main method for Demo
*
* @param args input arguments
* @throws IOException throw IOException when work with IO
*/
public static void main(String[] args) throws IOException {
// get path for user.properties
Path userPropertiesPath =
Paths.get("src", "main", "resources", "example", "properties", "account.properties");
// create a reader object on the properties file
FileReader reader = new FileReader(userPropertiesPath.toFile());
// create properties object
Properties p = new Properties();
// Add a wrapper around reader object
p.load(reader);
// access properties data
System.out.printf("Username: '%s'\n", p.getProperty("username"));
System.out.printf("Password: '%s'\n", p.getProperty("password"));
}
}Будет выведено следующее:
Username: 'rakovets' Password: 'Fc9S42SMEfJbNVtM'
9.3.3. Пример: записи свойств в файл
Создадим свойства и запишем их в файл user.properties:
import java.io.FileWriter;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Properties;
/**
* Java program to demonstrate Properties class to create the properties file
*/
public class PropertiesExample3CreateAndWriteToFile {
/**
* Main method for Demo
*
* @param args input arguments
* @throws IOException throw IOException when work with IO
*/
public static void main(String[] args) throws IOException {
// create an instance of Properties
Properties p = new Properties();
// add properties to it
p.setProperty("name", "Dmitry Rakovets");
p.setProperty("email", "dmitryrakovets@gmail.com");
// get path for account.properties
Path userPropertiesPath =
Paths.get("src", "main", "resources", "example", "properties", "user.properties");
// store the properties to a file
p.store(new FileWriter(userPropertiesPath.toFile()), "Properties Example");
}
}Создастся файл user.properties:
#Properties Example
#Fri Jan 08 10:05:19 MSK 2021
name=Dmitry Rakovets
email=dmitryrakovets@gmail.com10. Java NIO
Java NIO (New IO) - это альтернативный API для работы с IO в Java (начиная с Java 1.4), это значит альтернативный стандартным Java IO и API Java Networking. Java NIO предлагает другой способ работы с IO, чем стандартный IO API.
Java NIO: channels и buffers
В стандартном IO API работают с потоками байт и потоками символов. В NIO работают с каналами и буферами. Данные всегда читаются из канала в буфер или записываются из буфера в канал.
Java NIO: non-bloking IO
Java NIO позволяет выполнять неблокирующие операции ввода-вывода. Например, поток может попросить канал прочитать данные в буфер. Пока канал читает данные в буфер, поток может делать что-то другое. Как только данные будут считаны в буфер, поток сможет продолжить их обработку. Аналогично и для записи данных в каналы.
Java NIO: selectors
Java NIO имеет понятие «селекторы». Селектор - это объект, который может отслеживать несколько каналов на наличие событий (например: соединение установлено, данные получены и т.д.). Таким образом, один поток может контролировать несколько каналов данных.
10.1. Обзор Java NIO
Java NIO состоит из следующих основных компонентов:
-
каналы
-
буферы
-
селекторы
Java NIO имеет не только эти компоненты, но фактически, Channel, Buffer и Selector являются ключевыми классами. Остальные компоненты, такие как Pipe и FileLock являются просто служебными классами, которые используются вместе с тремя основными компонентами.
10.1.1. Каналы и Буферы
Как правило, все операции ввода-вывода в NIO начинаются с Channel. Channel немного похож на Stream. Из Channel данные можно прочитать в Buffer. Данные также могут быть записаны из Buffer в Channel. :
Есть несколько Channel и Buffer типов. Ниже приведен список основных реализаций Channel в Java NIO:
-
FileChannel -
DatagramChannel -
SocketChannel -
ServerSocketChannel
Эти каналы охватывают сетевой ввод-вывод по протоколам UDP и TCP и файловый ввод-вывод.
А вот список основных реализаций Buffer в Java NIO:
-
ByteBuffer -
CharBuffer -
DoubleBuffer -
FloatBuffer -
IntBuffer -
LongBuffer -
ShortBuffer
Они Buffer охватывают основные типы данных, которые вы можете отправлять через IO:
-
char -
byte -
short -
int -
long -
float -
double
Java NIO также имеет, MappedByteBuffer который используется для работы с отображением файлов в оперативной памяти.
10.1.2. Селекторы
Selector позволяет одному потоку обрабатывать несколько Channel. Это удобно, если в вашем приложении открыто много соединений (каналов), но каждое соединении имеет небольшой трафик. Например: сервер для чата.
Ниже приведенно изображение, того как Thread использует Selector для обработки 3 Channel:
Чтобы использовать, Selector необходимо зарегистрировать Channel с ним. Для этого используеют вызов метода select(). Этот метод будет заблокирован, пока не произойдет событие для одного из зарегистрированных каналов. Как только метод разблокируется, поток может обработать события. Примерами событий являются: входящее соединение, полученные данные и т.д.
10.2. Channel
Каналы Java NIO похожи на потоки с некоторыми отличиями:
-
можно читать/писать из/в каналы, а потоки обычно односторонние (чтение/запись)
-
каналы могут быть прочитаны/записаны асинхронно
-
каналы всегда читают/записывают из/в буфер
10.2.1. Реализация Channel
Вот наиболее важные реализации Channel в Java NIO:
-
FileChannel- считывает данные из/в файла -
DatagramChannel- считывает/записывает данные по сети через UDP -
SocketChannel- считывает/записывает данные по сети через TCP -
ServerSocketChannel- прослушивает входящие соединения TCP, как это делает web-server, т.е. для каждого входящего соединения создаетсяSocketChannel.
10.2.2. Пример основного канала
Вот базовый пример, в котором используется FileChannel для чтения некоторых данных в Buffer:
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
while (bytesRead != -1) {
System.out.println("Read " + bytesRead);
buf.flip();
while(buf.hasRemaining()) {
System.out.print((char) buf.get());
}
buf.clear();
bytesRead = inChannel.read(buf);
}
aFile.close();Обратите внимание на вызов buf.flip(). Сначала из канала считывают в буфер. Затем буфер переворачивают. После чего считывают из буффера.
10.3. Buffers
Буферы используются при взаимодействии с каналами.
Буфер - это, по сути, блок памяти, в который можно записывать данные, которые затем можно снова прочитать. Этот блок памяти обернут в объект Buffer, который предоставляет набор методов, облегчающих работу с блоком памяти.
10.3.1. Основное использование буфера
Использование Buffer для чтения и записи данных обычно состоит из четырех шагов:
-
Записать данные в буфер
-
Вызов метода
buffer.flip() -
Чтение данных из буфера
-
Вызов одного из методов
buffer.clear()илиbuffer.compact()
Когда данные записывают в буфер, буфер отслеживает, сколько данных записано. Когда нужно прочитать данные, тогда нужно переключить буфер из режима записи в режим чтения с помощью вызова метода flip(). В режиме чтения буфер позволяет читать все данные, записанные в буфер.
После того, как все данные были прочитаны, необходимо очистить буфер, чтобы он снова был готов к записи. Это можно сделать вызвав один из двух методов:
-
clear()- метод очищает весь буфер -
compact()- метод удаляет только те данные, которые уже прочитали. Любые непрочитанные данные перемещаются в начало буфера, и теперь новые данные будут записываться в буфер после непрочитанных данных
Например:
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
//create buffer with capacity of 48 bytes
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf); //read into buffer.
while (bytesRead != -1) {
buf.flip(); //make buffer ready for read
while(buf.hasRemaining()){
System.out.print((char) buf.get()); // read 1 byte at a time
}
buf.clear(); //make buffer ready for writing
bytesRead = inChannel.read(buf);
}
aFile.close();10.3.2. Capacity, position и limit для буфера
У Buffer есть три поля, с которыми нужно ознакомиться, чтобы понять, как Buffer работает:
-
capacity -
position -
limit
Значение position и limit зависит от того, Buffer находится ли режим чтения или записи. Емкость всегда означает одно и то же, независимо от режима буфера.
Вот иллюстрация емкости, положения и ограничения в режимах записи и чтения. Объяснение следует в разделах после иллюстрации.
