1. Styleguides
Любой файл, независимо от содержимого, заканчивается пустой строкой.
1.1. Markdown
-
Отделяются от других элементов с обеих сторон одной пустой строкой:
-
заголовки всех уровней (
,#, …) -
блоки с исходным кодом
-
списки (но не элементы одного списка)
-
цитаты
-
изображения
-
таблицы
-
-
Путь к файлу или название файла с иходным кодом, переменые, типы данных, значения и все остальное, что связанно с исходным кодом, должно быць выделенно как инлайн код. Например:
code -
Выделение жирным шрифтом используется для важных терминов в контексте предложения.
-
Выделение курсивным шрифтом используется для второстепенных терминов в контексте предложения.
-
Нумерованые списки применяются для списков, где последовательность имеет значение или где заранее известно количество элементов и маловероятно его изменение.
2. Концепции ООП
Объектно-ориентированное программирование - это парадигма, которая предоставляет множество концепций, таких как наследование, полимофизм и т.д.
Simula 67 считается первым объектно-ориентированным языком программирования.
Парадигма программирования, в которой все представлено в виде объекта, называется истинно объектно-ориентированным языком программирования.
Smalltalk считается первым истинным объектно-ориентированным языком программирования.
Популярными объектно-ориентированными языками являются:
-
Java
-
C++
-
C#
-
PHP
-
Python
2.1. ООП
Объект представляет собой реальную сущность из реального мира, например: BMW X5, Boeing 737, Parker Jotter (ручка).
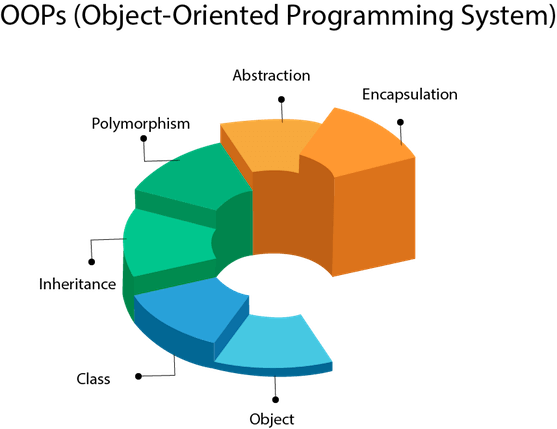
Объектно-ориентированное программирование - это методология или парадигма для разработки программы с использованием классов и объектов. Это упрощает разработку и обслуживание программного обеспечения, предоставляя некоторые концепции:
-
Объект (Object)
-
Класс (Class)
-
Инкапсуляция (Encapsulation)
-
Наследование (Inheritance)
-
Полиморфизм (Polymorphism)
-
Абстракция (Abstraction)
Помимо этих концепций, есть несколько других терминов, которые используются в объектно-ориентированном дизайне:
-
Связность (Coupling), Единство (Cohesion)
-
Ассоциация (Association)
-
Агрегация (Aggregation), Композиция (Composition)
2.1.1. Object
Любая сущность, которая имеет состояние (state) и поведение (behavior), называется объектом. Например: овчарка, Apple MacBook Pro 13 Touch Bar 2019, Huawei Mate P10 Lite. Это может быть как физический предмет, так и нет.
Объект может быть определен как экземпляр класса. Объект содержит адрес и занимает некоторое место в памяти. Объекты могут взаимодействовать, но не знать состояния и реализации друг друга. Единственная необходимая вещь - это контракт взаимодействия.
Пример: собака - это объект, потому что она имеет такие состояния, как цвет, имя, порода, а также поведение, такое как вилять хвостом, лаять, есть.
2.1.2. Class
Класс - это определенный пользователем шаблон или прототип, из которого создаются объекты. Он представляет собой набор свойств или методов, которые являются общими для всех объектов одного типа.
2.2. Принципы ООП
2.2.1. Encapsulation
Encapsulation (Инкапсуляция) - это размещение в одном компоненте данных и методов, которые работаю с этими данными.
Java Class является примером инкапсуляции. В сообществе C++ или Java принято рассматривать инкапсуляцию без сокрытия как неполноценную.
Java Bean является полностью инкапсулированным классом, потому что все члены данных здесь являются закрытыми.
В общем случае в разных языках программирования термин инкапсуляция относится к одной или обеим одновременно следующим нотациям:
-
языковая конструкция, позволяющая связать данные с методами, предназначенными для обработки этих данных
-
механизм языка, позволяющий ограничить доступ одних компонентов программы к другим
Правильная инкапсуляция важна по многим причинам:
-
Она способствует переиспользованию компонентов: поскольку в этом случае компоненты взаимодействуют друг с другом только посредством их API и безразличны к изменениям внутренней структуры, они могут использоваться в более широком контексте.
-
Инкапсуляция ускоряет процесс разработки: слабо связанные друг с другом компоненты (т.е. компоненты, чей код как можно меньше обращается или использует код других компонентов) могут разрабатываться, тестироваться и дополняться независимо.
-
Правильно инкапсулированные компоненты более легки для понимания и процесса отладки, что упрощает поддержку приложения.
В языке Java инкапсуляция реализована с помощью:
-
системы классов, которые позволяют собрать информацию об объекте в одном месте
-
пакетов, которые группируют классы по какому-либо критерию
-
модификаторов доступа, которыми можно пометить весь класс, его поля или методы
2.2.2. Inheritance
Когда один объект приобретает все свойства и поведение родительского объекта, то это называется inheritance (наследованием).
-
Наследование обеспечивает повторное использование кода.
-
Наследование используется для достижения полиморфизма во время выполнения.
Inheritance (Наследование) — принцип объектно-ориентированного программирования, позволяющий описать новый класс на основе уже существующего (родительского), при этом свойства и функциональность родительского класса заимствуются новым классом.
Другими словами, класс-наследник реализует спецификацию уже существующего класса (базовый класс). Это позволяет обращаться с объектами класса-наследника точно так же, как с объектами базового класса.
2.2.3. Простое наследование
Класс, от которого произошло наследование, называется базовым или родительским (англ. base class). Классы, которые произошли от базового, называются потомками, наследниками или производными классами (англ. derived class).
