1. Типы коллекций
Для хранения наборов данных в Java предназначены массивы. Однако их не всегда удобно использовать, прежде всего потому, что они имеют фиксированную длину. Эту проблему в Java решают коллекции. Однако суть не только в гибких по размеру наборах объектов, но в и том, что классы коллекций реализуют различные алгоритмы и структуры данных, например: стек, очередь, дерево и ряд других.
Классы коллекций располагаются в пакете java.util, поэтому перед применением коллекций следует подключить данный пакет.
Хотя в Java существует множество коллекций, но все они образуют стройную и логичную систему. Во-первых, в основе всех коллекций лежит применение того или иного интерфейса, который определяет базовый функционал. Среди этих интерфейсов можно выделить следующие:
-
Collectionбазовый интерфейс для всех коллекций и других интерфейсов коллекций -
Queue: наследует интерфейсCollectionи представляет функционал для структур данных в виде очереди -
Deque: наследует интерфейсQueueи представляет функционал для двунаправленных очередей -
List: наследует интерфейсCollectionи представляет функциональность простых списков -
Set: также расширяет интерфейсCollectionи используется для хранения множеств уникальных объектов -
SortedSet: расширяет интерфейс Set для создания сортированных коллекций -
NavigableSet: расширяет интерфейс SortedSet для создания коллекций, в которых можно осуществлять поиск по соответствию -
Map: предназначен для созданий структур данных в виде словаря, где каждый элемент имеет определенный ключ и значение. В отличие от других интерфейсов коллекций не наследуется от интерфейсаCollection
Эти интерфейсы частично реализуются абстрактными классами:
-
AbstractCollection: базовый абстрактный класс для других коллекций, который применяет интерфейсCollection -
AbstractList: расширяет классAbstractCollectionи применяет интерфейсList, предназначен для создания коллекций в виде списков -
AbstractSet: расширяет классAbstractCollectionи применяет интерфейсSetдля создания коллекций в виде множеств -
AbstractQueue: расширяет классAbstractCollectionи применяет интерфейсQueue, предназначен для создания коллекций в виде очередей и стеков -
AbstractSequentialList: также расширяет классAbstractList, и реализует интерфейсList. Используется для создания связанных списков -
AbstractMap: применяет интерфейсMap, предназначен для создания наборов по типу словаря с объектами в виде парыkey-value
С помощью применения вышеописанных интерфейсов и абстрактных классов в Java реализуется широкая палитра классов коллекций - списки, множества, очереди, отображения и другие, среди которых можно выделить следующие:
-
ArrayList: простой список объектов -
LinkedList: представляет связанный список -
ArrayDeque: класс двунаправленной очереди, в которой мы можем произвести вставку и удаление как в начале коллекции, так и в ее конце -
HashSet: набор объектов или хеш-множество, где каждый элемент имеет ключ - уникальный хеш-код -
TreeSet: набор отсортированных объектов в виде дерева -
LinkedHashSet: связанное хеш-множество -
PriorityQueue: очередь приоритетов -
HashMap: структура данных в виде словаря, в котором каждый объект имеет уникальный ключ и некоторое значение -
TreeMap: структура данных в виде дерева, где каждый элемент имеет уникальный ключ и некоторое значение
Схематично всю систему можно представить следующим образом:
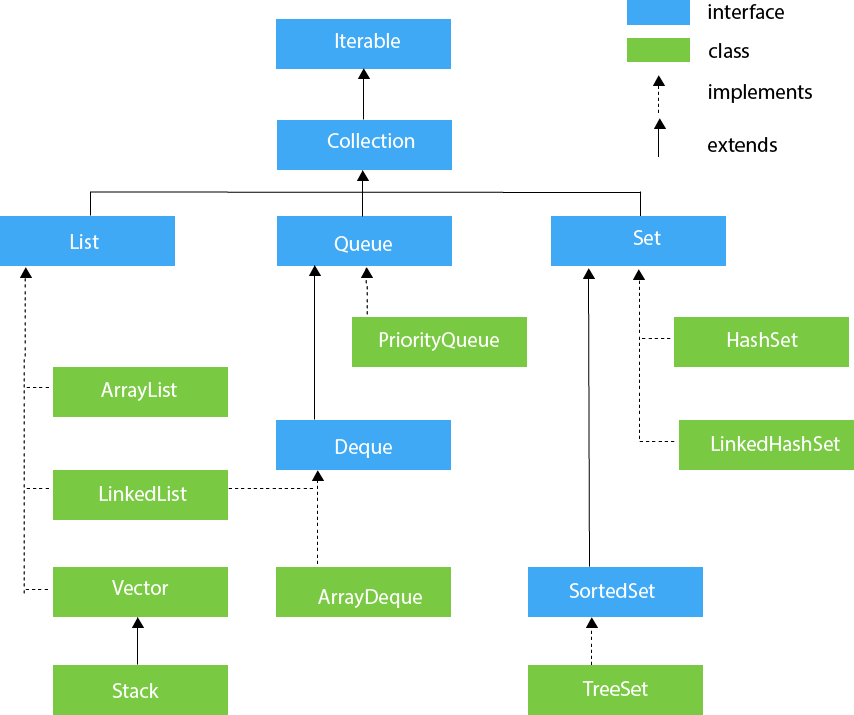
Следует отметить, что в отличие от других интерфейсов, которые представляют коллекции, интерфейс Map НЕ расширяет интерфейс Collection.

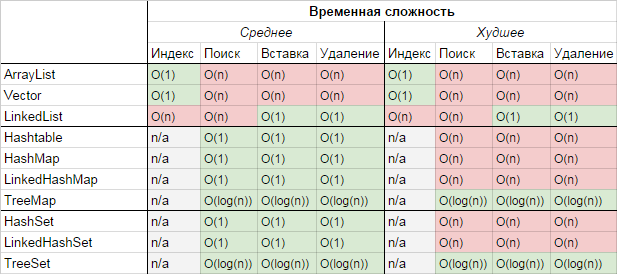
1.1. Алгоритмическая сложность операций в коллекциях
Важным критерием при выборе используемой коллекции является ее алгоритмическая сложность (bigO). Но всецело полагаться на нее не стоит, потому что многое зависит от конкретной ситуации использование, в частности: объема коллекции, частоты операций, требований к памяти и производительности. Так же следует обратить внимание, что несмотря на алгоритмическую сложность, некоторые операции могут работать быстрее чем ожидалось, так как Java имеет некоторые оптимизации на уровне JVM.
1.2. Interface Collection
Интерфейс Collection является базовым для всех коллекций, определяя основной функционал:
public interface Collection<E> extends Iterable<E>{
// определения методов
}Интерфейс Collection является обобщенным и расширяет интерфейс Iterable, поэтому все объекты коллекций можно перебирать в цикле по типу for-each.
Среди методов интерфейса Collection можно выделить следующие:
-
boolean add(E item): добавляет в коллекцию объектitem. При удачном добавлении возвращаетtrue, при неудачном -false -
boolean addAll(Collection<? extends E> col): добавляет в коллекцию все элементы из коллекцииcol. При удачном добавлении возвращаетtrue, при неудачном -false -
void clear(): удаляет все элементы из коллекции -
boolean contains(Object item): возвращаетtrue, если объектitemсодержится в коллекции, иначе возвращаетfalse -
boolean isEmpty(): возвращаетtrue, если коллекция пуста, иначе возвращаетfalse -
Iterator<E> iterator(): возвращает объект Iterator для обхода элементов коллекции -
boolean remove(Object item): возвращаетtrue, если объектitemудачно удален из коллекции, иначе возвращаетсяfalse -
boolean removeAll(Collection<?> col): удаляет все объекты коллекцииcolиз текущей коллекции. Если текущая коллекция изменилась, возвращаетtrue, иначе возвращаетсяfalse -
boolean retainAll(Collection<?> col): удаляет все объекты из текущей коллекции, кроме тех, которые содержатся в коллекцииcol. Если текущая коллекция после удаления изменилась, возвращаетtrue, иначе возвращаетсяfalse -
int size(): возвращает число элементов в коллекции -
Object[] toArray(): возвращает массив, содержащий все элементы коллекции
Все эти и остальные методы, которые имеются в интерфейсе Collection, реализуются всеми коллекциями, поэтому в целом общие принципы работы с коллекциями будут одни и те же. Единообразный интерфейс упрощает понимание и работу с различными типами коллекций. Так, добавление элемента будет производиться с помощью метода add(), который принимает добавляемый элемент в качестве параметра. Для удаления вызывается метод remove(). Метод clear() будет очищать коллекцию, а метод size() возвращать количество элементов в коллекции.
2. Interface Iterator
Одним из ключевых методов интерфейса Collection, который он унаследовал от интерфейса Iterable является метод Iterator<E> iterator(). Он возвращает итератор - то есть объект, реализующий интерфейс Iterator.
Интерфейс Iterator имеет следующее определение:
public interface Iterator <E> {
E next();
boolean hasNext();
void remove();
}Реализация интерфейса предполагает, что с помощью вызова метода next() можно получить следующий элемент. С помощью метода hasNext() можно узнать, есть ли следующий элемент, и не достигнут ли конец коллекции. И если элементы еще имеются, то hasNext() вернет значение true. Метод hasNext() следует вызывать перед методом next(), так как при достижении конца коллекции метод next() выбрасывает исключение NoSuchElementException. И метод remove() удаляет текущий элемент, который был получен последним вызовом next().
Используем итератор для перебора коллекции ArrayList:
import java.util.ArrayList;
import java.util.Iterator;
public class Program {
public static void main(String[] args) {
ArrayList<String> states = new ArrayList<String>();
states.add("Germany");
states.add("France");
states.add("Italy");
states.add("Spain");
Iterator<String> iter = states.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
}
}3. Interface List
Для создания простых списков применяется интерфейс List, который расширяет функциональность интерфейса Collection. Некоторые наиболее часто используемые методы интерфейса List:
-
void add(int index, E obj)добавляет в список по индексуindexобъектobj -
boolean addAll(int index, Collection<? extends E> col)добавляет в список по индексуindexвсе элементы коллекцииcol. Если в результате добавления список был изменен, то возвращаетсяtrue, иначе возвращаетсяfalse -
E get(int index)возвращает объект из списка по индексуindex -
int indexOf(Object obj)возвращает индекс первого вхождения объектаobjв список. Если объект не найден, то возвращается-1 -
int lastIndexOf(Object obj)возвращает индекс последнего вхождения объектаobjв список. Если объект не найден, то возвращается-1 -
ListIterator<E> listIterator ()возвращает объектListIteratorдля обхода элементов списка -
static <E> List<E> of(Object …)создает из набора элементов объектList -
E remove(int index)удаляет объект из списка по индексуindex, возвращая при этом удаленный объект -
E set(int index, E obj)присваивает значение объектаobjэлементу, который находится по индексуindex -
void sort(Comparator<? super E> comp)сортирует список с помощью компаратораcomp -
List<E> subList(int start, int end)получает набор элементов, которые находятся в списке между индексамиstartиend
4. Interface ListIterator
Интерфейс Iterator предоставляет ограниченный функционал. Гораздо больший набор методов предоставляет другой итератор - интерфейс ListIterator. Данный итератор используется классами, реализующими интерфейс List, то есть классами LinkedList, ArrayList и др.