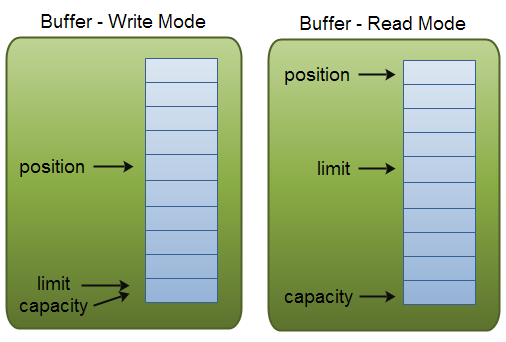
Capacity
Будучи блоком памяти, a Buffer имеет определенный фиксированный размер, в который можно записывать только байты, символы и т.д. Когда буфер заполнен, тогда нужно его очистить (прочитать или очистить данные), прежде чем иметь возможность записать в него больше данных.
Position
Когда данные записываются в Buffer, то это происходит с текущей position. Первоначально позиция равна 0. Когда происходит запись одного байта, символа и т.д. в Buffer в текущую position, то она перемещается вперед, чтобы указывать на следующую ячейку в буфере, куда в дальнейшем будут записываться данные. Максимальное значение position может быть capacity - 1.
Когда данные из Buffer читаются, то это можно делать с текущей position. Когда Buffer переключается из режима записи в режим чтения, position сбрасывается обратно на 0. При чтении данных из Buffer, они читаются с position и значение position изменяется на следующее.
Limit
В режиме записи limit для Buffer - это предел того, сколько данных можно записать в буфер. В режиме записи ограничение равно capacity для Buffer.
При переключении Buffer в режим чтения, limit означает предел того, сколько данных можно прочитать. Следовательно, при переключении Buffer в режим чтения limit задается равным position в режиме записи. Другими словами, можно прочитать столько байтов, сколько было записано.
10.3.3. Типы буфера
Java NIO содержит следующие типы буферов:
-
ByteBuffer -
MappedByteBuffer -
CharBuffer -
DoubleBuffer -
FloatBuffer -
IntBuffer -
LongBuffer -
ShortBuffer
Эти типы Buffer представляют разные типы данных. Другими словами, они позволяют работать с байтами в буфере как char, short, int, long, float или double.
10.3.4. Создание буфера
У каждого Buffer класса есть allocate() метод, который создает объект Buffer. Например, создание ByteBuffer с capacity 48 байт:
ByteBuffer buf = ByteBuffer.allocate(48);Например, создание CharBuffer с capacity для размещения 1024 символов:
CharBuffer buf = CharBuffer.allocate(1024);10.3.5. Запись данных в буфер
Данные в буфер можно записать двумя способами:
-
из
ChannelвBuffer -
используя
put()методы классаBuffer
Пример, как с помощью Channel можно записывать данные в Buffer:
int bytesRead = inChannel.read(buf); // read into bufferПример, как с помощью метода put() класса Buffer можно записывать данные в него:
buf.put (127);Существует много других версий метода put(), позволяющих записывать данные в Buffer различными способами. Например, запись в определенные позиции или запись массива байтов в буфер. Все это, можно посмотреть в JavaDoc для конкретной реализации буфера.
10.3.6. flip()
Метод flip() переключает Buffer из режима записи в режиме чтения. Вызов метода flip() устанавливает position обратно в 0 и устанавливает limit значение недавного position.
Другими словами, position теперь указывает на позицию чтения, а limit показывает, сколько байт, символов и т.д. было записано в буфер.
10.3.7. Чтение данных из буфера
Есть два способа чтения данных из Buffer.
-
из
BufferвChannel -
используя
get()методы классаBuffer
Пример, как с помощью Channel можно читать данные из Buffer:
//read from buffer into channel.
int bytesWritten = inChannel.write(buf);Пример, как с помощью метода get() класса Buffer можно читать данные из него:
byte aByte = buf.get();Существует много других версий метода get(), позволяющих считывать данные из Buffer различными способами. Например, чтение из определенных позиций или чтение массива байт из буфера. Все это, можно посмотреть в JavaDoc для конкретной реализации буфера.
10.3.8. rewind()
Buffer.rewind() устанавливает в position значение 0, так что можно было перечитать все данные в буфере. При этом limit не изменяется.
10.3.9. clear() и compact()
После прочтения данных из Buffer, его необходимо снова подготовиться к записи. Это можно сделать, вызвав методы clear() или compact().
Если вызвать метод clear(), то limit станет равен значению capacity, a position станет 0. Другими словами, Buffer очищается, но данные из него не удалены.
Если в момент вызова clear() были непрочитанные данные, то нельзя больше установить какие из них были прочитаны, а какие нет.
Если в Buffer все еще есть непрочитанные данные, и их необходимо прочитать позже, но перед этим нужно что-то еще записать в Buffer, тогда используют compact() вместо clear().
Метод compact() копирует все непрочитанные данные в начало Buffer, а затем position устанавливается сразу после последнего непрочитанного элемента. Для limit задается значение capacity, так же, как и для clear(). Теперь Buffer готов к записи и непрочитанные данные не будет перезаписываться.
10.3.10. mark() и reset()
Можно пометить данную позицию в Buffer, вызвав метод Buffer.mark(). Затем можно сбросить position обратно в помеченную позицию, вызвав метод Buffer.reset(). Вот пример:
buffer.mark();
//call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.10.3.11. equals() и compareTo()
Можно сравнить два буфера, используя equals() и compareTo().
equals()
Два буфера равны, если:
-
Они одного типа (байт, символ, int и т. Д.)
-
Они имеют одинаковое количество оставшихся байтов, символов и т. Д. В буфере.
-
Все остальные байты, символы и т. Д. Равны.
-
Как вы можете видеть, функция equals сравнивает только часть `Buffer, а не каждый отдельный элемент. На самом деле, он просто сравнивает остальные элементы в `Buffer.
compareTo()
Метод compareTo() сравнивает остальные элементы (байты, символы и т.д.) из двух буферов, для использования, например, в подпрограммах сортировки. Буфер считается «меньшим», чем другой буфер, если:
-
найден элемент, который отличается от соответствующего элемента из другого буфера, и он меньше его
-
все элементы равны, но в первом буфере количество элементов меньше, чем во втором
11. Localization and Internationalization
Вопрос интернационализации пользовательского интерфейса - один из важных вопросов при разработке приложения. Для этого недостаточно использовать Unicode и перевести на нужный язык все сообщения пользовательского интерфейса. Интернационализация приложения означает нечто большее, чем поддержка Unicode. Дата, время, денежные суммы и даже числа могут по-разному представляться на различных языках.
Широкое распространение получили условные сокращения терминов интернационализации и локализации приложений i18n и l10n, в которых, цифра означает количество символов между первой и последней позицией:
-
l10n - локализация (localization).
-
i18n - интернационализация (internationalization);
В отдельной литературе делают акцент на этих двух определениях, под которыми понимается:
-
Интернационализация - это процесс разработки приложения такой структуры, при которой дополнение нового языка не требует перестройки и компиляции (сборки) всего приложения.
-
Локализация предполагает адаптацию интерфейса приложения под несколько языков. Добавление нового языка может внести определенные сложности в локализацию интерфейса.
Java - первый язык программирования, в котором изначально были предусмотрены средства интернационализации. Строки формируются из символов Unicode. Поддержка этого стандарта кодирования позволяет создавать Java-приложения, обрабатывающие тексты на любом из существующих в мире языков.
11.1. Региональные стандарты Locale
Приложение, которое адаптировано для международного рынка, легко определить по возможности выбора языка, для работы с ним. Но профессионально адаптированные приложения могут иметь разные региональные настройки даже для тех стран, в которых используется одинаковый язык. В любом случае команды меню, надписи на кнопках и программные сообщения должны быть переведены на местный язык, возможно с использованием специального национального алфавита. Но существует еще много других более тонких различий, которые касаются:
-
форматов представления вещественных чисел (разделители целой и дробной частей, разделителей групп тысяч)
-
денежных сумм (включение и местоположения денежного знака)
-
формата даты (порядок следования и символы разделители дней, месяцев и лет)
Существует ряд классов, которые выполняют форматирование, принимая во внимание указанные выше различия. Для управления форматированием используется класс Locale.