В некоторых языках используются абстрактные классы. Абстрактный класс — это класс, содержащий хотя бы один абстрактный метод (в Java можно и не иметь абстрактных методов), он описан в программе, имеет поля, методы и не может использоваться для непосредственного создания объекта. То есть от абстрактного класса можно только наследовать. Объекты создаются только на основе производных классов, наследованных от абстрактного. Например, абстрактным классом может быть базовый класс сотрудник вуза, от которого наследуются классы аспирант, профессор и т. д. Так как производные классы имеют общие поля и функции (например, поле год рождения), то эти члены класса могут быть описаны в базовом классе. В программе создаются объекты на основе классов аспирант, профессор, но нет смысла создавать объект на основе класса сотрудник вуза.
2.2.4. Множественное наследование
При множественном наследовании у класса может быть более одного предка. В этом случае класс наследует методы всех предков. Достоинства такого подхода в большей гибкости. Множественное наследование реализовано в C++. Из других языков, предоставляющих эту возможность, можно отметить Python и Eiffel. Множественное наследование поддерживается в языке UML.
Множественное наследование — потенциальный источник ошибок, которые могут возникнуть из-за наличия одинаковых имен методов в предках. В языках, которые позиционируются как наследники C++ (Java, C# и др.), от множественного наследования было решено отказаться в пользу интерфейсов. Практически всегда можно обойтись без использования данного механизма. Однако, если такая необходимость все-таки возникла, то, для разрешения конфликтов использования наследованных методов с одинаковыми именами, возможно, например, применить операцию расширения видимости — :: — для вызова конкретного метода конкретного родителя.
Попытка решения проблемы наличия одинаковых имен методов в предках была предпринята в языке Eiffel, в котором при описании нового класса необходимо явно указывать импортируемые члены каждого из наследуемых классов и их именование в дочернем классе.
Большинство современных объектно-ориентированных языков программирования (Java, C# и др.) поддерживают возможность одновременно наследоваться от класса-предка и реализовать методы нескольких интерфейсов одним и тем же классом. Этот механизм позволяет во многом заменить множественное наследование — методы интерфейсов необходимо переопределять явно, что исключает ошибки при наследовании функциональности одинаковых методов различных классов-предков.
2.2.5. Polymorphism
Polymorphism (Полиморфи́зм) — возможность объектов с одинаковой спецификацией иметь различную реализацию.
Язык программирования поддерживает полиморфизм, если классы с одинаковой спецификацией могут иметь различную реализацию — например, реализация класса может быть изменена в процессе наследования.
Кратко смысл полиморфизма можно выразить фразой:
Один интерфейс, множество реализаций.
Полиморфизм позволяет:
-
писать более абстрактные программы
-
повысить коэффициент повторного использования кода
Типы полиморфизма
Лука Карделли выделяют четыре разновидности полиморфизма:
-
универсальный
-
параметрический
-
включения (или подтипов)
-
-
ad-hoc
-
перегрузка
-
приведение типов
-
-
Параметрический полиморфизм — свойство семантики системы типов, позволяющее обрабатывать значения разных типов идентичным образом, то есть исполнять физически один и тот же код для данных разных типов. Например: Generics для Java.
Параметрический полиморфизм считается истинной формой полиморфизма, делая язык более выразительным и существенно повышая коэффициент повторного использования кода. -
Полиморфизм подтипов (Полиморфизм включения/inclusion polymorphism) является обобщённой формализацией подтипизации и наследования. Эти понятия не следует путать: подтипы определяют отношения на уровне интерфейсов, тогда как наследование определяет отношения на уровне реализации.
Подтипизация (subtyping), или полиморфизм подтипов (subtype polymorphism), означает, что поведение параметрически полиморфной функции ограничивается множеством типов, ограниченных в иерархию супертип — подтип. Например, если имеются типыNumber,RationalиInteger, ограниченные отношениямиNumber :> RationalиNumber :> Integer, то функция, определённая на типеNumber, также сможет принять на вход аргументы типовIntegerилиRational, и её поведение будет идентичным. Действительный тип объекта может быть скрыт как «чёрный ящик», и предоставляться лишь по запросу идентификации объекта. На самом деле, если типNumberявляется абстрактным, то конкретного объекта этого типа даже не может существовать (см. абстрактный класс). -
Ad-hoc-полиморфизм (в русской литературе чаще всего переводится как специальный полиморфизм или специализированный полиморфизм, хотя оба варианта не всегда верны) поддерживается во многих языках посредством перегрузки функций и методов, а в слабо типизированных — также посредством приведения типов.
2.2.6. Abstraction
Относительно недавно в качестве самостоятельного четвёртого принципа начали выделять abstraction (абстракцию).
Одно из определений слова абстракция, которые можно встретить в современных словарях:
Абстракция (от лат. abstractio — выделение, отвлечение или отделение) — теоретический прием исследования, позволяющий отвлечься от некоторых несущественных в определенном отношении свойств изучаемых явлений и выделить свойства существенные и определяющие.
Все языки программирования предоставляют их пользователю определённые абстракции. Так, языки семейства ассемблер являются в своём роде абстракцией соответствующих микропроцессоров, поскольку позволяют отвлечься от деталей их реализации и общаться с ними через определённый набор более высокоуровневых инструкций. Императивные языки программирования, последовавшие за ассемблером, например Basic, Fortran, C, являются более высоким уровнем абстракции над ассемблерными языками – они дают возможность использовать более привычные человеку синтаксические конструкции за счёт приближения синтаксиса к естественным языкам.
Объектно-ориентированные языки, такие как Java, выводят разработку на ещё более высокий уровень абстракции: объекты в ООП по своей сути представляют собой модели понятий окружающего мира, таких как Работник, Сервер, Запись в дневнике, и выделяют только те свойства этого понятия, которые необходимы в конкретном случае для решения конкретной проблемы.
2.3. Coupling and Cohesion
2.3.1. Coupling
Связность относится к знаниям/информации/зависимости одного класса о другом классе. Если у класса есть подробная информация о другом классе, существует strong coupling.