Интерфейс ListIterator расширяет интерфейс Iterator и определяет ряд дополнительных методов:
-
void add(E obj)вставляет объектobjперед элементом, который должен быть возвращен следующим вызовомnext() -
boolean hasNext()возвращаетtrue, если в коллекции имеется следующий элемент, иначе возвращаетfalse -
boolean hasPrevious()возвращаетtrue, если в коллекции имеется предыдущий элемент, иначе возвращаетfalse -
E next()возвращает текущий элемент и переходит к следующему, если такого нет, то генерируется исключениеNoSuchElementException -
E previous()возвращает текущий элемент и переходит к предыдущему, если такого нет, то генерируется исключениеNoSuchElementException -
int nextIndex()возвращает индекс следующего элемента. Если такого нет, то возвращается размер списка -
int previousIndex()возвращает индекс предыдущего элемента. Если такого нет, то возвращается число-1 -
void remove()удаляет текущий элемент из списка. Таким образом, этот метод должен быть вызван после методовnext()илиprevious(), иначе будет сгенерировано исключениеIllegalStateException -
void set(E obj)присваивает текущему элементу, выбранному вызовом методовnext()илиprevious(), ссылку на объектobj
Используем ListIterator:
import java.util.ArrayList;
import java.util.ListIterator;
public class Program {
public static void main(String[] args) {
ArrayList<String> states = new ArrayList<String>();
states.add("Germany");
states.add("France");
states.add("Italy");
states.add("Spain");
ListIterator<String> listIter = states.listIterator();
while (listIter.hasNext()) {
System.out.println(listIter.next());
}
// сейчас текущий элемент - Испания
// изменим значение этого элемента
listIter.set("Португалия");
// пройдемся по элементам в обратном порядке
while (listIter.hasPrevious()) {
System.out.println(listIter.previous());
}
}
}5. Class ArrayList
По умолчанию в Java есть встроенная реализация этого интерфейса - класс ArrayList. Класс ArrayList представляет обобщенную коллекцию, которая наследует свою функциональность от класса AbstractList и применяет интерфейс List. Проще говоря, ArrayList представляет простой список, аналогичный массиву, за тем исключением, что количество элементов в нем не фиксировано.
ArrayList имеет следующие конструкторы`:
-
ArrayList()создает пустой список -
ArrayList(Collection <? extends E> col)создает список, в который добавляются все элементы коллекцииcol -
ArrayList (int capacity)создает список, который имеет начальную емкостьcapacity
Емкость в ArrayList представляет размер массива, который будет использоваться для хранения объектов. При добавлении элементов фактически происходит перераспределение памяти - создание нового массива и копирование в него элементов из старого массива. Изначальное задание емкости ArrayList позволяет снизить подобные перераспределения памяти, тем самым повышая производительность.
Используем класс ArrayList и некоторые его методы в программе:
import java.util.ArrayList;
public class Program {
public static void main(String[] args) {
ArrayList<String> people = new ArrayList<String>();
// добавим в список ряд элементов
people.add("Tom");
people.add("Alice");
people.add("Kate");
people.add("Sam");
people.add(1, "Bob"); // добавляем элемент по индексу 1
System.out.println(people.get(1));// получаем 2-й объект
people.set(1, "Robert"); // установка нового значения для 2-го объекта
System.out.printf("ArrayList has %d elements \n", people.size());
for (String person : people) {
System.out.println(person);
}
// проверяем наличие элемента
if (people.contains("Tom")) {
System.out.println("ArrayList contains Tom");
}
// удалим несколько объектов
// удаление конкретного элемента
people.remove("Robert");
// удаление по индексу
people.remove(0);
Object[] peopleArray = people.toArray();
for (Object person : peopleArray) {
System.out.println(person);
}
}
}Здесь объект ArrayList типизируется классом String, поэтому список будет хранить только строки. Поскольку класс ArrayList применяет интерфейс Collection<E>, то мы можем использовать методы данного интерфейса для управления объектами в списке.
Для добавления вызывается метод add(). С его помощью мы можем добавлять объект в конец списка. Также мы можем добавить объект на определенное место в списке. Например:
people.add("Tom") // добавит элемент в конец списка
people.add(1, "Bob") // добавит элемент на 1 позицию в спискеМетод size() позволяет узнать количество объектов в коллекции.
Проверку на наличие элемента в коллекции производится с помощью метода contains(). А удаление с помощью метода remove(). Например:
people.remove("Tom") // удаление элемента с данным значением из списка
people.remove(0) // удаление элемента на 0 позиции в спискеПолучить определенный элемент по индексу мы можем с помощью метода get(), а установить элемент по индексу с помощью метода set. Например:
String person = people.get(1);
people.set(1, "Robert");С помощью метода toArray() мы можем преобразовать список в массив объектов.
И поскольку класс ArrayList реализует интерфейс Iterable, то мы можем пробежаться по списку в цикле типа for-each:
for(String person : people) {
// some opeartors
}Хотя мы можем свободно добавлять в объект ArrayList дополнительные объекты, в отличие от массива, однако в реальности ArrayList использует для хранения объектов опять же массив. По умолчанию данный массив предназначен для 10 объектов. Если в процессе программы добавляется гораздо больше, то создается новый массив, который может вместить в себя все количество. Подобные перераспределения памяти уменьшают производительность. Поэтому если мы точно знаем, что у нас список не будет содержать больше определенного количества элементов, например, 25, то мы можем сразу же явным образом установить это количество, либо в конструкторе: ArrayList<String> people = new ArrayList<String>(25);, либо с помощью метода ensureCapacity: people.ensureCapacity(25);
5.1. ArrayList как структура данных
5.1.1. Создание
ArrayList<String> list = new ArrayList<String>();Только что созданный объект list содержит свойства elementData и size.
Хранилище значений elementData есть не что иное, как массив определенного типа (указанного с помощью generic), в данном случае String[]. Если вызывается конструктор без параметров, то по умолчанию будет создан массив из десяти элементов типа Object (с приведением к типу, разумеется).
elementData = (E[]) new Object[10];
ArrayList после создания5.1.2. Добавление элементов
Добавим новый элемент:
list.add("0");
ArrayList после добавления одного элементаВнутри метода add(value) происходят следующие вещи:
-
проверяется, достаточно ли места в массиве для вставки нового элемента;
ensureCapacity(size + 1);-
добавляется элемент в конец (согласно значению
size) массива.
elementData[size++] = element;Если места в массиве не достаточно, новая ёмкость рассчитывается по формуле (oldCapacity * 3) / 2 + 1. Второй момент это копирование элементов. Оно осуществляется с помощью native-метода System.arraycopy(), который написан не на Java.
// newCapacity - новое значение емкости
elementData = (E[])new Object[newCapacity];
// oldData - временное хранилище текущего массива с данными
System.arraycopy(oldData, 0, elementData, 0, size);Если массив заполнен:

ArrayListТо при добавлении нового элемента, проверка покажет что места в массиве нет. Соответственно создается новый массив и вызывается System.arraycopy().
list.add("10");
ArrayList после изменения размераПосле этого добавление элементов продолжается.

ArrayList с новым размером5.1.3. Добавление элемента в середину
Добавление элементов в середину ArrayList происходит следующим образом:
list.add(5, "100");Добавление элемента на позицию с определенным индексом происходит в три этапа:
-
проверяется, достаточно ли места в массиве для вставки нового элемента;
ensureCapacity(size + 1);-
подготавливается место для нового элемента с помощью
System.arraycopy();
System.arraycopy(elementData, index, elementData, index + 1, size - index);
ArrayList-
перезаписывается значение у элемента с указанным индексом.
elementData[index] = element;
size++;
В случаях, когда происходит вставка элемента по индексу и при этом в вашем массиве нет свободных мест, то вызов System.arraycopy() случится дважды: первый в ensureCapacity(), второй в самом методе add(index, value), что явно скажется на скорости всей операции добавления.
В случаях, когда в исходный список необходимо добавить другую коллекцию, да еще и в «середину», стоит использовать метод addAll(index, Collection). И хотя, данный метод вызовет System.arraycopy() три раза, в итоге это будет гораздо быстрее поэлементного добавления.
5.1.4. Удаление элемента
Удалять элементы можно двумя способами:
-
по индексу
remove(index) -
по значению
remove(value)
С удалением элемента по индексу всё достаточно просто:
list.remove(5);Сначала определяется какое количество элементов надо скопировать:
int numMoved = size - index - 1;Затем копируем элементы используя System.arraycopy():
System.arraycopy(elementData, index + 1, elementData, index, numMoved);Уменьшаем размер массива и забываем про последний элемент:
elementData[--size] = null;При удалении по значению, в цикле просматриваются все элементы списка, до тех пор пока не будет найдено соответствие. Удален будет лишь первый найденный элемент.
При удалении элементов текущая величина capacity не уменьшается, что может привести к своеобразным утечкам памяти. Поэтому не стоит пренебрегать методом trimToSize(), для того, что бы уменьшить размер памяти, выделенный для ArrayList, к размеру памяти требуемому для хранения его элементов.
6. Interface Comparable and Comparator
6.1. Interface Comparable
Рассмотрим коллекции TreeSet, типизированную объектами String. При добавлении новых элементов объект TreeSet автоматически проводит сортировку, помещая новый объект на правильное для него место. Что если бы использовались не строки, а классы, например, следующий класс Person:
class Person {
private String name;
Person(String name) {
this.name = name;
}
String getName() {
return name;
}
}Объект TreeSet нельзя типизировать данным классом, поскольку в случае добавления объектов TreeSet не будет знать, как их сравнивать, и следующий код не будет работать:
TreeSet<Person> people = new TreeSet<Person>();
people.add(new Person("Tom"));При выполнении этого кода возникнет ошибка, которая скажет, что объект Person не может быть преобразован к типу java.lang.Comparable.
Для того, чтобы объекты Person можно было сравнить и сортировать, они должны применять интерфейс Comparable<E>. При применении интерфейса он типизируется текущим классом. Применим его к классу Person:
class Person implements Comparable<Person> {
private String name;
Person(String name) {
this.name = name;
}
String getName() {
return name;
}
public int compareTo(Person p) {
return name.compareTo(p.getName());
}
}Интерфейс Comparable содержит один единственный метод int compareTo(E item), который сравнивает текущий объект с объектом, переданным в качестве параметра. Если этот метод возвращает отрицательное число, то текущий объект будет располагаться перед тем, который передается через параметр. Если метод вернет положительное число, то, наоборот, после второго объекта. Если метод возвратит 0, значит, оба объекта равны.
В данном случае мы не возвращаем явным образом никакое число, а полагаемся на встроенный механизм сравнения, который есть у класса String. Но мы также можем определить и свою логику, например, сравнивать по длине имени:
public int compareTo(Person p) {
return name.length() - p.getName().length();
}Теперь можно типизировать TreeSet типом Person и добавлять в дерево соответствующие объекты:
TreeSet<Person> people = new TreeSet<Person>();
people.add(new Person("Tom"));6.2. Interface Comparator
Однако перед нами может возникнуть проблема, что если разработчик не реализовал в своем классе, который мы хотим использовать, интерфейс Comparable, либо реализовал, но нас не устраивает его функциональность, и мы хотим ее переопределить? На этот случай есть еще более гибкий способ, предполагающий применение интерфейса Comparator<E>.