Региональный стандарт Locale определяет язык. Кроме этого могут быть указаны географическое расположение и вариант языка. Например, в США используется следующий региональный стандарт:
language=English, location=United States
В Германии региональный стандарт имеет вид:
language=German, location=Germany
В Швейцарии используются четыре официальных языка:
-
немецкий
-
французский
-
итальянский
-
ретороманский
Поэтому немецкие пользователи в Швейцарии, вероятно, захотят использовать следующий региональный стандарт:
language=German, location=Switzerland
В данном случае текст, даты и числа будут форматироваться так же, как и для Германии, но денежные суммы будут отображаться в швейцарских франках, а не в евро. Если задавать только язык, например language=German, то особенности конкретной страны (например, формат представления денежных единиц) не будут учтены.
Вариант языка используется довольно редко. Например, в настоящее время в норвежском языке (производном от датского) определены два набора правил правописания
-
Bokmel
-
новый Nynorsk
В этом случае, для задания традиционных правил орфографии используется параметр, определяющий вариант:
language=Norwegian, location=Norway, variant=Bokmel
Для выражения языка и расположения в компактной и стандартной форме в Java используются коды, определенные Международной организацией по стандартизации (ISO). Язык обозначается двумя строчными буквами в соответствии со стандартом ISO-639, а страна(расположение) — двумя прописными буквами согласно стандарту ISO-3166.
Чтобы задать региональный стандарт, необходимо объединить код языка, код страны и вариант (если он есть), а затем передать полученную строку в конструктор класса Locale.
Locale german = new Locale("de");
Locale germanGermany = new Locale("de", "DE");
Locale germanSwitzerland = new Locale("de", "CH");
Locale norwegianNorwayBokmel = new Locale("no", "NO", "B");Для удобства пользователей в JDK предусмотрено несколько предопределенных объектов с региональными настройками, а для некоторых языков также имеются объекты, позволяющие указать язык без указания страны:
| Предопределенные объекты с региональными установками | Объекты, позволяющие указать язык без указания страны |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Помимо вызова конструктора или выбора предопределенных объектов, существует еще два пути получения объектов с региональными настройками. Статический метод getDefault() класса Locale позволяет определить региональную настройку, которая используется в операционной системе по-умолчанию. Изменить настройку по-умолчанию можно вызвав метод setDefault(). Однако следует помнить, что данный метод воздействует только на Java-программу, а не на операционную систему в целом.
11.1.1. Региональные настройки, getAvailableLocales()
Метод getLocale() возвращает региональные настройки того компьютера, на котором он запущен. И наконец, все зависимые от региональных настроек вспомогательные классы могут возвращать массив поддерживаемых региональных стандартов. Например, приведенный ниже метод возвращает все региональные настройки, поддерживаемые классом DateFormat.
Locale [] supportedLocales = DateFormat.getAvailableLocales();Какие действия можно выполнять на основе полученных региональных настроек? Выбор невелик. Единственными полезными методами класса Locale являются методы определения кодов языка и страны. Наиболее важными из них является метод getDisplayName(), возвращающий строку с описанием региональной настройки, которая содержит не какие-то двух-буквенные загадочные коды, а вполне понятные пользователю обозначения
German(Switzerland)
Но данная строка отображается на используемом по умолчанию языке, что далеко не всегда бывает удобно. Если пользователь выбрал немецкий язык интерфейса, то строку описания следует отобразить именно на немецком языке, для чего можно передать в качестве параметра соответствующую региональную настройку так, как представлено в следующих строках кода:
Locale loc = new Locale("de", "CH");
System.out.println (loc.getDisplayName(Locale.GERMAN));В результате выполнения этого кода описание региональной настройки будет выведено на указанном в ней языке:
Deutsch(Schweiz)
Данный пример поясняет, зачем нужны объекты Locale. Передавая их методам, способным реагировать на региональные настройки, можно отображать текст на языке, понятном пользователю.
11.2. Форматирование числовых значений NumberFormat
Ранее упоминалось, что в разных странах и регионах используются различные способы представления чисел и денежных сумм. В пакете java.text содержатся классы, позволяющие форматировать числа и выполнять разбор их строкового представления. Для форматирования чисел в соответствии с конкретным региональным стандартом необходимо выполнить ряд действий:
-
Получить объект регионального стандарта, как было описано в предыдущем разделе.
-
Использовать фабричный метод для получения объекта форматирования.
-
Применить полученный объект форматирования для формирования числа или разбора его строкового представления.
В качестве фабричных методов (factory method) используются статические методы getNumberInstance(), getCurrencyInstance(), getPercentInstance() класса NumberFormat. Они получают в качестве параметра объект Locale и возвращают объекты, предназначенные для форматирования чисел, денежных сумм и значений, выраженных в процентах. Например, для отображения денежной суммы в формате, принятом в Германии, можно использовать приведенный ниже фрагмент кода:
Locale loc = new Locale("de", "DE");
NumberFormat currFmt;
currFmt = NumberFormat.getCurrencyInstance(loc);
double amt = 123456.78;
System.out.println (currFmt.format(amt));В результате выполнения этого кода будет получена следующая строка:
123.456,78€
Для обозначения евро здесь используется знак €, который располагается в конце строки. Кроме этого, следует обратить внимание на символы, применяемые для обозначения дробной части и разделения десятичных разрядов.
Для преобразования строки, записанной в соответствии с определенным региональным стандартом, в число предусмотрен метод parse(), который выполняет синтаксический анализ строки с автоматическим использованием заданного по умолчанию регионального стандарта. В приведенном ниже примере показан способ преобразования строки, введенной пользователем в поле редактирования, в число. Метод parse() способен преобразовывать числа, в которых в качестве разделителя используется точка и запятая.
TextField inputField;
// ...
NumberFormat fmt = NumberFormat.getNumberInstance();
// Получить объект форматирования для используемого по умолчанию регионального стандарта
Number input = fmt.parse(inputField.getText().trim());
double x = input.doubleValue();Метод parse() возвращает результат абстрактного типа Number. На самом деле возвращаемый объект является экземпляром класса Long или Double, в зависимости от того, представляет исходная строка целое число или число с плавающей точкой. Если это не важно, то для получения числового значения достаточно использовать метод doubleValue() класса Number.
|
Note
|
Для объектов типа Number не поддерживается автоматическое приведение к простым типам.
Необходимо явным образом вызывать метод doubleValue() или intValue().
|
Если число представлено в некорректном формате, генерируется исключение ParseException. Например, не допускается наличие символа пробела в начале строки, преобразуемой в число (для их удаления следует использовать метод trim()). Любые символы, которые располагаются в строке после числа, лишь игнорируются и исключение в этом случае не возникает.
Очевидно, что классы, возвращаемые методами get***Instance(), являются экземплярами не абстрактного класса NumberFormat, а одного из его подклассов. Фабричным методам известно лишь то, как найти объект, представляющий определенный региональный стандарт.
Для получения списка поддерживаемых региональных стандартов можно использовать статистический метод getAvailableLocales(), возвращающий массив региональных стандартов, для которых существуют объекты форматирования.