В Java используются private, protected, public модификаторы для отображения уровня видимости класса, метода и поля.
Можно использовать интерфейсы для weak coupling, потому что нет конкретной реализации.
2.3.2. Cohesion
Сплоченность относится к уровню компонента, который выполняет одну четко определенную задачу. Одна четко определенная задача выполняется highly cohesive методом. weakly cohesive метод разделит задачу на отдельные части.
Например: пакет java.io представляет собой highly cohesive пакет, поскольку он имеет связанные с вводом/выводом классы и интерфейс. Тем не менее, пакет java.util является weakly cohesive пакетом, потому что он имеет несвязанные классы и интерфейсы.
2.4. Типы взаимоотношений классов
2.4.1. Association
Ассоциация представляет отношения между объектами. Здесь один объект может быть связан с одним или несколькими объектами. Между объектами может быть четыре типа связи:
-
One to One
-
One to Many
-
Many to One
-
Many to Many
Например, одна страна может иметь одного президента (One to One), а президент может иметь много министров (One to Many). Кроме того, у многих членов парламента может быть один президент (Many to One), а у многих министров может быть много департаментов (Many to Many).
Ассоциация может быть:
-
undirectional
-
bidirectional
Ассоциация достигается с помощью:
-
Inheritance
-
Aggregation
-
Composition
2.4.2. Aggregation
Агрегация - это способ достижения ассоциации. Агрегация представляет собой отношение, в котором один объект содержит другие объекты как часть своего состояния.
Агрегация представляет weak relationship между объектами, так как содержащий объект хоть и содержит зависимый, но время их жизни не связано. Если будет удален родительский объект, то дочерние объекты не будут удалены.
Агрегация также называется связью has-a в Java. Мол, наследование представляет собой отношения is-a .
Агрегация еще один способ повторного использования объектов.
2.4.3. Composition
Композиция представляет отношение, в котором один объект содержит другие объекты как часть своего состояния.
Композиция также является способом достижения ассоциации.
Существует strong relationship между содержащим объектом и зависимым объектом. Это состояние, в котором содержащиеся объекты не имеют самостоятельного существования. Если вы удалите родительский объект, все дочерние объекты будут удалены автоматически.
2.5. Преимущество ООП над процедурно-ориентированным языком программирования
-
ООП облегчает разработку и сопровождение, в то время как в языке программирования, ориентированного на процедуры, нелегко управлять, если код увеличивается с увеличением размера проекта.
-
ООП обеспечивает скрытие данных, тогда как в языке программирования, ориентированного на процедуры, глобальные данные могут быть доступны из любого места.
-
ООП дает возможность имитировать события в реальном мире гораздо более эффективно. Мы можем обеспечить решение проблемы с реальными словами, если мы используем язык объектно-ориентированного программирования.
2.6. В чем разница между object-oriented языком программирования и object-based языком программирования?
Object-based язык программирования следует всем функциям ООП, кроме наследования. JavaScript и VBScript являются примерами object-based языков программирования.
3. Структуры данных
Никлаус Вирт, швейцарский информатик, написал в 1976 году книгу под названием Алгоритмы + структуры данных = программы.
Больше сорока лет спустя это уравнение все еще верно. Почти все задачи программирования требуют от разработчика глубокого понимания структур данных, для того что бы выбрать наиболее подходящую для задачи, которая перед ним стоит.
3.1. Что такое структуры данных?
Простыми словами, структура данных – это контейнер, который хранит информацию в определенном виде. Из-за такой «компоновки» она может быть эффективной в одних операциях и неэффективной в других. Цель разработчика – выбрать из существующих структур оптимальный для конкретной задачи вариант.
3.2. Зачем нужны структуры данных?
Данные являются самой важной сущностью в информатике, а структуры позволяют хранить их в организованной форме.
Какая бы роблема не решалась, приходится иметь дело с данными — будь то зарплата сотрудника, цены на акции, список покупок или даже простой телефонный справочник.
В зависимости от ситуации данные должны храниться в некотором определенном формате. Структуры данных предлагают несколько вариантов таких размещений.
Наиболее часто используемые структуры:
-
Массив (Array)
-
Стек (Stack)
-
Очередь (Queue)
-
Связный список (Linked List)
-
Дерево (Tree)
-
Граф (Graph)
-
Префиксное дерево (Trie)
-
Хэш-Таблица (Hash Table)
3.3. Массивы
Массив – это самая простая и наиболее широко используемая из структур. Стеки и очереди являются производными от массивов.
Вот изображение простого массива размером 4, содержащего элементы (1, 2, 3 и 4).
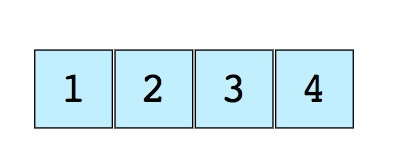
Каждому из них присваивается неотрицательное числовое значение – индекс, который соответствует позиции этого элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Существует два типа массивов:
-
Одномерные массивы.
-
Многомерные массивы (массивы массивов).
Основные операции с массивами
-
Insert – вставка.
-
Get – получение элемента.
-
Delete – удаление.
-
Size – получение общего количества элементов в массиве.
3.4. Стеки
Мы все знакомы с опцией Отменить (Undo), которая присутствует практически в каждом приложении. Вы когда-нибудь задумывались, как это работает?
Для этого вы сохраняете предыдущие состояния приложения (определенное их количество) в памяти в таком порядке, что последнее сохраненное появляется первым. Это не может быть сделано только с помощью массивов. Здесь на помощь приходит стек.
Пример стека из реальной жизни – куча книг, лежащих друг на друге. Чтобы получить книгу, которая находится где-то в середине, вам нужно удалить все, что лежит сверху. Так работает метод LIFO (Last In First Out, последним пришел – первым ушел).