Интерфейс Comparator содержит ряд методов, ключевым из которых является метод compare():
public interface Comparator<E> {
int compare(T a, T b);
// остальные методы
}Метод compare() также возвращает числовое значение - если оно отрицательное, то объект a предшествует объекту b, иначе - наоборот. А если метод возвращает 0, то объекты равны. Для применения интерфейса нам вначале надо создать класс компаратора, который реализует этот интерфейс:
class PersonComparator implements Comparator<Person> {
public int compare(Person a, Person b) {
return a.getName().compareTo(b.getName());
}
}Здесь опять же проводим сравнение по строкам. Теперь используем класс компаратора для создания объекта TreeSet:
PersonComparator pcomp = new PersonComparator();
TreeSet<Person> people = new TreeSet<Person>(pcomp);
people.add(new Person("Tom"));
people.add(new Person("Nick"));
people.add(new Person("Alice"));
people.add(new Person("Bill"));
for (Person p : people) {
System.out.println(p.getName());
}Для создания TreeSet здесь используется одна из версий конструктора, которая в качестве параметра принимает компаратор. Теперь вне зависимости от того, реализован ли в классе Person интерфейс Comparable, логика сравнения и сортировки будет использоваться та, которая определена в классе компаратора.
6.3. Сортировка по нескольким критериям
Начиная с JDK 8 в механизм работы компараторов были внесены некоторые дополнения. В частности, теперь мы можем применять сразу несколько компараторов по принципу приоритета. Например, изменим класс Person следующим образом:
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
String getName() {
return this.name;
}
int getAge() {
return this.age;
}
}Здесь добавлено поле для хранения возраста пользователя. И, допустим, нам надо отсортировать пользователей по имени и по возрасту. Для этого определим два компаратора:
class PersonNameComparator implements Comparator<Person> {
public int compare(Person a, Person b) {
return a.getName().compareTo(b.getName());
}
}class PersonAgeComparator implements Comparator<Person> {
public int compare(Person a, Person b) {
int result = 0;
if (a.getAge() > b.getAge()) {
result = 1;
} else if (a.getAge() < b.getAge()) {
result = -1;
}
return result;
}
}Интерфейс компаратора определяет специальный метод по умолчанию thenComparing(), который позволяет использовать цепочки компараторов для сортировки набора:
Comparator<Person> pcomp = new PersonNameComparator().thenComparing(new PersonAgeComparator());
TreeSet<Person> people = new TreeSet(pcomp);
people.add(new Person("Tom", 23));
people.add(new Person("Nick", 34));
people.add(new Person("Tom", 10));
people.add(new Person("Bill", 14));
for (Person p : people) {
System.out.println(p.getName() + " " + p.getAge());
}В данном случае сначала применяется сортировка по имени, а потом по возрасту.
7. Interface Queue
Очереди представляют структуру данных, работающую по принципу FIFO (first in - first out). То есть чем раньше был добавлен элемент в коллекцию, тем раньше он из нее удаляется. Это стандартная модель однонаправленной очереди. Однако бывают и двунаправленные - то есть такие, в которых мы можем добавить элемент не только в начала, но и в конец. И соответственно удалить элемент не только из конца, но и из начала.
Особенностью классов очередей является то, что они реализуют специальные интерфейсы Queue или Deque.
Обобщенный интерфейс Queue<E> расширяет базовый интерфейс Collection и определяет поведение класса в качестве однонаправленной очереди. Свою функциональность он раскрывает через следующие методы:
-
E element(): возвращает, но не удаляет, элемент из начала очереди. Если очередь пуста, генерирует исключениеNoSuchElementException -
boolean offer(E obj): добавляет элементobjв конец очереди. Если элемент удачно добавлен, возвращаетtrue, иначе -false -
E peek(): возвращает без удаления элемент из начала очереди. Если очередь пуста, возвращает значениеnull -
E poll(): возвращает с удалением элемент из начала очереди. Если очередь пуста, возвращает значениеnull -
E remove(): возвращает с удалением элемент из начала очереди. Если очередь пуста, генерирует исключениеNoSuchElementException
Таким образом, у всех классов, которые реализуют данный интерфейс, будет метод offer для добавления в очередь, метод poll для извлечения элемента из головы очереди, и методы peek и element, позволяющие просто получить элемент из головы очереди.
7.1. Interface Deque
Интерфейс Deque расширяет вышеописанный интерфейс Queue и определяет поведение двунаправленной очереди, которая работает как обычная однонаправленная очередь, либо как стек, действующий по принципу LIFO (последний вошел - первый вышел).
Интерфейс Deque определяет следующие методы:
-
void addFirst(E obj): добавляет элемент в начало очереди -
void addLast(E obj): добавляет элементobjв конец очереди -
E getFirst(): возвращает без удаления элемент из головы очереди. Если очередь пуста, генерирует исключениеNoSuchElementException -
E getLast(): возвращает без удаления последний элемент очереди. Если очередь пуста, генерирует исключениеNoSuchElementException -
boolean offerFirst(E obj): добавляет элементobjв самое начало очереди. Если элемент удачно добавлен, возвращаетtrue, иначе -false -
boolean offerLast(E obj): добавляет элементobjв конец очереди. Если элемент удачно добавлен, возвращаетtrue, иначе -false -
E peekFirst(): возвращает без удаления элемент из начала очереди. Если очередь пуста, возвращает значениеnull -
E peekLast(): возвращает без удаления последний элемент очереди. Если очередь пуста, возвращает значениеnull -
E pollFirst(): возвращает с удалением элемент из начала очереди. Если очередь пуста, возвращает значениеnull -
E pollLast(): возвращает с удалением последний элемент очереди. Если очередь пуста, возвращает значениеnull -
E pop(): возвращает с удалением элемент из начала очереди. Если очередь пуста, генерирует исключениеNoSuchElementException -
void push(E element): добавляет элемент в самое начало очереди -
E removeFirst(): возвращает с удалением элемент из начала очереди. Если очередь пуста, генерирует исключениеNoSuchElementException -
E removeLast(): возвращает с удалением элемент из конца очереди. Если очередь пуста, генерирует исключениеNoSuchElementException -
boolean removeFirstOccurrence(Object obj): удаляет первый встреченный элементobjиз очереди. Если удаление произшло, то возвращаетtrue, иначе возвращаетfalse. -
boolean removeLastOccurrence(Object obj): удаляет последний встреченный элементobjиз очереди. Если удаление произшло, то возвращаетtrue, иначе возвращаетfalse.
Таким образом, наличие методов pop и push позволяет классам, реализующим этот элемент, действовать в качестве стека. В тоже время имеющийся функционал также позволяет создавать двунаправленные очереди, что делает классы, применяющие данный интерфейс, довольно гибкими.
7.2. ArrayDeque
В Java очереди представлены рядом классов. Одни из низ - класс ArrayDeque<E>. Этот класс представляют обобщенную двунаправленную очередь, наследуя функционал от класса AbstractCollection и применяя интерфейс Deque.
В классе ArrayDeque определены следующие конструкторы:
-
ArrayDeque(): создает пустую очередь -
ArrayDeque(Collection<? extends E> col): создает очередь, наполненную элементами из коллекцииcol -
ArrayDeque(int capacity): создает очередь с начальной емкостьюcapacity. Если мы явно не указываем начальную емкость, то емкость по умолчанию будет равна 16
Пример использования класса`:
import java.util.ArrayDeque;
public class Program {
public static void main(String[] args) {
ArrayDeque<String> states = new ArrayDeque<String>();
// стандартное добавление элементов
states.add("Germany");
states.addFirst("France"); // добавляем элемент в самое начало
states.push("Great Britain"); // добавляем элемент в самое начало
states.addLast("Spain"); // добавляем элемент в конец коллекции
states.add("Italy");
// получаем первый элемент без удаления
String sFirst = states.getFirst();
System.out.println(sFirst); // Great Britain
// получаем последний элемент без удаления
String sLast = states.getLast();
System.out.println(sLast); // Italy
System.out.printf("Queue size: %d \n", states.size()); // 5
// перебор коллекции
while (states.peek() != null) {
// извлечение c начала
System.out.println(states.pop());
}
// очередь из объектов Person
ArrayDeque<Person> people = new ArrayDeque<Person>();
people.addFirst(new Person("Tom"));
people.addLast(new Person("Nick"));
// перебор без извлечения
for (Person p : people) {
System.out.println(p.getName());
}
}
}class Person {
private String name;
public Person(String value) {
name = value;
}
String getName() {
return name;
}
}8. Class LinkedList
Обобщенный класс LinkedList<E> представляет структуру данных в виде связанного списка. Он наследуется от класса AbstractSequentialList и реализует интерфейсы List, Dequeue и Queue. То есть он соединяет функциональность работы со списком и функциональность очереди.
Класс LinkedList имеет следующие конструкторы:
-
LinkedList(): создает пустой список -
LinkedList(Collection<? extends E> col): создает список, в который добавляет все элементы коллекцииcol
LinkedList содержит все те методы, которые определены в интерфейсах List, Queue, Deque. Некоторые из них:
-
addFirst() / offerFirst()добавляет элемент в начало списка -
addLast() / offerLast()добавляет элемент в конец списка -
removeFirst() / pollFirst()удаляет первый элемент из начала списка -
removeLast() / pollLast()удаляет последний элемент из конца списка -
getFirst() / peekFirst()получает первый элемент -
getLast() / peekLast()получает последний элемент
Рассмотрим применение связанного списка:
import java.util.LinkedList;
public class Program {
public static void main(String[] args) {
LinkedList<String> states = new LinkedList<String>();
// добавим в список ряд элементов
states.add("Germany");
states.add("France");
states.addLast("Great Britain"); // добавляем на последнее место
states.addFirst("Spain"); // добавляем на первое место
states.add(1, "Italy"); // добавляем элемент по индексу 1
System.out.printf("List has %d elements \n", states.size());
System.out.println(states.get(1));
states.set(1, "Portugal");
for (String state : states) {
System.out.println(state);
}
// проверка на наличие элемента в списке
if (states.contains("Germany")) {
System.out.println("List contains Germany");
}
states.remove("Germany");
states.removeFirst(); // удаление первого элемента
states.removeLast(); // удаление последнего элемента
LinkedList<Person> people = new LinkedList<Person>();
people.add(new Person("Mike"));
people.addFirst(new Person("Tom"));
people.addLast(new Person("Nick"));
people.remove(1); // удаление второго элемента
for (Person p : people) {
System.out.println(p.getName());
}
Person first = people.getFirst();
System.out.println(first.getName()); // вывод первого элемента
}
}class Person {
private String name;
public Person(String value) {
name = value;
}
String getName() {
return name;
}
}Здесь создаются и используются два списка: для строк и для объектов класса Person. При этом в дополнение к методам addFirst(), removeLast() и т.д., нам также доступны стандартные методы, определенные в интерфейсе Collection: add(), remove(), contains(), size() и другие. Поэтому мы можем использовать разные методы для одного и того же действия. Например, добавление в самое начало списка можно сделать так: states.addFirst("Spain");, а можно сделать так: states.add(0, "Spain");
8.1. LinkedList как структура данных
LinkedList — класс, реализующий два интерфейса — List и Deque. Это обеспечивает возможность создания двунаправленной очереди из любых, в том числе и null элементов. Каждый объект, помещенный в связанный список, является узлом (node). Каждый узел содержит элемент, ссылку на предыдущий и следующий узел. Фактически связанный список состоит из последовательности узлов, каждый из которых предназначен для хранения объекта определенного при создании типа.