11.2.1. Методы пакета java.text.NumberFormat
| Метод | Описание |
|---|---|
|
Возвращает массив объектов |
|
Возвращает объект форматирования чисел, денежных сумм или величин, представленных в процентах, для текущего или заданного регионального стандарта |
|
|
|
|
|
|
|
|
|
|
|
Возвращает строку, полученную в результате форматирования заданного числа с плавающей точкой или целого числа. |
|
|
|
Возвращает число, полученное после преобразования строки. Это число может иметь тип |
|
Устанавливает или возвращает признак того, что данный объект форматирования предназначен для преобразования только целочисленных значений. |
|
|
|
Устанавливает или возвращает флаг, указывающий на то, что данный объект форматирования распознает символы разделения групп десятичных разрядов (например, |
|
|
|
Устанавливает или возвращает максимальное либо минимальное количество цифр в целой или дробной части числа |
|
|
|
|
|
|
|
|
|
|
|
|
|
11.3. Денежные суммы
Для форматирования денежных сумм используется метод getCurrencyInstance() класса NumberFormat. Однако этот метод не обеспечивает достаточной гибкости — он возвращает форматированную строку для одной валюты. Допустим, Вы выписываете счет для иностранного потребителя, в котором одни суммы представлены в долларах, а другие в евро. Использование двух приведенных ниже объектов форматирования не является решением задачи.
NumberFormat dollarFormatter = NumberFormat.getCurrencyInstance(Locale.US);
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.GERMANY);Счет, содержащий такие значения, как $100,000 и 100.000€, будет выглядеть достаточно странно, поскольку символы разделителей групп разрядов отличаются.
Для управления форматированием денежных сумм следует использовать класс Currency. Для получения объекта Currency необходимо передать статическому методу Currency.getInstance() идентификатор валюты. Затем необходимо вызвать метод setCurrency() каждого объекта форматирования. Ниже показано, как настроить объект форматирования евро для американского потребителя.
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.US);
euroFormatter.setCurrency(Currency.getInstance("EUR"));Идентификаторы валют определены стандартом ISO 4217. Некоторые из них приведены в таблице.
| Наименование валюты | Обозначение |
|---|---|
Белоруский рубль |
BYR |
Доллар США |
USD |
Евро |
EUR |
Английский фунт |
GBR |
Японская йена |
JPY |
Индийская рупия |
INR |
Российский рубль |
RUB |
11.3.1. Методы пакета java.util.Currency
| Метод | Описание |
|---|---|
|
Возвращает экземпляр класса |
|
|
|
Возвращает код ISO 4217 для данной валюты |
|
|
|
Возвращает символ, обозначающий данную валюту в соответствии или заданными региональными настройками. Например, в зависимости от объекта |
|
|
|
Возвращает число цифр в дробной части для данной валюты, принятое по умолчанию |
11.4. Форматирование даты и времени DateFormat
При форматировании даты и времени в соответствии с региональными стандартами следует иметь в виду четыре особенности:
-
названия месяцев и дней недели должны быть представлены на местном языке;
-
последовательность указания года, месяца и числа различаются для разных стран и регионов;
-
для отображения дат можно использовать календарь, отличный от григорианского;
-
следует учитывать часовые пояса.
Для учета перечисленных возможностей в Java имеется класс DateFormat, который используется почти также, как и класс NumberFormat. В первую очередь следует сформировать объект регионального стандарта. Для получения массива региональных стандартов, поддерживающих формат даты, можно использовать предлагаемый по умолчанию статический метод getAvailableLocales(). Далее необходимо вызвать один из трех фабричных методов:
fmt = DateFormat.getDateInstance(dateStyle, loc);
fmt = DateFormat.getTimeInstance(timeStyle, loc);
fmt = DateFormat.getDateTimeInstance(dateStyle, timeStyle, loc);Для указания нужного стиля предусмотрен параметр, в качестве которого задается одна из следующих констант:
DateFormat.DEFAULT;
DateFormat.FULL; // `Wednesday, Septemer 15 2004, 8:15:03 pm` для регионального стандарта США
DateFormat.LONG; // `Septemer 15, 2004 8:15:03 pm` для регионального стандарта США
DateFormat.MEDIUM; // `Sep 15, 2004 8:15:03 pm` для регионального стандарта США
DateFormat.SHORT; // `9/15/04 8:15 pm` для регионального стандарта СШАПредставленные выше фабричные методы возвращают объект, который можно использовать для форматирования даты.
Date date = new Date();
String s = fmt.format(date);Для преобразования строки в дату используется метод parse(), который работает аналогично одноименному методу класса NumberFormat. Например, приведенный ниже код преобразует строку, введенную пользователем в поле редактирования; при этом учитываются региональный настройки по умолчанию:
TextField inputField;
// ...
DateFormat fmt;
fmt = DateFormat.getDateInstance(DateFormat.MEDIUM);
Date input = fmt.parse(inputField.getText().trim());В случае некорректного ввода даты попытка преобразования приведет к генерации исключения ParseException. Следует отметить, что в начале строки, подлежащей преобразованию в дату также не допускаются пробелы. Для их удаления следует вызвать метод trim(). Любые символы, которые располагаются после даты, игнорируются. К сожалению, пользователь должен вводить дату в конкретном формате. Например, если установлен тип представления даты MEDIUM в региональном стандарте США, то предполагается, что введенная строка должна иметь вид Sep 18, 1997. Но если пользователь введет строку Sep 18 1997 (без запятой) или 9/18/97 (в кратком формате), то это приведет к ошибке преобразования.
Для интерпретации неточно указанных дат предусмотрен флаг lenient. Если данный флаг установлен, то неверно заданная дата February 30, 1999 будет автоматически преобразована в дату March 2, 1999. Такое поведение вряд ли можно считать безопасным, поэтому данный флаг следует отключить. В этом случае, при попытке пользователя ввести некорректное сочетание дня, месяца и года во время преобразования строки в дату будет сгенерировано исключение IllegalArgumentException.
11.5. Пакеты ресурсов resources
При локализации приложений необходимо переводить огромное количество сообщений, надписей интерфейса и т.п. Для упрощения задачи рекомендуется собрать все локализуемые строки в отдельном месте, которое называется ресурсом (resource). В этом случае достаточно отредактировать файлы ресурсов, не трогая исходный код программы.
В Java для определения строковых ресурсов используются файлы свойств, а для ресурсов других типов создаются классы ресурсов.
|
Note
|
Технология использования ресурсов в Java отличается от технологии использования ресурсов в операционных системах Windows и Macintosh. В выполняемой программе системы Windows такие ресурсы, как меню, диалоговые окна, пиктограммы и сообщения, хранятся отдельно от программы. Поэтому специальный редактор ресурсов позволяет просматривать и модифицировать их без изменения программного кода. |
|
Note
|
В Java технологии применяется концепция использования ресурсов, позволяющая размещать файлы данных, аудио файлы и изображения в JAR-архивах. Метод getResource() класса Class находит файл, открывает его и возвращает URL, указывающий на ресурс. При размещении файлов в JAR-архивах задачу поиска файлов решает загрузчик классов. Данный механизм обеспечивает поддержку региональных стандартов.
|
11.6. Определение файла ресурсов ResourceBundle
Для локализации приложений создаются так называемые пакеты ресурсов (resource bundle). Каждый пакет представляет собой файл свойств или класс, который описывает элементы, специфические для конкретного регионального стандарта (например, сообщения, надписи и т.д.). В каждый пакет помещаются ресурсы для всех региональных стандартов, поддержка которых предполагается в программе.
Для именования пакетов ресурсов используются специальные соглашения. Например, ресурсы, специфические для Германии, помещаются в файл с именем имяПакета_de_DE, а ресурсы, общие для стран, в которых используется немецкий язык, размещаются в классе имяПакета_de. Общие правила таковы: ресурсы для конкретной страны именуются по принципу:
имяПакета_язык_СТРАНА
Имя файла ресурсов для конкретного языка формируется так:
имяПакета_язык
Ресурсы, применяемые по умолчанию, помещаются в файл, имя которого не содержит суффикса. Для загрузки пакета ресурсов используется метод getBundle().