Вот изображение стека, содержащего три элемента (1, 2 и 3). Элемент 3 находится сверху и будет удален первым:
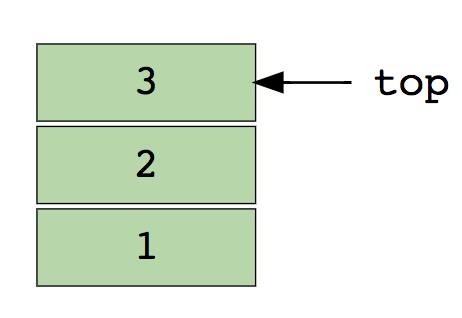
Основные операции со стеками:
-
Push – вставка элемента наверх стека.
-
Pop – получение верхнего элемента и его удаление.
-
isEmpty – возвращает true, если стек пуст.
-
Top – получение верхнего элемента без удаления.
3.5. Очереди
Как и стек, очередь – это линейная структура данных, которая хранит элементы последовательно. Единственное существенное различие заключается в том, что вместо использования метода LIFO, очередь реализует метод FIFO (First in First Out, первым пришел – первым ушел).
Идеальный пример этих структур в реальной жизни – очереди людей в билетную кассу. Если придет новый человек, он присоединится к линии с конца, а не с начала. А человек, стоящий впереди, первым получит билет и, следовательно, покинет очередь.
Вот изображение очереди, содержащей четыре элемента (1, 2, 3 и 4). Здесь 1 находится вверху и будет удален первым:
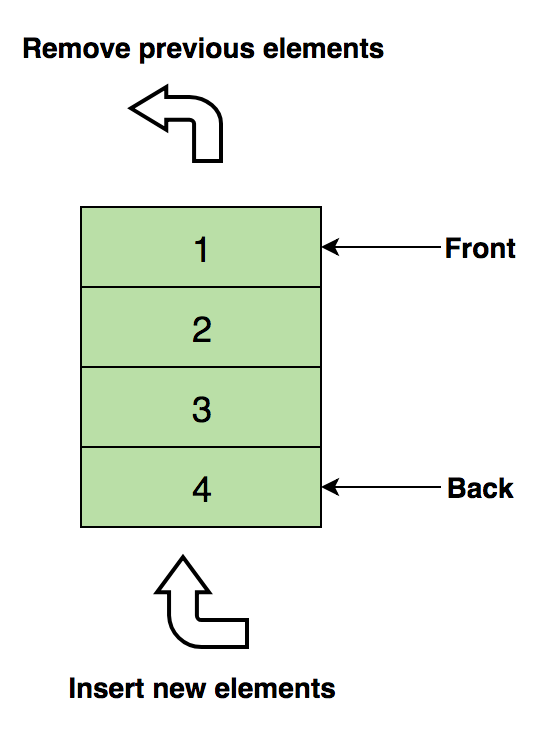
*Основные операции *с очередями:
-
Enqueue – вставка в конец.
-
Dequeue – удаление из начала.
-
isEmpty – возвращает true, если очередь пуста.
-
Top – получение первого элемента.
3.6. Связный список
Еще одна важная линейная структура данных, которая на первый взгляд похожа на массив, но отличается распределением памяти, внутренней организацией и способом выполнения основных операций вставки и удаления.
Связный список – это сеть узлов, каждый из которых содержит данные и указатель на следующий узел в цепочке. Также есть указатель на первый элемент – head. Если список пуст, то он указывает на null.
Связные списки используются для реализации файловых систем, хэш-таблиц и списков смежности.
Вот визуальное представление внутренней структуры связного списка:

Типы связных списков:
-
Однонаправленный
-
Двунаправленный
Основные операции со связными списками
-
InsertAtEnd – вставка в конец.
-
InsertAtHead – вставка в начало.
-
Delete – удаление указанного элемента.
-
DeleteAtHead – удаление первого элемента.
-
Search – получение указанного элемента.
-
isEmpty – возвращает true, если связный список пуст.
3.7. Графы
Граф представляет собой набор узлов, соединенных друг с другом в виде сети. Узлы также называются вершинами. Пара (x, y) называется ребром, которое указывает, что вершина x соединена с вершиной y. Ребро может содержать вес/стоимость, показывая, сколько затрат требуется, чтобы пройти от x до y.
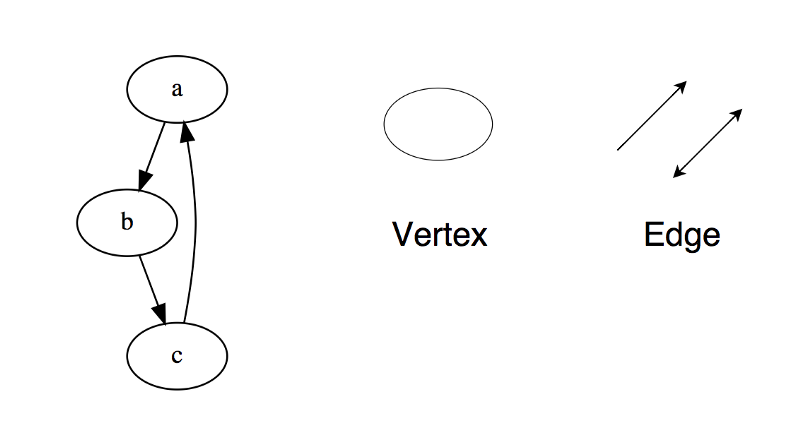
Типы графов:
-
Неориентированный
-
Ориентированный
В языке программирования графы могут быть представлены в двух формах:
-
Матрица смежности
-
Список смежности
Общие алгоритмы обхода графов:
-
В ширину
-
В глубину
3.8. Деревья
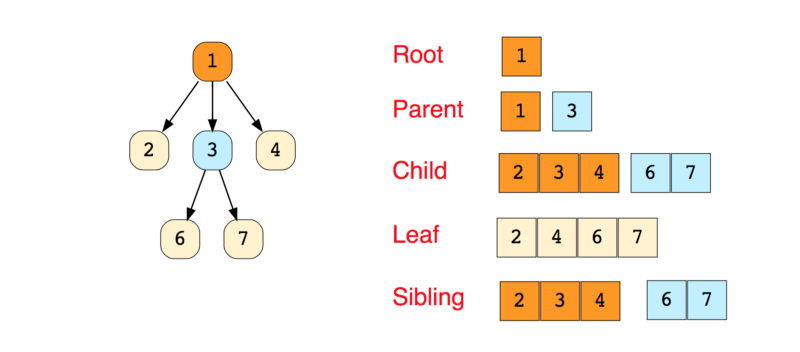
Дерево – это иерархическая структура данных, состоящая из вершин (узлов) и ребер, соединяющих их. Они похожи на графы, но есть одно важное отличие: в дереве не может быть цикла.