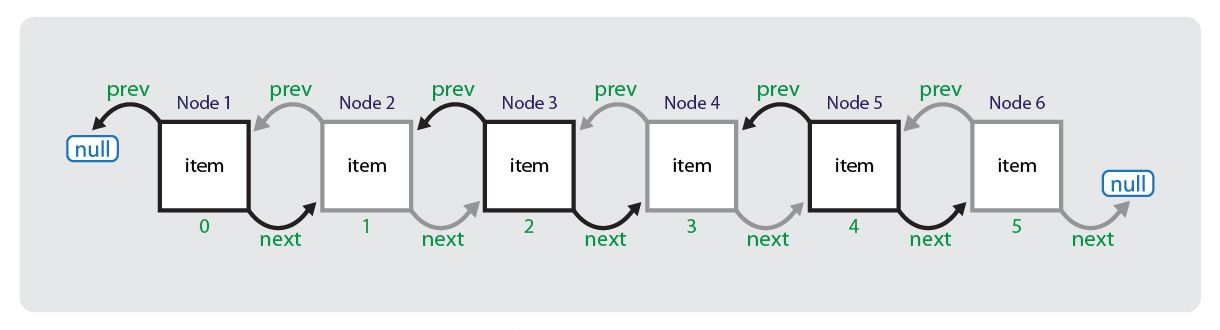
LinkedList8.1.1. Создание коллекции
LinkedList<Integer> numbers = new LinkedList<>();Данный код создает объект класса LinkedList и сохраняет его в ссылке numbers. Созданный объект предназначен для хранения целых чисел Integer. Пока этот объект пуст.
Класс LinkedList содержит три поля:
// модификатор transient указывает на то, что данное свойство класса нельзя
// сериализовать
transient int size = 0;
transient Node<E> first;
transient Node<E> last;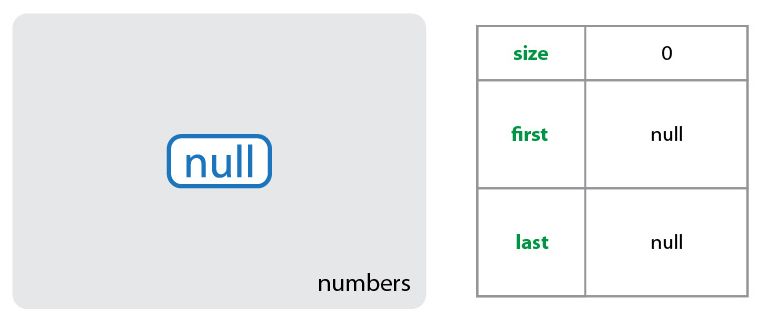
8.1.2. Добавление элемента
numbers.add(8);Данный код добавляет число 8 в конец ранее созданного списка. Под «капотом» этот метод вызывает ряд других методов, обеспечивающих создание объекта типа Integer, создание нового узла, установку объекта класса Integer в поле item этого узла, добавление узла в конец списка и установку ссылок на соседние узлы.
Для установки ссылок на предыдущий и следующий элементы LinkedList использует объекты своего вложенного класса Node:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}При каждом добавлении объекта в список создается один новый узел, а также изменяются значения полей связанного списка size, first, last.
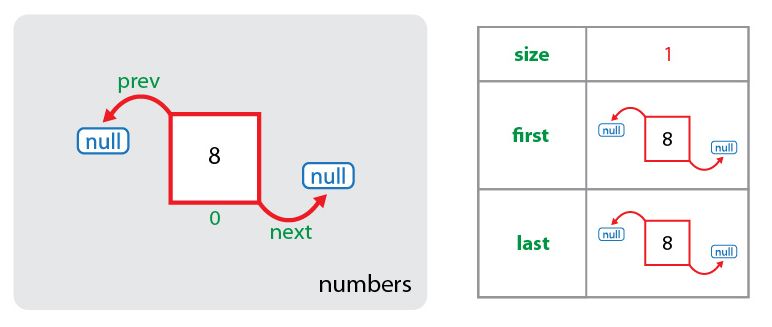
В случае с добавлением первого элемента создается узел, у которого предыдущий и следующий элементы отсутствуют, т.е. являются null, размер коллекции увеличивается на 1, а созданный узел устанавливается как первый и последний элемент коллекции.
Добавление еще одного элемента в коллекцию:
numbers.add(5);Сначала создается узел для нового элемента (число 5) и устанавливается ссылка на существующий элемент (узел с числом 8) коллекции как на предыдущий, а следующим элементом у созданного узла остается null. Также этот новый узел сохраняется в переменную связанного списка last:
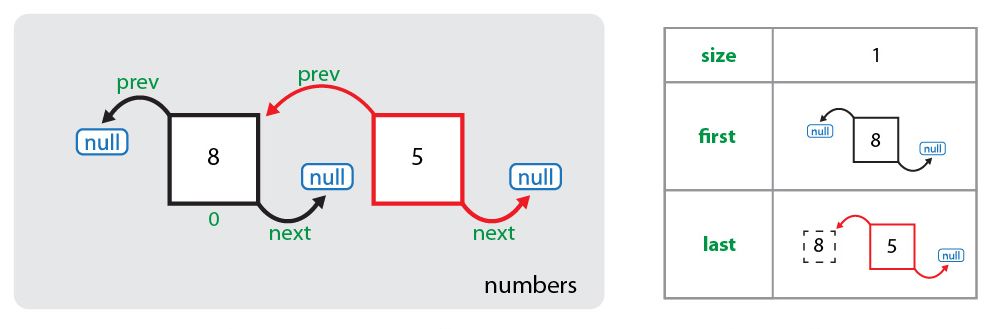
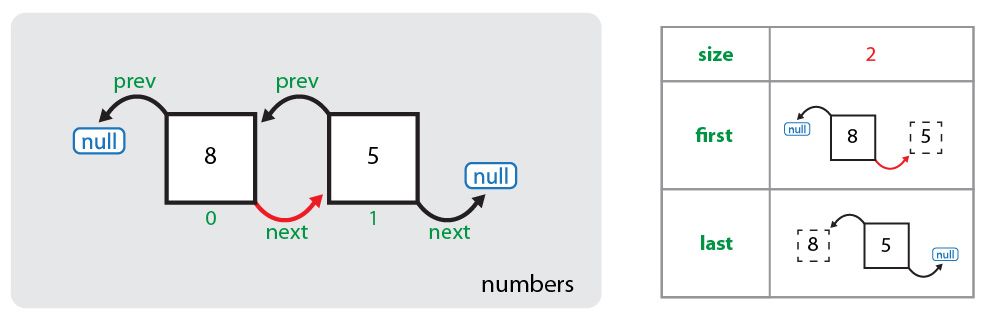
Как можно увидеть, первый элемент коллекции (под индексом 0) пока ссылается на null как на следующий элемент. Теперь эта ссылка заменяется и первый элемент начинает ссылаться на второй элемент коллекции (под индексом 1), а также увеличивается размер коллекции:
8.1.3. Добавление элемента в середину
numbers.add(1, 13);LinkedList позволяет добавить элемент в середину списка. Для этого используется метод add(index, element), где index — это место в списке, куда будет вставлен элемент element.
Как и метод add(element), данный метод вызывает несколько других методов. Сначала осуществляется проверка значения index, которое должно быть положительным числом, меньшим или равным размеру списка. Если index не удовлетворит этим условиям, то будет сгенерировано исключение IndexOutOfBoundsException.
Затем, если index равен размеру коллекции, то осуществляются действия, добавления последнего элемента в коллекцию, так как фактически необходимо вставить элемент в конец существующего списка.
Если же index не равен size списка, то осуществляется вставка перед элементом, который до этой вставки имеет заданный индекс.
Для начала с помощью метода node(index) определяется узел, находящийся в данный момент под индексом, под который нам необходимо вставить новый узел. Поиск данного узла осуществляется с помощью простого цикла for по половине списка (в зависимости от значения индекса — либо с начала до элемента, либо с конца до элемента). Далее создается узел для нового элемента (число 13), ссылка на предыдущий элемент устанавливается на узел, в котором элементом является число 8. Ссылка на следующий элемент устанавливается на узел, в котором элементом является число 5. Ссылки ранее существующих узлов пока не изменены:
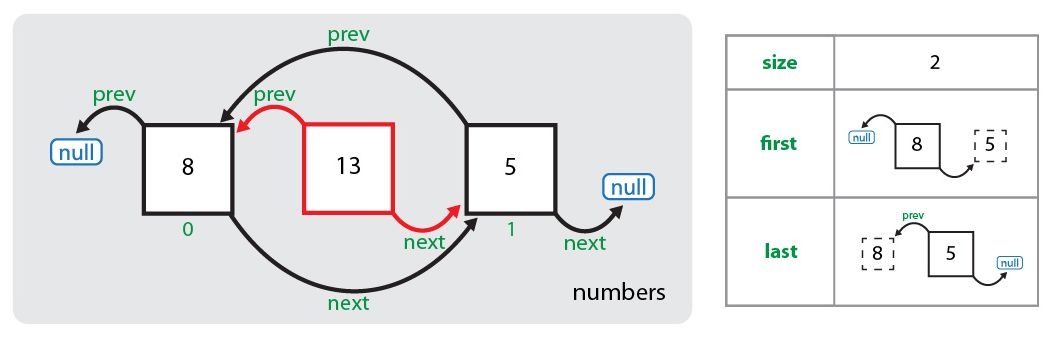
Теперь последовательно заменяются ссылки: для элемента, следующего за новым элементом, заменяется ссылка на предыдущий элемент (теперь она указывает на узел со значением 13), для предшествующего новому элементу заменяется ссылка на следующий элемент (теперь она указывает на узел со значением 5). И в последнюю очередь увеличивается размер списка:
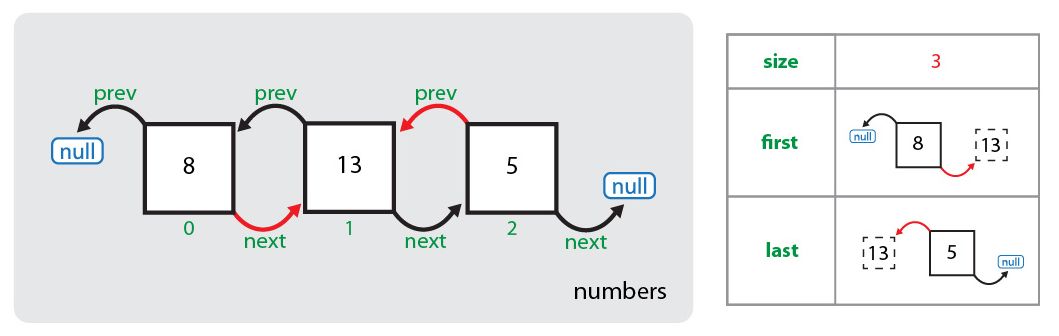
8.1.4. Удаление элемента
Рассмотрим удаление элемента из связанного списка по его значению. Удалим элемент со значением 5 из ниже представленного списка:
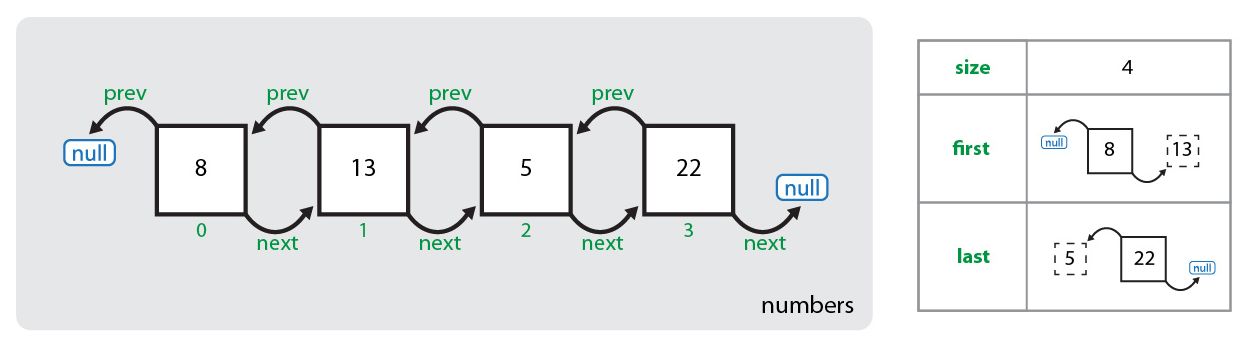
numbers.remove(Integer.valueOf(5));Принимаемым значением в методе remove(object) является именно объект, если попытаться удалить элемент со значением 5 следующей строкой:
numbers.remove(5);Tо сгенерируется IndexOutOfBoundsException, т.к. компиллятор воспримет число 5 как индекс и вызовет метод remove(index).