ResourceBundle bundle;
bundle = ResourceBundle.getBundle("ProgramResources", currentLocale)Метод getBundle() пытается загрузить информацию из пакета ресурсов, которая соответствует языку, расположению и варианту текущего регионального стандарта. Если попытка загрузки окончилась неудачей, последовательно отбрасывается вариант, страна и язык. Затем осуществляется поиск ресурса, соответствующего текущему региональному стандарту, и происходит обращение к пакету ресурсов по умолчанию. Если и эта попытка завершается неудачей, генерируется исключение MissingResourceException. Таким образом, метод getBundle() пытается загрузить первый доступный ресурс из перечисленных пакетов:
имяПакета_трс_язык_трс_СТРАНА_трс_вариант имяПакета_трс_язык_трс_СТРАНА имяПакета_трс_язык имяПакета_рсу_язык_рсу_СТРАНА_рсу_вариант имяПакета_рсу_язык_рсу_СТРАНА имяПакета_рсу_язык имяПакета
Здесь используются сокращения:
-
трс- текущий региональный стандарт; -
рсу- региональный стандарт по умолчанию.
Даже, если метод getBundle() находит пакет, например имяПакета_de_DE, он продолжает искать пакеты имяПакета_de, имяПакета. Если такие пакеты существуют, то они становятся родительскими по отношению к пакету имяПакета_de_DE в иерархии ресурсов. Родительские классы нужны в тех случаях, когда необходимый ресурс не найден в пакете имяПакета_de_DE, и выполняется поиск ресурса в пакетах имяПакета_de, имяПакета. Другими словами, поиск ресурса проверяется последовательно во всех пакетах до первого вхождения.
Очевидно, что это очень полезный механизм, однако для его реализации вручную программисту пришлось бы выполнить большой объем рутинной работы. Средства поддержки пакетов ресурсов Java автоматически находят ресурсы, наилучшим образом соответствующие конкретному региональному стандарту. Для включения в существующую программу новых локальных настроек необходимо всего лишь дополнить соответствующие пакеты ресурсов.
Создавая приложения, необязательно помещать все ресурсы в один пакет. Можно создать один пакет для надписей на кнопках, другой - для сообщений об ошибках и т.д.
11.7. Файлы свойств properties
Для интернационализации строк необходимо все строки поместить в файл свойств, например MyPackage.properties. Файл свойств - это обычный текстовый файл, каждая строка которого содержит ключ и значение. Пример содержимого такого файла приведен ниже:
colorName=black
PageSize=210x297
buttonName=InsertИмя файла выбирается по принципу, описанному в предыдущем разделе.
MyPackage.properties MyPackage_en.properties MyPackage_de_DE.properties
Для загрузки пакета ресурсов из файла свойств применяется приведенное ниже выражение:
ResourceBundle bundle;
bundle = ResourceBundle.getBundle("MyPackage", locale);Поиск конкретной строки выполняется следующим образом :
String label = bundle.getString ("PageSize");Файлы свойств могут содержать только ASCII-символы. Для размещения в них сомволов в кодировке Unicode следует использовать формат \uxxxx. Например, строка colorName=Зеленый для кириллицы будет иметь вид
colorName=\u0417\u0435\u043B\u0435\u043D\u044B\u043911.8. Классы, реализующие пакеты ресурсов
Для поддержки ресурсов, не являющихся строками, необходимо определить классы, являющиеся подклассами класса ResourceBundle. Выбор имен таких классов осуществляется в соответствии с соглашениями об именовании, например:
MyProgramResource.java MyProgramResource_en.java MyProgramResource_de_DE.java
Для загрузки класса используется тот же метод getBundle(), что и для загрузки свойств.
ResourceBoundle boundle = ResourceBoundle.getBundle ("MyProgrammResource", locale);Если два пакета ресурсов, один из которых реализован в виде класса, а другой в виде файла свойств имеют одинаковые имена, то при загрузке предпочтение отдается классу. В каждом классе, реализующем пакет ресурсов, поддерживается таблица поиска. Для получения значения используется строка-ключ.
Color background;
double[] paperSize;
background = (Color) bundle.getObject("backgroundColor");
paperSize = (double[])bundle.getObject("defaultPaperSize");Самый простой способ реализации пакета ресурсов — создание подкласса ListResourceBundle. Класс ListResourceBundle позволяет помещать все ресурсы в массив объектов и выполнять поиск. Подкласс класса ListResourceBundle должен иметь следующую структуру:
public class имяПакета_язык_СТРАНА extends ListResourceBundle {
private static final Objects[][] contents = {
{ключ1, значение1},
{ключ2, значение2},
// ...
};
public Object[][] getContents() {
return contents;
}
}Пример классов, созданных на базе ListResourceBundle, приведен ниже.
public class ProgramResources_de extends ListResourceBundle {
private static final Objects[][] contents = {
{"backgroundColor", Color.black},
{defaultPaperSize, new double[] {210, 297}}
};
public Object[][] getContents() {
return contents;
}
}public class ProgramResources_en_US extends ListResourceBundle {
private static final Objects[][] contents = {
{"backgroundColor", Color.blue},
{defaultPaperSize, new double[] {216, 279}}
};
public Object[][] getContents() {
return contents;
}
}Класс пакета ресурсов можно также создать как подкласс класса ResourceBundle. В этом случае необходимо реализовывать два метода, предназначенные для получения объекта Enumeration, содержащего ключи, и для извлечения значения, соответствующего конкретному ключу.
Enumeration <String> getKeys ();
Object handleGetObject (String key);Метод getObject() класса ResourceBundle вызывает определяемый разработчиком метод handleGetObject ().
11.8.1. Методы пакета java.util.ResourceBundle
|
Загружает класс пакета ресурсов с заданным именем, а также его родительские классы для указанного регионального стандарта. Если классы пакетов расположены в Java-пакете, то должно быть указано полное имя, например, |
|
|
|
Извлекает объект из пакета ресурсов или его родительских пакетов. |
|
Извлекает объект из пакета ресурсов или его родительских пакетов и приводит к типу |
|
Извлекает объект из пакета ресурсов или его родительских пакетов и представляет в виде массива строк. |
|
Возвращает объект |
|
При реализации собственного механизма поиска ресурсов, данный метод следует переопределить так, чтобы он возвращал значение, соответствующее указанному ключу. |
11.9. Форматирование сообщений MessageFormat
В библиотеке Java содержится класс MessageFormat, который форматирует текст, содержащий фрагменты, представленные посредством переменных. Например:
String template = "On {2}, a {0} destroyed {1} houses and caused {3} of damage.";В данном примере номера в фигурных скобках используются как "заполнители" для реальных имен и значений. Статический метод MessageFormat.format () позволяет подставить значения переменных. В JDK 5.0 поддерживаются методы с переменным числом параметров: таким образом, подстановка может быть выполнена так, как показано ниже.
String message;
message = MessageFormat.format(template, "hurricane", 99,
new GregorianCalendar(1999, 0, 1).getTime(), 10.0E7);В более старых версиях JDK необходимо было помещать значения в массив Object[]. В рассматриваемом примере переменная {0} замещается значением hurricane, переменная {1} заменяется значением 99 и т.д.
Статический метод format() форматирует значения с учетом текущего регионального стандарта. Для того, чтобы использовать класс MessageFormat с произвольными региональными настройками, необходимо поступить следующим образом:
MessageFormat mf = new MessageFormat(pattern locale);
String msg = mf.format(new Object[] { значения });Здесь вызывается метод format() суперкласса Format. К сожалению, класс MessageFormat не предоставляет аналогичный метод, обеспечивающий работу с переменным числом параметров. В результате обработки строки, рассматриваемой в качестве примера, будет получено следующее сообщение:
On 1/1/99 12:00 АМ, a hurricane destroyed 99 houses and caused 100,000,000 of damage.
Результат можно преобразовать, если сумму ущерба представить в денежных единицах, а дату с учетом формата:
String template = "On {2,date,long}, a {0} destroyed {1} "
+ "houses and caused {3,number,currency} of damage.";В результате будет получено сообщение:
On January 1, 1999, a hurricane destroyed 99 houses and caused $100,000,000 of damage.
В составе переменной допускается задавать тип и стиль, которые разделяются запятыми. Допустимыми значениями являются следующие типы: number, time, date, choice. Если указан тип number, то возможны следующие стили: integer, currency, percent. Кроме того, в качестве стиля может быть указан шаблон числового формата, например $,##0. Дополнительную информацию по данному вопросу можно найти в описании класса DecimalFormat.