Деревья широко используются в искусственном интеллекте и сложных алгоритмах для обеспечения эффективного механизма хранения данных.
Вот изображение простого дерева, и основные термины:
Типы деревьев:
-
N-арное дерево;
-
сбалансированное дерево;
-
бинарное дерево;
-
бинарное дерево поиска;
-
дерево AVL;
-
красно-чёрное дерево;
-
2-3 дерево.
Из всех типов чаще всего используются бинарное дерево и бинарное дерево поиска.
3.9. Префиксное дерево
Префиксные деревья (tries) – древовидные структуры данных, эффективные для решения задач со строками. Они обеспечивают быстрый поиск и используются преимущественно для поиска слов в словаре, автодополнения в поисковых системах и даже для IP-маршрутизации.
Вот иллюстрация того, как три слова top, thus и their хранятся в префиксном дереве:
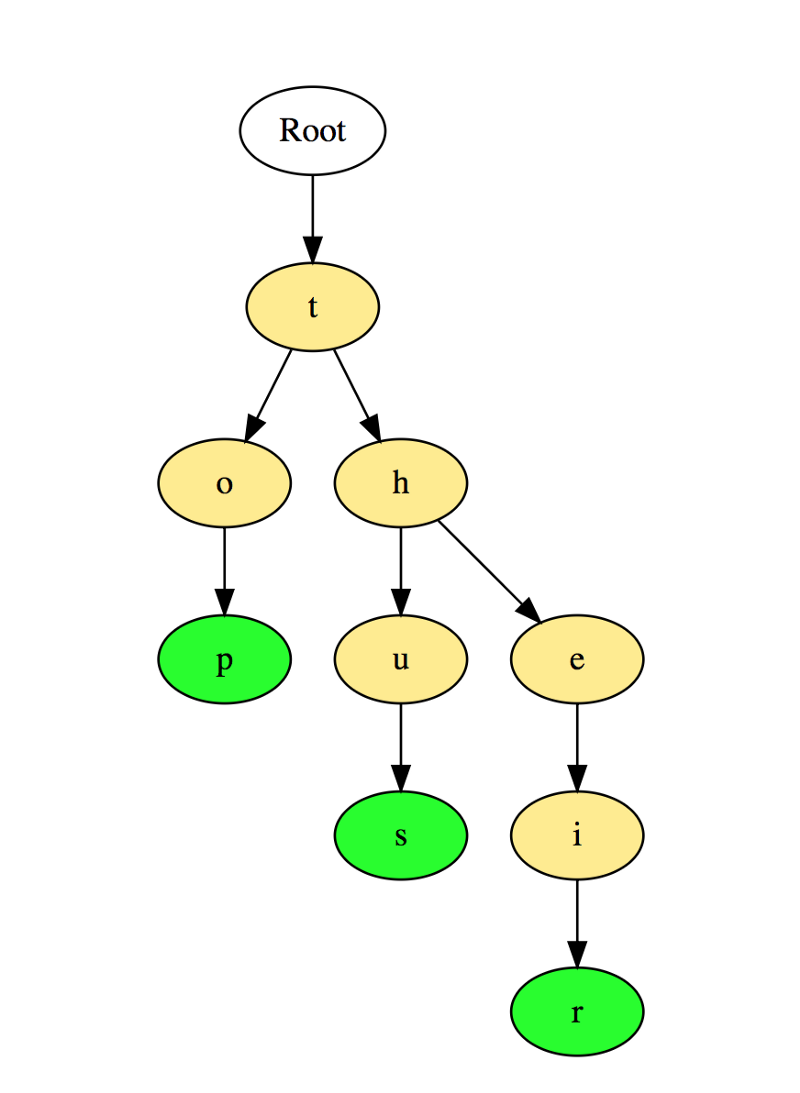
Слова размещаются сверху вниз. Выделенные зеленым элементы показывают конец каждого слова.
3.10. Хеш-Таблица
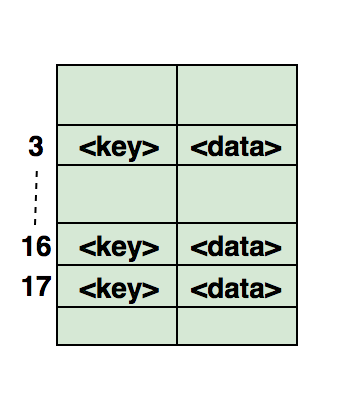
Хеширование – это процесс, используемый для уникальной идентификации объектов и хранения каждого из них в некотором предварительно вычисленном уникальном индексе – ключе. Итак, объект хранится в виде пары ключ-значение, а коллекция таких элементов называется словарем. Каждый объект можно найти с помощью его ключа. Существует несколько структур, основанных на хешировании, но наиболее часто используется хеш-таблица, которая обычно реализуется с помощью массивов.
Производительность структуры зависит от трех факторов:
-
функция хеширования
-
размер хеш-таблицы
-
метод обработки коллизий
Вот иллюстрация того, как хэш отображается в массиве. Индекс вычисляется с помощью хеш-функции.
4. Design Principles
4.1. DRY
DRY - Don’t Repeat Youself - не повторяйся, также известен как DIE - Duplication Is Evil - дублирование это зло. Его суть в том, что нужно избегать повторений одного и того же кода. Лучше использовать универсальные свойства и функции.
4.2. KISS
KISS - Keep It Simple, Stupid - не усложняй. Его суть в том, что стоит делать максимально простую и понятную архитектуру, применять шаблоны проектирования и не изобретать велосипед.
4.3. YAGNI
YAGNI - You Ain’t Gonna Need It - вам это не понадобится. Его суть в том, чтобы реализовать только поставленные задачи и отказаться от избыточного функционала.