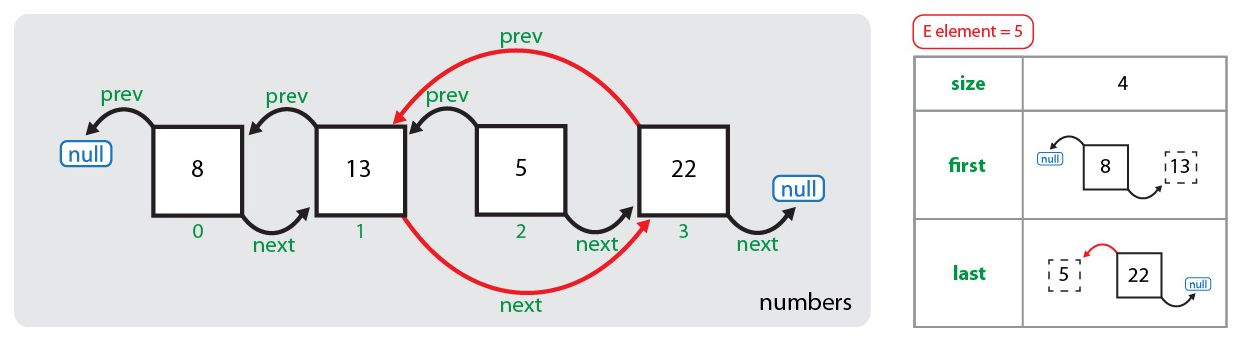
Что происходит при вызове метода remove(object)? Сначала искомый объект сравнивается по порядку со всеми элементами, сохраненными в узлах списка, начиная с нулевого узла. Когда найден узел, элемент которого равен искомому объекту, первым делом элемент сохраняется в отдельной переменной. Потом переопределяются ссылки соседних узлов так, чтобы они указывали друг на друга:
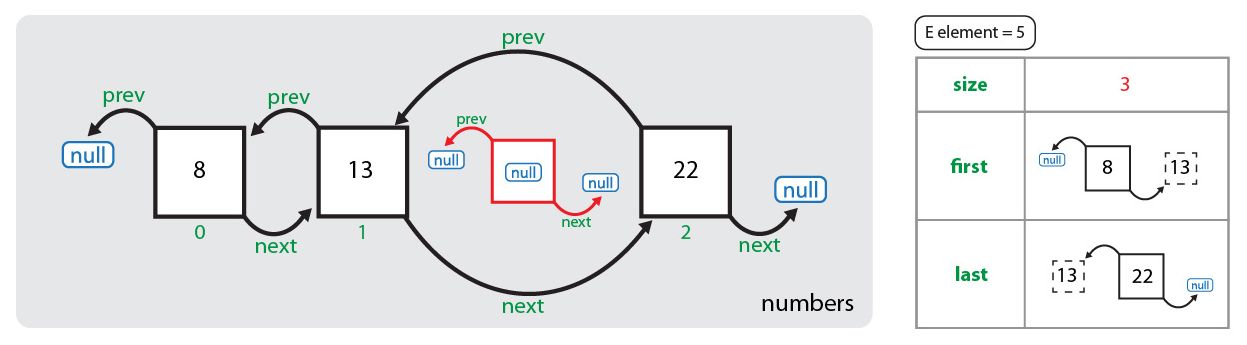
Затем обнуляется значение узла, который содержит удаляемый объект, а также уменьшается размер коллекции:
9. Interface Set
Интерфейс Set расширяет интерфейс Collection и представляет набор уникальных элементов. Set не добавляет новых методов, только вносит изменения в унаследованные. В частности, метод add() добавляет элемент в коллекцию и возвращает true, если в коллекции еще нет такого элемента.
9.1. HashSet
Обобщенный класс HashSet представляет хеш-таблицу. Он наследует свой функционал от класса AbstractSet, а также реализует интерфейс Set.
Хеш-таблица представляет такую структуру данных, в которой все объекты имеют уникальный ключ или хеш-код. Данный ключ позволяет уникально идентифицировать объект в таблице.
Для создания объекта HashSet можно воспользоваться одним из следующих конструкторов:
-
HashSet()создает пустой список -
HashSet(Collection<? extends E> col)создает хеш-таблицу, в которую добавляет все элементы коллекцииcol -
HashSet(int capacity)параметрcapacityуказывает начальную емкость таблицы, которая по умолчанию равна 16 -
HashSet(int capacity, float koef)параметрkoefили коэффициент заполнения, значение которого должно быть в пределах от0.0до1.0, указывает, насколько должна быть заполнена емкость объектами прежде чем произойдет ее расширение.
Класс HashSet не добавляет новых методов, реализуя лишь те, что объявлены в родительских классах и применяемых интерфейсах:
import java.util.HashSet;
public class Program {
public static void main(String[] args) {
HashSet<String> states = new HashSet<String>();
// добавим в список ряд элементов
states.add("Germany");
states.add("France");
states.add("Italy");
// пытаемся добавить элемент, который уже есть в коллекции
boolean isAdded = states.add("Germany");
System.out.println(isAdded); // false
System.out.printf("Set contains %d elements \n", states.size()); // 3
for (String state : states) {
System.out.println(state);
}
// удаление элемента
states.remove("Germany");
// хеш-таблица объектов Person
HashSet<Person> people = new HashSet<Person>();
people.add(new Person("Mike"));
people.add(new Person("Tom"));
people.add(new Person("Nick"));
for (Person p : people) {
System.out.println(p.getName());
}
}
}class Person {
private String name;
public Person(String name) {
this.name = name;
}
String getName() {
return this.name;
}
}10. Interface SortedSet
Интерфейс SortedSet предназначен для создания коллекций, который хранят элементы в отсортированном виде (сортировка по возрастанию). SortedSet расширяет интерфейс Set, поэтому такая коллекция опять же хранит только уникальные значения. SortedSet предоставляет следующие методы:
-
E first()возвращает первый элемент набора -
E last()возвращает последний элемент набора -
SortedSet<E> headSet(E end)возвращает объектSortedSet, который содержит все элементы первичного набора до элементаend -
SortedSet<E> subSet(E start, E end)возвращает объектSortedSet, который содержит все элементы первичного набора между элементамиstartиend -
SortedSet<E> tailSet(E start)возвращает объектSortedSet, который содержит все элементы первичного набора, начиная с элементаstart
10.1. Interface NavigableSet
Интерфейс NavigableSet расширяет интерфейс SortedSet и позволяет извлекать элементы на основании их значений. NavigableSet определяет следующие методы:
-
E ceiling(E obj)ищет в наборе наименьший элементe, который больше либо равен элементуobj(e >= obj). Если такой элемент найден, то он возвращается в качестве результата. Иначе возвращаетсяnull. -
E floor(E obj)ищет в наборе наибольший элементe, который меньше либо равен элементуobj(e ⇐ obj). Если такой элемент найден, то он возвращается в качестве результата. Иначе возвращаетсяnull. -
E higher(E obj)ищет в наборе наименьший элементe, который больше элементаobj(e > obj). Если такой элемент найден, то он возвращается в качестве результата. Иначе возвращаетсяnull. -
E lower(E obj)ищет в наборе наибольший элементe, который меньше элементаobj(e < obj). Если такой элемент найден, то он возвращается в качестве результата. Иначе возвращаетсяnull. -
E pollFirst()возвращает первый элемент -
E pollLast()возвращает последний элемент -
NavigableSet<E> descendingSet()возвращает объектNavigableSet, который содержит все элементы первичного набораNavigableSetв обратном порядке -
NavigableSet<E> headSet(E upperBound, boolean incl): возвращает объектNavigableSet, который содержит все элементы первичного набораNavigableSetдоupperBound. Параметрinclпри значенииtrue, позволяет включить в выходной набор элементupperBound -
NavigableSet<E> tailSet(E lowerBound, boolean incl)возвращает объектNavigableSet, который содержит все элементы первичного набораNavigableSet, начиная сlowerBound. Параметрinclпри значенииtrue, позволяет включить в выходной набор элементlowerBound -
NavigableSet<E> subSet(E lowerBound, boolean lowerIncl, E upperBound, boolean highIncl)возвращает объектNavigableSet, который содержит все элементы первичного набораNavigableSetотlowerBoundдоupperBound.
10.1.1. TreeSet
Обобщенный класс TreeSet<E> представляет структуру данных в виде дерева, в котором все объекты хранятся в отсортированном виде по возрастанию. TreeSet является наследником класса AbstractSet и реализует интерфейс NavigableSet, а следовательно, и интерфейс SortedSet.