Для типа time и date может быть указан один из следующих стилей: short, medium, long, full.
Аналогично числам, в качестве стиля может быть использован шаблон даты. Допустимые форматы подробно рассматриваются в описании класса SimpleDateFormat.
Форматы выбора (тип choice) имеют более сложную структуру и подробно рассматриваются далее.
11.9.1. Методы класса MessageFormat
| Наименование метода | Описание |
|---|---|
|
Создает объект форматирования сообщения согласно указанному шаблону и региональному стандарту. |
|
|
|
Задает шаблон для объекта форматирования. |
|
Устанавливает или возвращает региональный стандарт для переменных в составе сообщения. Он используется только для последующих шаблонов, заданных с помощью метода |
|
|
|
Форматирует строку согласно шаблону |
|
Форматирует шаблон данного объекта |
Класс java.text.Format имеет метод String format(Object object), который форматирует заданный объект в соответствии с правилами, определенными посредством текущего объекта форматирования. В процессе работы данный метод обращается к методу format(object, new StringBuffer(), new FieldPosition(1)).toString().
11.9.2. Формат выбора choice
Использование формата выбора предполагает определение последовательности пар значений, каждая из которых содержит нижнюю границу и строку подстановки. Нижняя граница и строка подстановки разделяются символами #, а для разделения пар значений используется символ |. Ниже приведен пример переменной с указанием формата выбора.
{1, choice, 0#no houses | 1#one house | 21 houses}
Результаты форматирования, в зависимости от значения {1}, представлены в следующей таблице.
| {1} | Результат |
|---|---|
|
|
|
|
|
|
|
|
Может возникнуть вопрос, а зачем в форматируемой строке дважды указывается переменная {1}? Когда для этой переменной применяется формат выбора и значение оказывается большим или равным 2, возвращается выражение {1} houses. Оно форматируется снова и включается в результирующую строку.
Данный пример показывает, что разработчики формата выбора приняли не самое лучшее решение. Если есть два варианта форматируемых строк, то для их разделения достаточно двух граничных значений, но согласно формату нужно задать три таких значения. Наименьшее из них никогда не используется. Синтаксис мог бы быть более понятным, если бы границы указывались между вариантами значений, например следующим образом:
no houses | 1|one house | 2{1} houses // к сожалению данный формат не поддерживается
С помощью символа < можно указать, что предполагаемый вариант должен быть выбран, если нижняя граница строго меньше значения.
Завершая пример о последствиях стихийного бедствия, необходимо поместить строку с условиями выбора внутри исходной строки сообщения. В результате получится следующая конструкция:
String pattern = "On {2, date, long}, {0} destroyed "
+ "{1, choice, 0#no houses | 1#one house | 21 houses} "
+ " and caused {3, number, currency} of damage.";В немецком варианте она будет выглядеть иначе.
String pattern = "{0} zerstörte am {2, date, long} "
+ "{1, choice, 0#kein Haus | 1#ein Haus | 21 Häuser} "
+ " und richtete einen Shaden von {3, number, currency} an.";Примечательно, что последовательность слов в английском и немецком вариантах разная, но методу format() передается тот же самый массив объектов. Под требуемый порядок слов подстраивается только последовательность появления переменных.
12. Форматирование строк
12.1. Класс Formatter
Базовой частью поддержки создания форматированного вывода в языке Java служит класс Formatter, включенный в пакет java.util. Он обеспечивает преобразования формата (format conversions) позволяющие выводить числа, строки и время и даты практически в любом понравившемся вам формате.
В классе Formatter объявлен метод format(), который преобразует переданные в него параметры в строку заданного формата и сохраняет в объекте типа Formatter.
Рассмотрим использование класса Formatter:
import java.util.Formatter;
public class SimpleFormatString {
public static void main(String[] args) {
Formatter f = new Formatter();
f.format("This %s is about %n%S %c", "book", "java", '8');
System.out.print(f);
}
}где %s называется спецификатором формата.
Следующий пример использует класс Formatter для отображения дробного числа:
import java.util.Formatter;
public class FormatDemo1 {
public static void main(String[] args) {
double x = 1000.0 / 3.0;
System.out.println("Строка без форматирования: " + x);
Formatter formatter = new Formatter();
formatter.format("Строка c форматированием: %.2f%n", x);
formatter.format("Строка c форматированием: %8.2f%n", x);
formatter.format("Строка c форматированием: %16.2f%n", x);
System.out.println(formatter);
}
}12.2. Метод format() классов String, PrintStream и PrintWriter
Аналогичный метод format() объявлен у классов PrintStream и PrintWriter. System.out это статическая переменная типа PrintStream.
В Java 5 для классов PrintStream и PrintWriter добавлен метод printf(). Методы printf() и format() автоматически используют класс Formatter:
public class FormatDemo4 {
public static void main(String[] args) {
System.out.printf("Строка c форматированием: %.2f%n", 1000.0 / 3.0);
System.out.format("%s, в следующем году вам будет %d", "Джон", 23);
}
}С помощью метода String.format() тоже возможно форматирование:
public class StringFormatDemo {
public static void main(String[] args) {
String str = String.format("Строка c форматированием: %16.2f", 1000.0 / 3.0);
System.out.println(str);
}
}12.3. Спецификаторы формата
-
%aШестнадцатеричное значение с плавающей точкой -
%bЛогическое (булево) значение аргумента -
%cСимвольное представление аргумента -
%dДесятичное целое значение аргумента -
%hХэш-код аргумента -
%eЭкспоненциальное представление аргумента -
%fДесятичное значение с плавающей точкой -
%gВыбирает более короткое представление из двух:%еили%f -
%oВосьмеричное целое значение аргумента -
%nВставка символа новой строки -
%sСтроковое представление аргумента -
%tВремя и дата -
%xШестнадцатеричное целое значение аргумента -
%%Вставка знака%
12.4. Флаги формата
-
-выравнивание влево -
#изменяет формат преобразования -
0выводит значение, дополненное нулями вместо пробелов. Применим только к числам -
` ` положительные числа предваряются пробелом
-
+положительные числа предваряются знаком +. Применим только к числам -
,числовые значения включают разделители групп. Применим только к числам -
(отрицательные числовые значения заключаются в скобки. Применим только к числам
Рассмотрим пример использования флагов:
public class FormatterDemo2 {
public static void main(String[] args) {
System.out.printf("%,.2f%n", 10000.0 / 3.0);
System.out.printf("%, (.2f%n", -10000.0 / 3.0);
System.out.printf("%09.2f%n", 10000.0 / 3.0);
}
}В строке, определяющей формат, может задаваться индекс форматируемого параметра. Индекс должен следовать непосредственно за символом % и завершаться знаком $:
public class FormatterDemo3 {
public static void main(String[] args) {
System.out.printf("Hello %1$s!%n%1$s, how are you?%n"
+ "Welcome to the site %2$s",
"John", "www.site.com");
}
}Общий синтаксис можно описать так:
%[аргумент_индекс][флаги][ширина][.точность]символ_преобразования13. Модульность (@since Java 9)
С выходом Java 9 появился новый уровень абстракции над пакетами, формально известный как Java Platform Module System (JPMS), или сокращенно Modules.
13.1. Что такое модуль?
Прежде всего, нам нужно понять, что такое модуль, прежде чем его использовать.
Модуль - это группа тесно связанных пакетов и ресурсов вместе с новым типом файла дескриптор модуля (module descriptor).
Другими словами, это абстракция пакет с Java-пакетами, которая позволяет сделать наш код более пригодным для повторного использования.
13.1.1. Пакеты
Пакеты внутри модуля идентичны пакетам Java, которые Java поддерживает с момента создания.
Когда создается модуль (фактически: проект), то код внутри организуется по пакетам, в зависимости от предназначения классов и связей между ними.
Помимо организации нашего кода, пакеты используются для определения того, какой код является общедоступным за пределами модуля, т.е. определяется API для данного модуля.
13.1.2. Ресурсы
Каждый модуль отвечает за свои ресурсы, такие как медиа или конфигурационные файлы.