5. SOLID
SOLID — это аббревиатура пяти основных принципов проектирования в объектно-ориентированном программировании — Single responsibility, Open-closed, Liskov substitution, Interface segregation и Dependency inversion. В переводе на русский: принципы единственной ответственности, открытости/закрытости, подстановки Барбары Лисков, разделения интерфейса и инверсии зависимостей)
Аббревиатура SOLID была предложена Робертом Мартином, инженером и автором нескольких книг, широко известных в сообществе разработчиков. Первое упоминание SOLID было в 2000-ом году в книге Design Principles and Design Patterns. Принципы SOLID позволяют строить на базе ООП масштабируемые и сопровождаемые программные продукты с понятной бизнес-логикой.
-
Single Responsibility Principle (SRP, Принцип единственной обязанности / ответственности)
обозначает, что каждый объект должен иметь одну обязанность и эта обязанность должна быть полностью инкапсулирована в класс. Все его сервисы должны быть направлены исключительно на обеспечение этой обязанности. -
Open-Closed Principle (OCP, Принцип открытости/закрытости)
декларирует, что программные сущности (классы, модули, функции и т. п.) должны быть открыты для расширения, но закрыты для изменения. Это означает, что эти сущности могут менять свое поведение без изменения их исходного кода. -
Liskov substitution principle (LSP, Принцип подстановки Барбары Лисков)
в формулировке Роберта Мартина: «функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа не зная об этом». -
Interface Segregation Principle (ISP, Принцип разделения интерфейса)
в формулировке Роберта Мартина: «клиенты не должны зависеть от методов, которые они не используют». Принцип разделения интерфейсов говорит о том, что слишком «толстые» интерфейсы необходимо разделять на более маленькие и специфические, чтобы клиенты маленьких интерфейсов знали только о методах, которые необходимы им в работе. В итоге при изменении метода интерфейса не должны меняться клиенты, которые этот метод не используют. -
Dependency Inversion Principle (DIP, Принцип инверсии зависимостей)
модули верхних уровней не должны зависеть от модулей нижних уровней, а оба типа модулей должны зависеть от абстракций; сами абстракции не должны зависеть от деталей, а вот детали должны зависеть от абстракций.
5.1. Single Responsibility Principle
Принцип декларирует, что каждый объект должен иметь одну обязанность и эта обязанность должна быть полностью инкапсулирована в класс, а все его сервисы должны быть направлены исключительно на обеспечение этой обязанности.
Следование принципу заключается обычно в декомпозиции сложных классов, делающих сразу много вещей, на простые, ответственность которых очень специализирована. Но также и объединении в отдельный класс однотипной функциональности, которая может оказаться распределённой по многим классам, может рассматриваться как следование этому принципу.
Проектирование классов с направленностью на обеспечение единственной обязанности упрощает дальнейшие модификации и сопровождение, так как проще разобраться в одном блоке функциональности, нежели распутывать сложные взаимосвязи между различными функциональными блоками. Также при модификации логики в одном месте приложения снижаются риски возникновения проблем в других «неожиданных» его местах.
Следование SRP весьма полезная практика с точки зрения повторного использования кода. Сложные объекты с комплексными зависимостями обычно очень сложно использовать повторно, особенно если нужна только часть реализованного в них функционала. А небольшие классы с чётко очерченным функционалом, напротив, проще использовать повторно, так как они не избыточные и редко тянут за собой существенный объём зависимостей.
Наиболее ярким анти-паттерном, нарушающим принцип единственной ответственности, является использование God-объектов, которые «слишком много знают» или «слишком много умеют». Возникают такие «божественные объекты» обычно из-за любви разработчиков к абстракции — если возводить абстракцию в абсолют, то вполне можно любой объект реального мира отразить в приложении в виде экземпляра некого универсального класса. На словах это даже может выглядеть логично, но на практике почти всегда это приводит к проблемам сопровождаемости. Обычно такие объекты становятся центральной частью системы, а их модификация крайне сложна, так как становится очень сложно предсказать, как изменение кода для решения текущей задачи может сказаться на ранее реализованной функциональности.
На самом деле, как и любые другие принципы, SRP требует сознательного и осмысленного применения. Чрезмерная декомпозиция может оказаться и вредной, если она приводит к большей сложности или усложняет сопровождение.
Например, часто используемый в фреймворках паттерн ActiveRecord (Active Record by Martin Fowler (EN), Wikipedia (RU)) нарушает принцип единственной ответственности. ActiveRecord реально объединяет в себе очень много функциональных возможностей и часто смешивает бизнес-логику и работу со слоем хранения. При этом использование ActiveRecord часто является удобным и целесообразным. На этом примере становится ясно, что SRP — это не догма, а нарушение этого принципа вполне может быть логичным и целесообразным.
5.2. Open-Closed Principle
Принцип декларирует, что программные сущности (классы, модули, функции и т. п.) должны быть открыты для расширения, но закрыты для изменения. Это означает, что эти сущности могут менять свое поведение без изменения их исходного кода.
В этом контексте открытость для расширения — это возможность добавить для класса, модуля или функции новое поведение, если необходимость в этом возникнет, а закрытость для изменений — это запрет на изменение исходного кода программных сущностей. На первый взгляд, это звучит сложно и противоречиво. Но если разобраться, то принцип вполне логичен.
Следование принципу OCP заключается в том, что программное обеспечение изменяется не через изменение существующего кода, а через добавление нового кода. То есть созданный изначально код остаётся «нетронутым» и стабильным, а новая функциональность внедряется либо через наследование реализации, либо через использование абстрактных интерфейсов и полиморфизм.
Термин принцип открытости/закрытости имеет два значения:
-
Принцип открытости/закрытости Мейера
-
Полиморфный принцип открытости/закрытости
Оба значения используют наследование для решения дилеммы, но цели, способы и результаты — различны.
|
Note
|
Бертран Мейер - создатель языка программирования Eiffel (Эйфель), а так же как основоположник термина Принцип открытости/закрытости, который появился в 1988 году в его книге Object-Oriented Software Construction |
Принцип открытости/закрытости Мейера основывается на идее, что разработанная изначально реализация класса в дальнейшем не модифицируется (разве что исправляются ошибки), а любые изменения производятся через создание нового класса, который обычно наследуется от изначального. Согласно определению Мейера реализация интерфейса может быть унаследована и переиспользована, но интерфейс может и измениться в новой реализации.