В классе TreeSet определены следующие конструкторы:
-
TreeSet()создает пустое дерево -
TreeSet(Collection<? extends E> col)создает дерево, в которое добавляет все элементы коллекцииcol -
TreeSet(SortedSet <E> set)создает дерево, в которое добавляет все элементы сортированного набораset -
TreeSet(Comparator<? super E> comparator)создает пустое дерево, где все добавляемые элементы впоследствии будут отсортированы с помощьюcomparator.
TreeSet поддерживает все стандартные методы для вставки и удаления элементов:
import java.util.TreeSet;
public class Program {
public static void main(String[] args) {
TreeSet<String> states = new TreeSet<String>();
// добавим в список ряд элементов
states.add("Germany");
states.add("France");
states.add("Italy");
states.add("Great Britain");
System.out.printf("TreeSet contains %d elements \n", states.size());
// удаление элемента
states.remove("Germany");
for (String state : states) {
System.out.println(state);
}
}
}И поскольку при вставке объекты сразу же сортируются по возрастанию, то при выводе в цикле for мы получим отсортированный набор.
Так как TreeSet реализует интерфейс NavigableSet, а через него и SortedSet, то мы можем применить к структуре дерева различные методы:
import java.util.NavigableSet;
import java.util.SortedSet;
import java.util.TreeSet;
public class Program {
public static void main(String[] args) {
TreeSet<String> states = new TreeSet<String>();
// добавим в список ряд элементов
states.add("Germany");
states.add("France");
states.add("Italy");
states.add("Spain");
states.add("Great Britain");
System.out.println(states.first()); // получим первый - самый меньший элемент
System.out.println(states.last()); // получим последний - самый больший элемент
// получим поднабор от одного элемента до другого
SortedSet<String> set = states.subSet("Germany", "Italy");
System.out.println(set);
// элемент из набора, который больше текущего
String greater = states.higher("Germany");
// элемент из набора, который меньше текущего
String lower = states.lower("Germany");
// возвращаем набор в обратном порядке
NavigableSet<String> navSet = states.descendingSet();
// возвращаем набор в котором все элементы меньше текущего
SortedSet<String> setLower = states.headSet("Germany");
// возвращаем набор в котором все элементы больше текущего
SortedSet<String> setGreater = states.tailSet("Germany");
System.out.println(navSet);
System.out.println(setLower);
System.out.println(setGreater);
}
}11. Interface Map
Интерфейс Map<K, V> представляет отображение или иначе говоря словарь, где каждый элемент представляет пару key-value. При этом все ключи уникальные в рамках объекта Map. Такие коллекции облегчают поиск элемента, если нам известен ключ - уникальный идентификатор объекта.
Следует отметить, что в отличие от других интерфейсов, которые представляют коллекции, интерфейс Map НЕ расширяет интерфейс Collection.
Среди методов интерфейса Map можно выделить следующие:
-
void clear()очищает коллекцию -
boolean containsKey(Object k): возвращаетtrue, если коллекция содержит ключk -
boolean containsValue(Object v): возвращаетtrue, если коллекция содержит значениеv -
Set<Map.Entry<K, V>> entrySet(): возвращает набор элементов коллекции. Все элементы представляют объектMap.Entry -
boolean equals(Object obj)возвращаетtrue, если коллекция идентична коллекции, передаваемой через параметрobj -
boolean isEmptyвозвращаетtrue, если коллекция пуста -
V get(Object k)возвращает значение объекта, ключ которого равенk. Если такого элемента не окажется, то возвращается значениеnull -
V getOrDefault(Object k, V defaultValue)возвращает значение объекта, ключ которого равенk. Если такого элемента не окажется, то возвращается значениеdefaultValue -
V put(K k, V v)помещает в коллекцию новый объект с ключомkи значениемv. Если в коллекции уже есть объект с подобным ключом, то он перезаписывается. После добавления возвращает предыдущее значение для ключаk, если он уже был в коллекции. Если же ключа еще не было в коллекции, то возвращается значениеnull -
V putIfAbsent(K k, V v)помещает в коллекцию новый объект с ключомkи значениемv, если в коллекции еще нет элемента с подобным ключом. -
Set<K> keySet()возвращает набор всех ключей отображения -
Collection<V> values()возвращает набор всех значений отображения -
void putAll(Map<? extends K, ? extends V> map)добавляет в коллекцию все объекты из отображенияmap -
V remove(Object k)удаляет объект с ключомk -
int size()возвращает количество элементов коллекции
Чтобы положить объект в коллекцию, используется метод put(), а чтобы получить по ключу - метод get(). Реализация интерфейса Map также позволяет получить наборы как ключей, так и значений. А метод entrySet() возвращает набор всех элементов в виде объектов Map.Entry<K, V>.
Обобщенный интерфейс Map.Entry<K, V> представляет объект с ключом типа K и значением типа V и определяет следующие методы:
-
boolean equals(Object obj)возвращаетtrue, если объектobj, представляющий интерфейсMap.Entry, идентичен текущему -
K getKey()возвращает ключ объекта отображения -
V getValue()возвращает значение объекта отображения -
Set<K> keySet()возвращает набор всех ключей отображения -
V setValue(V v)устанавливает для текущего объекта значениеv -
int hashCode()возвращает хеш-код данного объекта
При переборе объектов отображения мы будем оперировать этими методами для работы с ключами и значениями объектов.
12. Class HashMap
Базовым классом для всех отображений является абстрактный класс AbstractMap, который реализует большую часть методов интерфейса Map. Наиболее распространенным классом отображений является HashMap, который реализует интерфейс Map и наследуется от класса AbstractMap.
Пример использования класса:
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Program {
public static void main(String[] args) {
Map<Integer, String> states = new HashMap<Integer, String>();
states.put(1, "Germany");
states.put(2, "Spain");
states.put(4, "France");
states.put(3, "Italy");
// получим объект по ключу 2
String first = states.get(2);
System.out.println(first);
// получим весь набор ключей
Set<Integer> keys = states.keySet();
// получить набор всех значений
Collection<String> values = states.values();
//заменить элемент
states.replace(1, "Poland");
// удаление элемента по ключу 2
states.remove(2);
// перебор элементов
for (Map.Entry<Integer, String> item : states.entrySet()) {
System.out.printf("Key: %d Value: %s \n", item.getKey(), item.getValue());
}
Map<String, Person> people = new HashMap<String, Person>();
people.put("1240i54", new Person("Tom"));
people.put("1564i55", new Person("Bill"));
people.put("4540i56", new Person("Nick"));
for (Map.Entry<String, Person> item : people.entrySet()) {
System.out.printf("Key: %s Value: %s \n", item.getKey(), item.getValue().getName());
}
}
}class Person {
private String name;
public Person(String name) {
this.name = name;
}
String getName() {
return this.name;
}
}Чтобы добавить или заменить элемент, используется метод put(), либо replace(), а чтобы получить его значение по ключу - метод get(). С помощью других методов интерфейса Map также производятся другие манипуляции над элементами:
-
перебор
-
получение ключей
-
значений
-
удаление
12.1. HashMap как структура данных
12.1.1. Создание коллекции
Map<String, String> hashmap = new HashMap<String, String>();Новоявленный объект hashmap, содержит ряд свойств:
-
table— массив типаEntry, который является хранилищем ссылок на списки (цепочки) значений; -
loadFactor— коэффициент загрузки. Значение по умолчанию0.75является хорошим компромиссом между временем доступа и объемом хранимых данных; -
threshold— предельное количество элементов, при достижении которого, размер хэш-таблицы увеличивается вдвое. Рассчитывается по формуле (capacity * loadFactor); -
size— количество элементовHashMap;
В конструкторе, выполняется проверка валидности переданных параметров и установка значений в соответствующие свойства класса.
HashMap содержит массив Node<K, V>.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}Теперь разберем как все это работает. Для начала рассмотрим процесс хеширования.
12.1.2. Хеширование
Хеширование (hashing)- это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш/identity hash code). Сигнатура метода public native hashCode(). Это говорит о том, что метод реализован как нативный, поскольку в Java нет какого-то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления bucket (в переводе с английского: ведро) и, следовательно, вычисления индекса.
Метод equals()
Метод equals() используется для проверки двух объектов на равенство. Метод реализован в классе Object. Можно переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Buckets
Bucket - это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот-же bucket. В этом случае для связи узлов используется структура данных связанный список (т.е. LinkedList). Bucket различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
capacity = number of buckets * load factorОдин bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализован метод hashCode(), тем лучше будут использоваться bucket.
12.1.3. Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если создать массив такого размера, то легко получим исключение outOfMemoryException. Потому генерируется индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
index = hashCode(key) & ( n - 1).Где n равна числу buckets или значению длины массива.
12.1.4. Вставка элемента (пары ключ/значение)
Изначально пустой HashMap выглядит так:
HashMap map = new HashMap();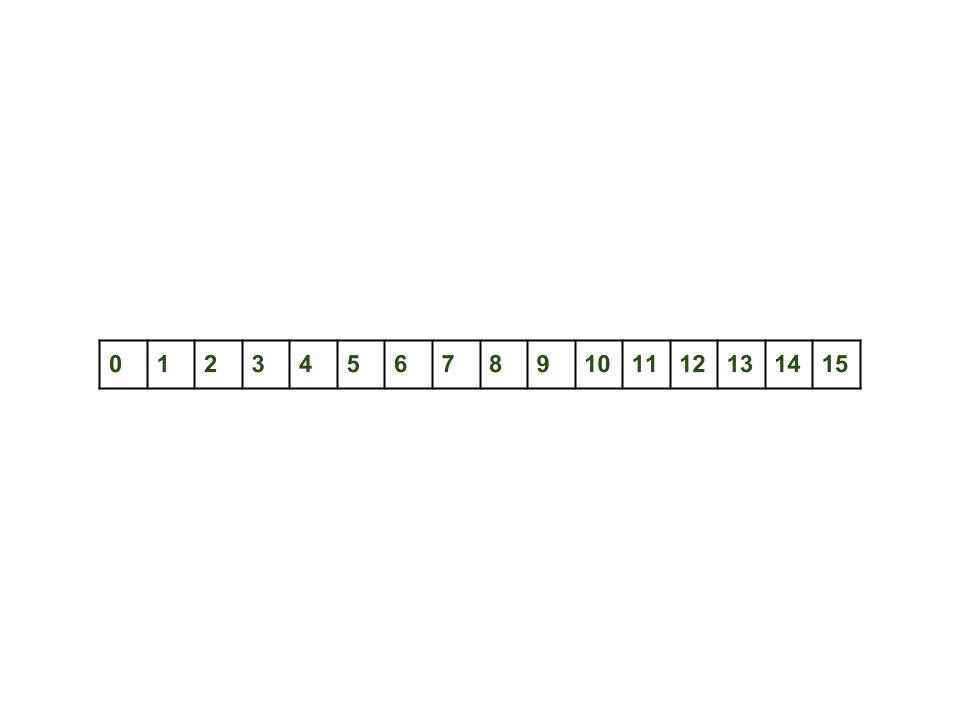
HashMapДобавление одной пары ключ/значение:
map.put(new Key("vishal"), 20);Добавление элемента происходит в несколько этапов:
-
Вычислить значение ключа
"vishal". Оно будет сгенерировано, как118. -
Вычислить индекс с помощью метода
index(), который будет равен6. -
Создать объект типа
Node. -
Поместить объект в позицию с индексом
6, если место свободно.