Ранешь их помещали в корневой уровень проекта и вручную управляли тем, какие ресурсы и к каким частям приложения относились.
С помощью модулей можно поставлять необходимые ресурсы вместе с тем модулем, которому они необходимые. Это значительно упрощает управление проектами.
13.1.3. Дескриптор модуля
При создании модуля в него включается файл дескриптора(descriptor file), который определяет несколько аспектов нового модуля:
-
Name - название модуля
-
Dependencies - список модулей, от которых зависит этот модуль
-
Public Packages - список всех пакетов, которые можно получить вне этого модуля
-
Services Offered - предоставляет реализацию услуг (implementation of service), для использования другими модулями
-
Services Consumed - использует реализацию услуг из другого модуля
-
Reflection Permissions - позволяет другим классам использовать Reflection API для доступа к
privateчленам данного модуля
Правила именования модулей похожи на правила именования пакетов (точки разрешены, а тире нет). Обычно используют имена в стиле:
-
проекта (
my.module) -
Reverse-DNS(com.rakovets.mymodule).
Необходимо помнить, что нужно перечислить все пакеты:
-
которые будут общедоступными, потому что по умолчанию все пакеты являются module private
-
для которых будет доступна Reflection API, по тому что по умолчанию нельзя использовать рефлексию для классов, которые импортируются из другого модуля
13.1.4. Типы модулей
В новой модульной системе есть четыре типа модулей:
-
System Modules - это модули Java SE и JDK, которые можно увидеть с помощью команды
java --list-modules -
Application Modules - эти модули, которые необходимо использовать в текущем модуле. Они определены в скомпилированном файле
module-info.class, включенном в собранный JAR-file. -
Automatic Modules - это модули, которые включены в текущий неофициально, т.е. добавлением существующих JAR-файлов в путь к модулю. Название модуля будет производным от имени JAR-file. Эти модули будут иметь полный доступ для чтения ко всем аналогичным модулям
-
Unnamed Module - это универсальный модуль для обеспечения обратной совместимости с ранее написанным кодом Java. Он содержит классы или JAR-файлы загруженные в путь к классу, но не в путь к модулю
13.1.5. Распространение модуля
Модули, как и любой другой Java-проект, можно распространять в виде:
-
JAR-файла
-
«скомпонованного» скомпилированного проекта
Можно создавать многомодульные проекты, которые состоят из «основного приложения» и нескольких библиотечных модулей, но необходимо быть осторожны, потому что в JAR/project может быть только один модуль. Поэтому при настройке сборки (build), необходимо убедиться, что каждый модуль проекта упакован в отдельный JAR-файл.
13.2. Модули по умолчанию
Когда мы устанавливаем Java 9, мы видим, что JDK теперь имеет новую структуру.
Они взяли все оригинальные пакеты и перенесли их в новую систему модулей.
Мы можем увидеть, что это за модули, набрав в командной строке:
java --list-modulesЭти модули разделены на четыре основные группы:
-
java- содержит модули являются классами реализации для основной спецификации языка SE -
javafx- содержит библиотеки пользовательского интерфейса FX -
jdk- содержит все, что необходимо JDK -
oracle- содержит проприетарный функционал от Oracle
13.3. Объявления модуля
Чтобы создать модуль, нам нужно поместить специальный файл (дескриптор модуля/module descriptor) в корень наших пакетов с именем module-info.java. Он содержит всю информацию необходимую для построения и использования данного модуля.
Создание модуля с объявлением, тело которого либо пусто, либо содержит директивы модуля выглядит следующим образом:
module myModuleName {
// all directives are optional
}Объявление модуля начинается с ключевого слова module, далее указывается имя модуля. Этого достаточно для работы данного модуля, но обычно необходимо использовать другие модули и для этого существую директивы(directives) модуля.
13.3.1. Директива requires
Директива модуля requires позволяет объявлять зависимости модуля:
module my.module {
requires module.name;
}Теперь my.module имеет доступ во время кампиляции (Compile-time) и выполнение (Runtime) к зависимому модулю module.name. Все public типы из зависимого модуля, доступны в текущем модуле, благодаря использованию директивы requires.
13.3.2. Директива requires static
Иногда созданный модуль ссылается на другой модуль, но пользователи нашей библиотеки не хотят его использовать.
Например, написана служебная функция, которая красиво печатает внутреннее состояние наших объектов, когда есть зависимость от какого-то модуля логирования. Но не каждый потребитель нашей библиотеки захочет эту функциональность, и они не хотят включать дополнительную библиотеку логирорования.
В этих случаях можно использовать необязательную зависимость. Используя директиву require static, создается зависимость только во время компиляции:
module my.module {
requires static module.name;
}13.3.3. Директива requires transitive
В разработке часто используют сторонние библиотеки, чтобы сделать разработку проще. Но тогда нужно убедиться, что любой модуль, который будет использовать текущий модуль, также внесет эти дополнительные «транзитивные» зависимости, иначе модуль не будет работать.
Для этого можно использовать директиву requires transitive, чтобы заставить любых последующих потребителей использовать требуемые для текущего модуля зависимости:
module my.module {
requires transitive module.name;
}Теперь, когда кому-то необходим модуль my.module, то не требуется добавлять и module.name в зависимости для того, чтобы все работало корректно.
13.3.4. Директива exports
По умолчанию, модуль не предоставляет API другим модулям. Эта сильная инкапсуляция(strong encapsulation) являлась одним из ключевых факторов для создания модульной системы и это делает код значительно более безопасным, но теперь нужно явно открывать API для потребителей.
Что бы открыть API из конкретного пакета используется директива exports:
module my.module {
exports com.my.package.name;
}Теперь у потребителей my.module, будет доступ к public типам из пакета com.my.package.name, но не из любого другом.
13.3.5. Директива export … to
С помощью директивы export можно открыть API для потребителя, но что, если нужно, чтобы не все имели доступ к нашему API?
Можно ограничить то, какие модули имеют доступ к API. Для этого используется директива export … to.
Подобно директиве export, объявляется какой пакет экспортировать, но так же перечисляется, каким модулям разрешаем импортировать этот пакет:
module my.module {
export com.my.package.name to com.specific.package;
}13.3.6. Директива uses
Сервис обычно является реализацией определенного интерфейса или абстрактного класса, который может использоваться другими классами. Для обозначения сервисов, которые использует модуль, используется директива uses. Стоит обратить внимание, что в качестве имени класса мы используем интерфейс или абстрактный класс, который реализует service:
module my.module {
uses class.name;
}Следует отметить, что существует разница между директивой requires и директивой uses.Когда в модуле содержится сервис, который необходимо использовать, но этот сервис реализует интерфейс или абстрактный класс одной из своих транзитивных зависимостей, тогда вместо использования директивы requires для всех транзитивных зависимостей, используется директива uses для добавления необходимого интерфейса или абстрактного класса к модулю.
13.3.7. Директива provides … with
Модуль может быть поставщиком сервиса, который могут использовать другие модули. Для данного случая применяют директиву provides … with
Директива содержит ключевое слово provides, после чего указывается имя интерфейса или абстрактного класса. Далее следует with, после которого указывается имя класса реализации для интерфейса, либо наследника для абстрактного класса.
module my.module {
provides MyInterface with MyInterfaceImpl;
}13.3.8. Директива open
До Java 9 было возможно использовать Reflection API по отношению к любым классам, полям и методам, даже когда они имели модификатор доступа private, т.е. фактически реальной инкапсуляции небыло.