Позже был сформулирован полиморфный принцип открытости/закрытости. Он основывается на строгой реализации интерфейсов и на наследовании от абстрактных базовых классов или на полиморфизме. Созданный изначально интерфейс должен быть закрыт для модификаций, а новые реализации как минимум соответствуют этому изначальному интерфейсу, но могут поддерживать и другие, более расширенные.
5.3. Liskov substitution principle
Принцип в формулировке Роберта Мартина декларирует, что функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа не зная об этом. Оригинальное определение Барбары Лисков более формальное и заметно сложнее для восприятия: «В том случае, если q(x) — свойство, верное по отношению к объектам х некого типа T, то свойство q(y) тоже будет верным относительно ряда объектов y, которые относятся к типу S, при этом S — подтип некого типа T».
Следование принципу LSP заключается в том, что при построении иерархий наследования создаваемые наследники должны корректно реализовывать поведение базового типа. То есть если базовый тип реализует определённое поведение, то это поведение должно быть корректно реализовано и для всех его наследников.
LSP перекликается с контрактным программированием, определяя точные, формальные и верифицируемые описания интерфейсов. И интерфейсы, реализуемые наследниками, должны соответствовать контракту интерфейсов базового класса.
Наследник класса дополняет, но не заменяет поведение базового класса. То есть в любом месте программы замена базового класса на класс-наследник не должна вызывать проблем. Если по каким-то причинам это не получается, то вероятнее всего имеет место либо некорректная реализация, либо неверно выбранная абстракция для наследования.
Соблюдение принципа подстановки Барбары Лисков позволяет гарантировать, что любой созданный нами подкласс будет без проблем использоваться ранее реализованными модулями, которые работали с суперклассом. А это существенно упрощает расширение функциональных возможностей системы.
Но LSP, как и любой другой принцип, не является догмой. И иногда следование этому принципу при построении архитектуры может приводить к более ресурсоёмкой реализации, нежели работа с нарушением этого принципа. Но, как и с любыми другими правилами — надо осознавать возможные последствия нарушения.
5.4. Interface Segregation Principle
Принцип в формулировке Роберта Мартина декларирует, что клиенты не должны зависеть от методов, которые они не используют. То есть если какой-то метод интерфейса не используется клиентом, то изменения этого метода не должны приводить к необходимости внесения изменений в клиентский код.
Следование принципу ISP заключается в создании интерфейсов, которые достаточно специфичны и требуют только необходимый минимум реализаций методов. Избыточные интерфейсы, напротив, могут требовать от реализующего класса создание большого количества методов, причём даже таких, которые не имеют смысла в контексте класса.
В чём-то принцип разделения интерфейса перекликается с принципом единственной ответственности — интерфейсы не должны быть избыточно «толстыми», если вдруг в приложении формируется слишком объёмный интерфейс, то есть высокая вероятность, что так происходит из-за того, что в этом интерфейсе слишком много разных ответственностей, а значит логичнее всего провести декомпозицию сложного интерфейса на несколько простых.
Принцип разделения интерфейса снижает сложность поддержки и развития приложения. Чем проще и минималистичнее используемый интерфейс, тем менее ресурсоёмкой является его реализация в новых классах, тем меньше причин его модифицировать, но и в случае модификации она будет значительно проще.
5.5. Dependency Inversion Principle
Принцип декларирует, что модули верхних уровней не должны зависеть от модулей нижних уровней, а оба типа модулей должны зависеть от абстракций; сами абстракции не должны зависеть от деталей, а вот детали должны зависеть от абстракций.
Следование принципу инверсии зависимостей «заставляет» реализовывать высокоуровневые компоненты без встраивания зависимостей от конкретных низкоуровневых классов, что, например, сильно упрощает замену используемых зависимостей как по бизнес-требованиям, так и для целей тестирования. При этом зависимость формируется не от конкретной реализации, а от абстракции — реализуемого зависимостью интерфейса.
Например, мы реализуем хранение документов в веб-приложении. На первый взгляд, кажется логичным добавить зависимость от модулей работы с файловой системой непосредственно в класс, отвечающий за высокоуровневую работу с этими документами. Но в перспективе такая зависимость может создать проблемы — например, нам потребуется хранить данные не только на диске, но и в облаке. Если зависимость внедрена от реализации, то мы столкнёмся с необходимостью её переработки. Если же зависимость выведена на уровень абстракции (интерфейса), то нам будет достаточно реализовать функционал работы с облаком, соответствующий ранее созданному интерфейсу работы с файлами.
Принцип инверсии зависимостей часто упрощает следованию принципу подстановки Барбары Лисков. Выделение абстракций и встраивание зависимостей от них снижает вероятность того, что в новом классе мы не полностью реализуем контракт базового класса, который мы расширяем в рамках нового.
5.6. Links
6. IoC, DI, DIP
Существует три схожих понятия, связанных передачей и управлением зависимостями, в каждом из которых есть слово inversion (инверсия) или dependency (зависимость):
-
IoC – Inversion of Control (Инверсия управления)
-
DI – Dependency Injection (Внедрение зависимостей)
-
DIP – Dependency Inversion Principle (Принцип инверсии зависимостей)
Подливает масло в огонь рассогласованность использования этих терминов. Так, например, контейнеры иногда называют DI-контейнерами, а иногда IoC-контейнерами. Большинство разработчиков не различает DI и DIP, хотя за каждой из этих аббревиатур скрываются разные понятия.
6.1. Inversion of Control (IoC)
Инверсия управления (IoC, Inversion of Control) – это достаточно общее понятие, которое отличает библиотеку от фреймворка. Классическая модель подразумевает, что вызывающий код контролирует внешнее окружение и время и порядок вызова библиотечных методов. Однако в случае фреймворка обязанности меняются местами: фреймворк предоставляет некоторые точки расширения, через которые он вызывает определенные методы пользовательского кода.