Теперь HashMap выглядит примерно так:
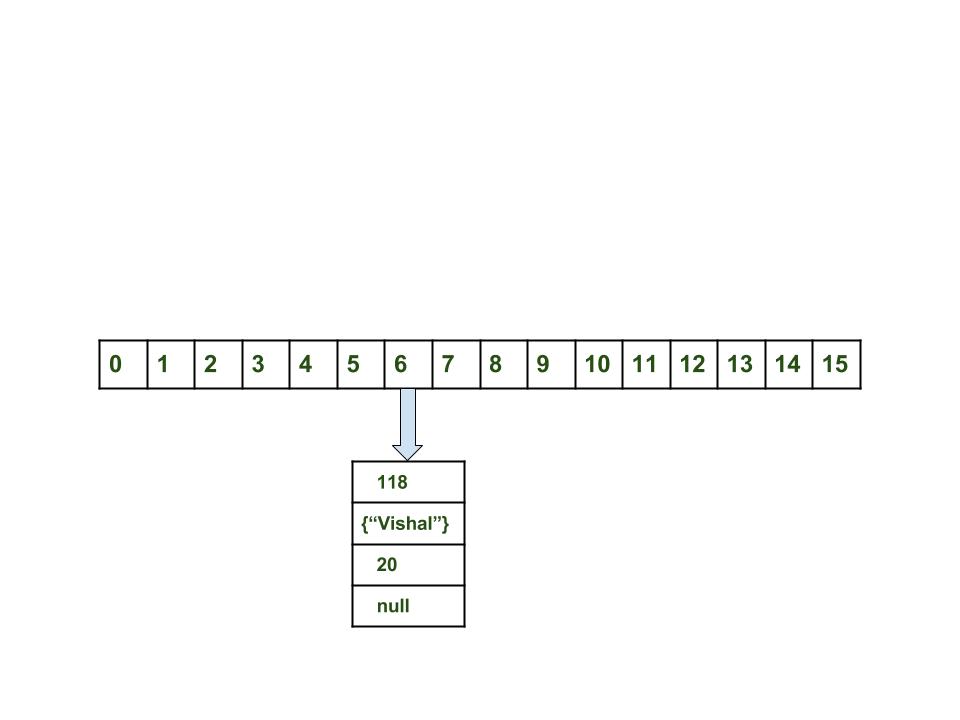
HashMap с одним элементом12.1.5. Возникновение коллизий при вставке
map.put(new Key("vaibhav"), 40);Добавление элемента с коллизией происходит в несколько этапов:
-
Вычислить значение ключа
"vaibhav". Оно будет сгенерировано, как118. -
Вычислить индекс с помощью метода
index(), который будет равен6. -
Создать объект типа
Node. -
Поместить объект в позицию с индексом
6, если место свободно. -
В данном случае в позиции с индексом
6уже существует другой объект, этот случай называется коллизией. -
В таком случае проверяется с помощью методов
hashCode()иequals(), идентичность ключей. -
Если ключи одинаковы, заменить текущее значение новым.
-
Иначе связать новый и старый объекты с помощью структуры данных
связанный список, указав ссылку на следующий объект в текущем и сохранить оба под индексом6.
Теперь HashMap выглядит примерно так:
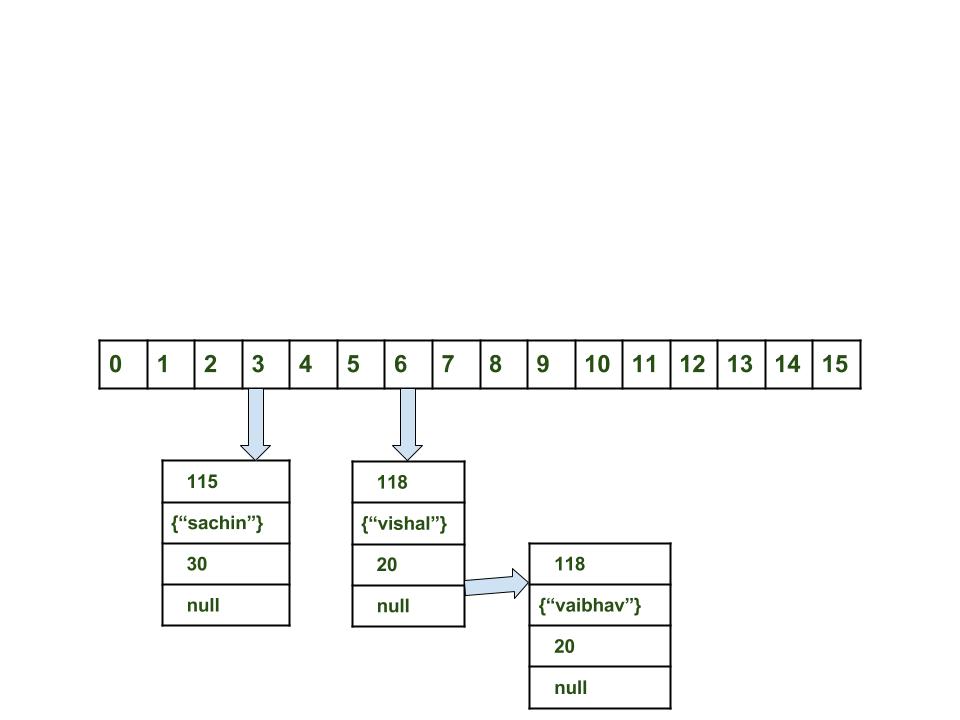
HashMap при вставке с коллизией12.1.6. Получение значения по ключу
map.get(new Key("vaibhav"));Получение элемента происходит в несколько этапов:
-
Вычислить хэш код объекта
"vaibhav". Он был сгенерирован, как118. -
Вычислить индекс с помощью метода
index(), который будет равен6. -
Перейти по индексу
6и сравнить ключ первого элемента с имеющемся значением. Если они равны, то вернуть значение, иначе выполнить проверку для следующего элемента, если он существует. -
В данном случае он не найден и следующий объект типа
Nodeне равенnull. -
Если следующий объект node равен
null, возвращаемnull. -
Если следующий объект node не равен
null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект типаNodeне будет равенnull.
12.1.7. Изменения в Java 8
В случае возникновения коллизий объект типа Node сохраняется в структуре данных "связанный список" и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке - линейная операция и в худшем случае сложность равна O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как количество элементов в хеше достигает определенного порога, происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
12.1.8. Основные моменты
-
Сложность операций
get()иput()практически константна до тех пор, пока не будет проведено повторное хеширование. -
В случае коллизий, если индексы двух и более объектов
nodeодинаковые, объекты типаNodeсоединяются с помощью связанного списка, т.е. ссылка на второй объект типаNodeхранится в первом, на третий во втором и т.д. -
Если данный ключ уже существует в
HashMap, значение перезаписывается. -
Хэш код
nullравен 0. -
Когда объект получается по ключу происходят переходы по связанному списку до тех пор, пока объект не будет найден или ссылка на следующий объект не будет равна
null.
12.2. Class LinkedHashMap
Класс LinkedHashMap хранит элементы типа ключ-значение в том порядке, в котором они были добавлены. Это означает, что LinkedHashMap позволяет работать с элементами коллекции в порядке их добавления.
12.2.1. Создание коллекции
Map<Integer, String> linkedHashMap = new LinkedHashMap<Integer, String>();Только что созданный объект linkedHashMap, помимо свойств унаследованных от HashMap (такие, как: table, loadFactor, threshold, size, entrySet и т.п.), так же содержит два доп. свойства:
-
header— «голова» двусвязного списка. При инициализации указывает сам на себя; -
accessOrder— указывает каким образом будет осуществляться доступ к элементам при использовании итератора. При значенииtrue— по порядку последнего доступа (об этом в конце). При значенииfalseдоступ осуществляется в том порядке, в котором элементы были вставлены.
Конструкторы класса LinkedHashMap достаточно скучные, вся их работа сводится к вызову конструктора родительского класса и установке значения свойству accessOrder. А вот инициализация свойства header происходит в переопределенном методе init().
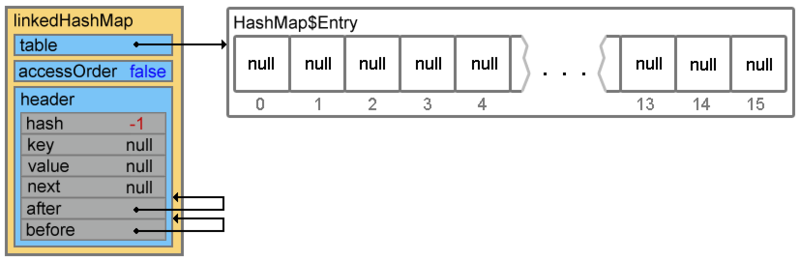
LinkedHashMap12.2.2. Добавление элементов
linkedHashMap.put(1, "obj1");При добавлении элемента, первым вызывается метод createEntry(hash, key, value, bucketIndex) (по цепочке put(), addEntry(), createEntry())
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}Первые три строки добавляют элемент (при коллизиях добавление произойдет в начало цепочки):
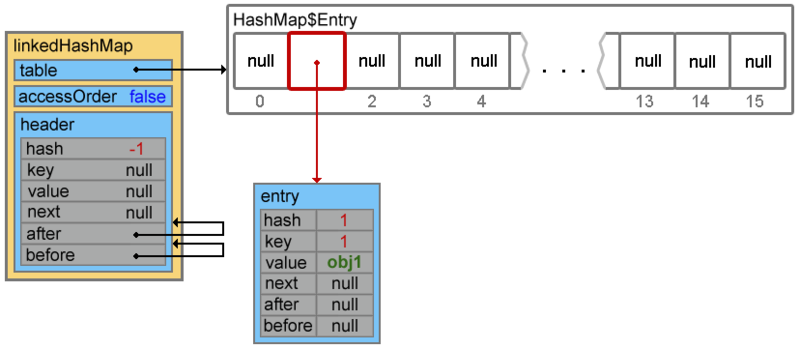
Четвертая строка переопределяет ссылки двусвязного списка:
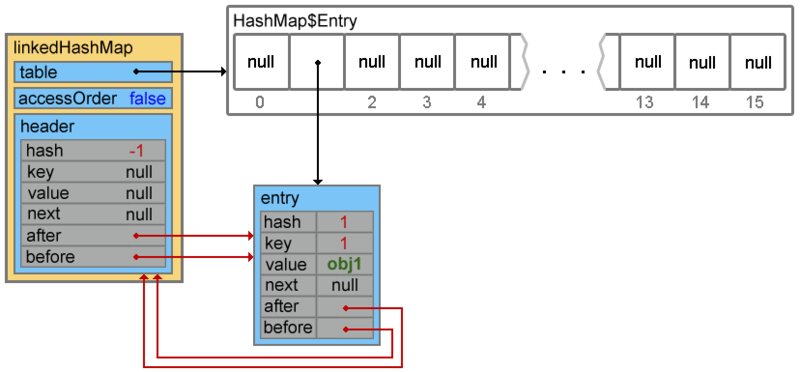
Всё что дальше происходит в методе addEntry() либо не представляет функционального интереса либо повторяет функционал родительского класса.