Поскольку Java 9 обеспечивает строгую инкапсуляцию, то теперь необходимо явно указать разрешение другим модулям использовать Reflection API по отношению к содержимому данного модулю.
open module my.module {
}13.3.9. Директива opens
Если необходимо разрешить использовать Reflection API, но не для всего модуля, то используется директивa opens, которая предоставит эту возможность к определенному пакету.
module my.module {
opens com.my.package;
}13.3.10. Директива opens … to
Если необходима более сильная инкапсуляция, то можно выборочно открывать пакеты для указанных модулей. Для этого используют директиву opens … to:
module my.module {
opens com.my.package to moduleOne, moduleTwo, etc.;
}13.4. Параметры командной строки
В настоящее времени поддержка модулей Java 9 была добавлена в Maven и Gradle, поэтому нет необходимости делать много ручной работы для сборки проектов. Однако полезно знать, как использовать систему модулей из командной строки. Для этого используют следующие параметры при работе в командной строке:
-
module-path- используется для указания пути к модулю. Список из одного или нескольких директорий, которые содержат необходимые модули -
add-reads- объявляет зависимость от модуля (аналогично директивеrequires) -
add-exports- предоставляет доступ к API (аналогично директивеexports) -
add-opens- разрешает прмменение Reflection API (аналогично директивеopen) -
add-modules- добавляет список модулей в набор модулей по умолчанию -
list-modules- выводит список всех модулей и их версий -
patch-module- добавляет или переопределяет классы в модулях -
illegal-access=permit|warn|deny- либо ослабляет сильную инкапсуляцию показывая одно глобальное предупреждение, либо показывает каждое предупреждение, либо выдает ошибку (по умолчаниюpermit)
13.5. Видимость
Многие библиотеки, что бы работать, зависят от возможности использования Reflection API, например: JUnit и Spring.
По умолчанию в Java 9 доступ предоставляется только к public классам, методам и полям в экспортируемых пакетах. Даже если использовать reflection, чтобы получить доступ к private членам с вызовом setAccessible(true), то нельзя получить доступ к этим членам.
В таком случае можно использовать директивы open, opens, и opens … to для предоставления доступа использовать reflection в Runtime. Однако не в compile-time.
Для этого у нас должен быть доступ к модулю. Когда же доступа к модулю нет (т.е. это сторонний модуль), тогда можно использовать параметр -add-opens в командной строке для предоставления доступа собственных модулей к инкапсулированному модулю в Runtime. Но необходимо помнить, что нужно иметь доступ к аргументам командной строки, которые используются для запуска модуля.
13.6. Создание модуля с помощью CLI
13.6.1. Создание структуры проекта
Создадим несколько каталогов для организации файлов.
Создадим директорию с проектом:
mkdir module-project
cd module-projectЭто root директория проекта, поэтому она будет содержать в дальнейшем файлы сборки Maven или Gradle, другие source и resource директории.
Мы также поместили каталог для хранения всех модулей нашего проекта.
Далее создадим каталог модуля:
mkdir simple-modulesВот как будет выглядеть структура проекта:
module-project
|- // src if we use the default package
|- // build files also go at this level
+- simple-modules
+- hello.modules
+- com
+- rakovets
+- modules
+- hello
+- main.app
+- com
+- rakovets
+- modules
+- main13.6.2. Первый модуль
Когда есть базовая структура, можно добавить первый модуль.
В директории simple-modules создадим новую директорию с именем hello.modules .
Ее можно назвать как угодно, но необходимо следовать правилам именования пакетов (т.е. точки для разделения пакетов и т.д.). Можно использовать имя основного пакета в качестве имени модуля, если необходимо, но обычно придерживаются того же имени, которое необходимо использовать при создании JAR-файла этого модуля.
В новом модуле можно создавать нужные пакеты. В текущем случае создим следующую структуру пакета:
com.rakovets.modules.helloЗатем в этом пакете создадим новый класс с именем HelloModules.java. Этот клас будет содержать очень простой код:
package com.rakovets.modules.hello;
public class HelloModules {
public static void doSomething() {
System.out.println("Hello, Modules!");
}
}Затем в корневой директори hello.modules добавим дескриптор модуля module-info.java:
module hello.modules {
exports com.rakovets.modules.hello;
}Для простоты только экспортируем все открытые члены пакета com.rakovets.modules.hello.
13.6.3. Второй модуль
Первый самостоятельно ничего не делает. Создадим второй модуль, который будет использовать функционал первого.
В директории simple-modules создадим еще одну директорию для модуля с именем main.app и добавим дескриптор модуля:
module main.app {
requires hello.modules;
}Второй модуль не будет предоставлять API, он только будет использовать первый модуль.
Для этого создадим новую структуру пакетов com.rakovets.modules.main.
Затем создадим новый файл класса с именем MainApp.java.
package com.rakovets.modules.main;
import com.rakovets.modules.hello.HelloModules;
public class MainApp {
public static void main(String[] args) {
HelloModules.doSomething();
}
}Это продемонстрирует принцип создания модулей.
13.6.4. Сборка модулей
Что бы сделать build проекта, можно создать bash-скрипт и поместить его в корень проекта.
Создадим файл с именем compile-simple-modules.sh:
#!/usr/bin/env bash
javac -d outDir --module-source-path simple-modules $(find simple-modules -name "*.java")Команда состоит из двух команд:
-
javac- компилирует все java-файлы, которые были найдены с помощью командыfind -
find- выводит список всех java-файлов в директорииsimple-modules
Единственное отличие от более старых версий Java, это необходимость предоставить параметр module-source-path, чтобы сообщить компилятору о том, что он делает build модулей.
Как только команда будет запущена, появится директория outDir с двумя скомпилированными модулями внутри.
13.6.5. Запуск
Что бы проверить работоспособность модулей необходимо запусти проект.
Создадим bash-скрипт в корне проекта `run-simple-module-app.sh:
#!/usr/bin/env bash
java --module-path outDir -m main.app/com.rakovets.modules.main.MainAppЧтобы запустить модуль, необходимо указать путь к модулю и основному классу. Запустим и если все верно, то увидим:
./run-simple-module-app.sh
Hello, Modules!13.6.6. Добавление сервиса
Усложним проект, добавив в него service. Для этого используем директивы:
-
provides…with -
uses
Определим новый файл в модуле hello.modules с именем HelloInterface.java:
public interface HelloInterface {
void sayHello();
}Реализуем интерфейс в существующем классе HelloModules.java:
public class HelloModules implements HelloInterface {
public static void doSomething() {
System.out.println("Hello, Modules!");
}
public void sayHello() {
System.out.println("Hello!");
}
}Необходимый service создан. Теперь необходимо указать что модуль предоставляет этот service. Для этого добавим в module-info.java следующее:
provides com.rakovets.modules.hello.HelloInterface with com.rakovets.modules.hello.HelloModules;Т.е. объявили интерфейс и класс, который его реализует.
В модуле main.app, для использования этого service нужно добавить следующее в module-info.java:
uses com.rakovets.modules.hello.HelloInterface;Теперо в main методе можно использовать этот service:
HelloModules module = new HelloModules();
module.sayHello();Компилируем и запускаем:
./run-simple-module-app.sh
Hello, Modules!
Hello!Так же можно поместить реализацию в приватный пакет, а интерфейс в публичный пакет. Это сделает наш код более безопасным при минимальных усилиях.
13.7. Добавление модулей в Unnamed Module
Концепция Unnamed Module похожа на пакет по умолчанию, поэтому его не следует считать реальным модулем, но можно рассматриваться как модуль по умолчанию.
Если класс не является членом других типов модулей, то он будет автоматически рассматриваться как часть Unnamed Module.
Иногда, чтобы обеспечить наличие определенных модулей платформы, библиотеки или поставщика услуг в графе модулей, нужно добавить модули в набор по умолчанию. Например, когда пытаемся работать с программами на Java 8 используя компилятор Java 9, тогда может потребоваться добавить модули.
Возможность добавления именованных модулей в набор корневых модулей по умолчанию выглядит -add-modules <module>, …, <module>, где <module> - это имя модуля.
Например, чтобы обеспечить доступ всех модулей к модулю java.xml.bind, синтаксис должен быть следующим:
--add-modules java.xml.bindЧтобы использовать это с помощью Maven, необходимо добавит это в конфигурацию для maven-compiler-plugin:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>9</source>
<target>9</target>
<compilerArgs>
<arg>--add-modules</arg>
<arg>java.xml.bind</arg>
</compilerArgs>
</configuration>
</plugin>