Простой callback (метод обратного вызова) или любая другая форма паттерна Observer (Наблюдатель) является примером инверсии. Зная значение понятия IoC становится ясно, что такое понятие как IoC-контейнер лишено смысла, если только данный «контейнер» не предназначен для упрощения создания фреймворков.
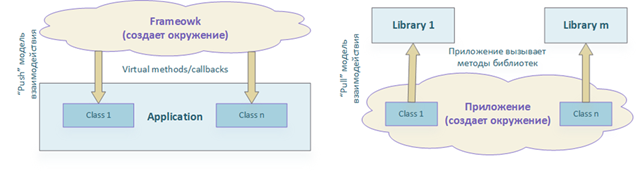
6.2. Dependency Injection (DI)
Dependency Injection (DI, Внедрение зависимостей) – это механизм передачи классу его зависимостей.
Использование DI является не конечной целью, а средством достижения определенного результата. Технология DI позволяет применять weak coupling (слабое связывание), которое, в свою очередь, повышает maintainability (сопровождаемость) кода.
|
Note
|
Maintainability (сопровождаемость) кода определяет насколько легко и просто посторонний человек может разобраться в том, что творится в предоставленном ему коде. Хорошо сопровождаемый код так же называют clean code (чистым кодом). Чем лучше и чище написан код, тем легче вникнуть в задачу новому сотруднику и тем меньше времени и усилий требуется создателю кода на объяснение, что в нем происходит. В идеале, обращения к создателю быть не должно, все должно быть понятно по самому коду и комментариям. |
6.2.1. Преимущества
| Преимущество | Описание | Когда ценится? |
|---|---|---|
Late binding (Позднее связывание) |
Службы могут заменяться другими службами без перекомпиляции кода |
Ценится в стандартных программных продуктах, но в меньшей степени в корпоративных приложениях с четко заданной средой выполнения. |
Extensibility (Расширяемость) |
Код может быть расширен и повторно использован тем способом, который ранее не был явно запланирован |
Ценится всегда |
Parallel development (Параллельная разработка) |
Код может разрабатываться в параллельном режиме |
Ценится в больших, сложных приложениях, и меньше — в небольших, простых приложениях |
Maintainability (Сопровождаемость) |
Классы с четко выраженной ответственностью проще сопровождать |
Ценится всегда |
Testability (Пригодность к тестированию) |
Классы могут подвергаться модульному тестированию |
Ценится всегда |
6.2.2. Виды DI
Существует несколько конкретных видов или паттернов внедрения зависимостей:
-
внедрение зависимости через конструктор (Constructor Injection)
-
внедрение зависимости через метод (Method Injection)
-
внедрение зависимости через свойство (Property Injection)
class ReportProcessor {
private ReportSender reportSender;
private Logger logger;
// Constructor Injection: передача обязательной зависимости
public ReportProcessor(ReportSender reportSender) {
this.reportSender = reportSender;
}
// Method Injection: передача обязательных зависимостей метода
public void sendReport(Report report, ReportFormatter formatter) {
logger.info("Sending report...");
var formattedReport = formatter.format(report);
reportSender.sendReport(formattedReport);
logger.info("Report has been sent");
}
// Method Injection: установка необязательных "инфраструктурных" зависимостей
public void setLogger(Logger logger) {
this.logger = logger;
}
public Logger getLogger() {
return this.logger;
}
}Разные виды внедрения зависимостей предназначены для решения определенных задач. Через конструктор передаются обязательные зависимости класса, без которых работа класса невозможна (ReportSender - обязательная зависимость класса ReportProcessor). Через метод передаются зависимости, которые нужны лишь одному методу, а не всем методам класса (ReportFormatter необходим только методу отправки отчета, а не классу ReportProcessor целиком). Через свойства должны устанавливаться лишь необязательные зависимости (обычно, инфраструктурные), для которых существует значение по умолчанию (свойство Logger содержит разумное значение по умолчанию, но может быть заменено позднее).
Очень важно понимать, что DI-паттерны не говорят, что за зависимость передается, к какому уровню она относится, должна ли быть она у этого класса или нет. Это лишь инструмент передачи зависимостей от одного класса другому.
6.3. Dependency Inversion Principle (DIP)
Принцип инверсии зависимости говорит о том, к каким видам зависимостей нужно стремиться. Важно, чтобы зависимости класса были понятны и важны вызывающему коду. Зависимости класса должны располагаться на текущем или более высоком уровне абстракции. Другими словами, не любой класс, который требует интерфейс в конструкторе следует принципу инверсии зависимостей:
class ReportProcessor {
private Socket socket;
public ReportProcessor(Socket socket) {
this.socket = socket;
}
public void sendReport(Report report, StringBuilder stringBuilder) {
stringBuilder.append(createHeader(report));
stringBuilder.append(createBody(report));
stringBuilder.append(createFooter(report));
socket.connect();
socket.send(convertToByteArray(stringBuilder));
}
// ...
}Класс ReportProcessor все еще принимает «абстракцию» в аргументах конструктора - Socket, но эта «абстракция» находится на несколько уровней ниже уровня формирования и отправки отчетов. Аналогично дела обстоят и с аргументом метода SendReport: «абстракция» StringBuilder не соответствует принципу инверсии зависимостей, поскольку оперирует более низкоуровневыми понятиями, чем требуется. На этом уровне нужно оперировать не строками, а отчетами.
В результате в данном примере используется внедрение зависимостей (DI), но данный код не следует принципу инверсии зависимостями (DIP).
6.4. Итоги
Инверсия управления (IoC) говорит об изменении потока исполнения, присуща фреймворкам и функциям обратного вызова и не имеет никакого отношения к управлению зависимостями. Передача зависимостей (DI) - это инструмент передачи классу его зависимости через конструктор, метод или свойство. Принцип инверсии зависимостей (DIP) - это принцип проектирования, который говорит, что классы должны зависеть от высокоуровневых абстракций.