Добавим еще парочку элементов:
linkedHashMap.put(15, "obj15");
linkedHashMap.put(4, "obj4")При добавлении следующего элемента происходит коллизия, и элементы с ключами 4 и 38 образуют цепочку:
linkedHashMap.put(38, "obj38");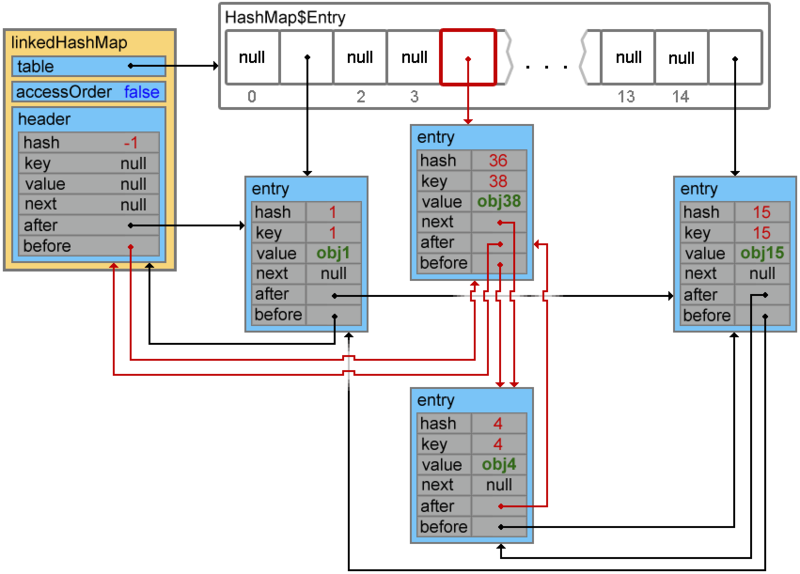
12.2.3. accessOrder == true
А теперь давайте рассмотрим пример когда свойство accessOrder имеет значение true. В такой ситуации поведение LinkedHashMap меняется и при вызовах методов get() и put() порядок элементов будет изменен — элемент к которому обращаемся, будет помещен в конец.
public class Program {
public static void main(String[] args){
Map<Integer, String> linkedHashMap = new LinkedHashMap<>(15, 0.75f, true);
linkedHashMap.put(1, "obj1");
linkedHashMap.put(15, "obj15");
linkedHashMap.put(4, "obj4");
linkedHashMap.put(38, "obj38");
System.out.println(linkedHashMap);
linkedHashMap.get(1);
System.out.println(linkedHashMap);
}
}{1=obj1, 15=obj15, 4=obj4, 38=obj38}
{15=obj15, 4=obj4, 38=obj38, 1=obj1}
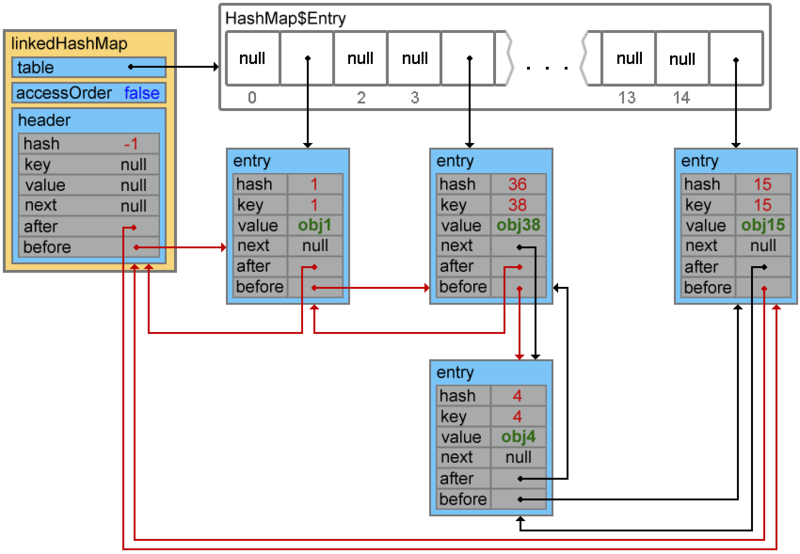
accessOrder == true13. Interface SortedMap
Интерфейс SortedMap расширяет Map и создает отображение, в котором все элементы отсортированы в порядке возрастания их ключей. SortedMap добавляет ряд методов:
-
K firstKey()возвращает ключ первого элемента отображения -
K lastKey()возвращает ключ последнего элемента отображения -
SortedMap<K, V> headMap(K end)возвращает отображениеSortedMap, которые содержит все элементы оригинальногоSortedMapвплоть до элемента с ключомend -
SortedMap<K, V> tailMap(K start)возвращает отображениеSortedMap, которые содержит все элементы оригинальногоSortedMap, начиная с элемента с ключомstart -
SortedMap<K, V> subMap(K start, K end)возвращает отображениеSortedMap, которые содержит все элементы оригинальногоSortedMapвплоть от элемента с ключомstartдо элемента с ключомend
13.1. Interface NavigableMap
Интерфейс NavigableMap расширяет интерфейс SortedMap и обеспечивает возможность получения элементов отображения относительно других элементов. Его основные методы:
-
Map.Entry<K, V> ceilingEntry(K obj)возвращает элемент с наименьшим ключомk, который больше или равен ключуobj(k>=obj). Если такого ключа нет, то возвращаетсяnull -
Map.Entry<K, V> floorEntry(K obj)возвращает элемент с наибольшим ключомk, который меньше или равен ключуobj(k⇐obj). Если такого ключа нет, то возвращаетсяnull -
Map.Entry<K, V> higherEntry(K obj)возвращает элемент с наименьшим ключомk, который больше ключаobj(k>`obj`). Если такого ключа нет, то возвращаетсяnull -
Map.Entry<K, V> lowerEntry(K obj)возвращает элемент с наибольшим ключомk, который меньше ключаobj(k<`obj`). Если такого ключа нет, то возвращаетсяnull -
Map.Entry<K, V> firstEntry()возвращает первый элемент отображения -
Map.Entry<K, V> lastEntry()возвращает последний элемент отображения -
Map.Entry<K, V> pollFirstEntry()возвращает и одновременно удаляет первый элемент из отображения -
Map.Entry<K, V> pollLastEntry()возвращает и одновременно удаляет последний элемент из отображения -
K ceilingKey(K obj)возвращает наименьший ключk, который больше или равен ключуobj(k>=obj). Если такого ключа нет, то возвращаетсяnull -
K floorKey(K obj)возвращает наибольший ключk, который меньше или равен ключуobj(k⇐obj). Если такого ключа нет, то возвращаетсяnull -
K lowerKey(K obj)возвращает наибольший ключk, который меньше ключаobj(k<`obj`). Если такого ключа нет, то возвращаетсяnull -
K higherKey(K obj)возвращает наименьший ключk, который больше ключаobj(k>`obj`). Если такого ключа нет, то возвращаетсяnull -
NavigableSet<K> descendingKeySet()возвращает объектNavigableSet, который содержит все ключи отображения в обратном порядке -
NavigableMap<K, V> descendingMap()возвращает отображениеNavigableMap, которое содержит все элементы в обратном порядке -
NavigableSet<K> navigableKeySet()возвращает объектNavigableSet, который содержит все ключи отображения -
NavigableMap<K, V> headMap(K upperBound, boolean incl)возвращает отображениеNavigableMap, которое содержит все элементы оригинальногоNavigableMapвплоть от элемента с ключомupperBound. Параметрinclпри значенииtrueуказывает, что элемент с ключомupperBoundтакже включается в выходной набор. -
NavigableMap<K, V> tailMap(K lowerBound, boolean incl)возвращает отображениеNavigableMap, которое содержит все элементы оригинальногоNavigableMap, начиная с элемента с ключомlowerBound. Параметрinclпри значенииtrueуказывает, что элемент с ключомlowerBoundтакже включается в выходной набор. -
NavigableMap<K, V> subMap(K lowerBound, boolean lowIncl, K upperBound, boolean highIncl)возвращает отображениеNavigableMap, которое содержит все элементы оригинальногоNavigableMapот элемента с ключомlowerBoundдо элемента с ключомupperBound. ПараметрыlowInclиhighInclпри значенииtrueвключают в выходной набор элементы с ключамиlowerBoundиupperBoundсоответственно
13.2. TreeMap
Класс TreeMap<K, V> представляет отображение в виде дерева. Он наследуется от класса AbstractMap и реализует интерфейс NavigableMap, а следовательно, также и интерфейс SortedMap. Поэтому в отличие от коллекции HashMap в TreeMap все объекты автоматически сортируются по возрастанию их ключей.
Класс TreeMap имеет следующие конструкторы:
-
TreeMap()создает пустое отображение в виде дерева -
TreeMap(Map<K, ? extends V> map)создает дерево, в которое добавляет все элементы из отображенияmap -
TreeMap(SortedMap<K, ? extends V> smap)создает дерево, в которое добавляет все элементы из отображенияsmap -
TreeMap(Comparator<? super K> comparator)создает пустое дерево, где все добавляемые элементы впоследствии будут отсортированы компаратором.
Используем класс в программе:
import java.util.Collection;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class Program {
public static void main(String[] args) {
TreeMap<Integer, String> states = new TreeMap<Integer, String>();
states.put(10, "Germany");
states.put(2, "Spain");
states.put(14, "France");
states.put(3, "Italy");
// получим объект по ключу 2
String first = states.get(2);
// перебор элементов
for (Map.Entry<Integer, String> item : states.entrySet()) {
System.out.printf("Key: %d Value: %s \n", item.getKey(), item.getValue());
}
// получим весь набор ключей
Set<Integer> keys = states.keySet();
// получить набор всех значений
Collection<String> values = states.values();
// получаем все объекты, которые стоят после объекта с ключом 4
Map<Integer, String> afterMap = states.tailMap(4);
// получаем все объекты, которые стоят до объекта с ключом 10
Map<Integer, String> beforeMap = states.headMap(10);
// получим последний элемент дерева
Map.Entry<Integer, String> lastItem = states.lastEntry();
System.out.printf("Last item has key %d value %s \n", lastItem.getKey(), lastItem.getValue());
Map<String, Person> people = new TreeMap<String, Person>();
people.put("1240i54", new Person("Tom"));
people.put("1564i55", new Person("Bill"));
people.put("4540i56", new Person("Nick"));
for (Map.Entry<String, Person> item : people.entrySet()) {
System.out.printf("Key: %s Value: %s \n", item.getKey(), item.getValue().getName());
}
}
}class Person {
private String name;
public Person(String name) {
this.name = name;
}
String getName() {
return name;
}
}Кроме собственно методов интерфейса Map класс TreeMap реализует методы интерфейса NavigableMap. Например, мы можем получить все объекты до или после определенного ключа с помощью методов headMap() и tailMap(). Также мы можем получить первый и последний элементы и провести ряд дополнительных манипуляций с объектами.