Wiki for a common theme.
1. Patterns
1.1. DAO
1.1.1. Контекст
Способ доступа к данным бывает разным и зависит от источника данных. Способ доступа к персистентному хранилищу, например к базе данных, очень зависит от типа этого хранилища (реляционные базы данных, объектно-ориентированные базы данных, однородные или «плоские» файлы и т.д.) и от конкретной реализации.
1.1.2. Проблема
Многие реальные приложения платформы Jakarta EE должны использовать на некотором этапе персистентные данные. Для этих приложений персистентное хранение реализуется различными механизмами и существуют значительные отличия в API, используемых для доступа к этим механизмам. Другим приложениям может понадобиться доступ к данным, расположенным на разных системах. Например, данные могут находиться на мэйнфреймах, LDAP-репозиториях (Lightweight Directory Access Protocol - облегченный протокол доступа к каталогам) и т.д. Другим примером является ситуация, когда данные предоставляются службами, выполняющимися на разных внешних системах, таких как системы business-to-business (B2B), системы обслуживания кредитных карт и др.
Обычно приложения совместно используют распределенные компоненты для представления персистентных данных, например, компоненты управления данными. Считается, что приложение использует управляемую компонентом персистенцию (BMP - bean-managed persistence) для своих компонентов управления данными, если эти компоненты явно обращаются к персистентным данным — то есть компонент содержит код прямого доступа к хранилищу данных. Приложение с более простыми требованиями может вместо компонентов управления данными использовать сессионные компоненты или Servlets с прямым доступом к хранилищу данных для извлечения и изменения данных. Также, приложение могло бы использовать компоненты управления данными с управляемой контейнером персистенцией, передавая, таким образом, контейнеру функции управления транзакциями и деталями персистенции.
Для доступа к данным, расположенным в системе управления реляционными базами данных (RDBMS), приложения могут использовать JDBC API. JDBC API предоставляет стандартный механизм доступа и управления данными в персистентном хранилище, таком как реляционная база данных. JDBC API позволяет в Jakarta EE-приложениях использовать SQL-команды, являющиеся стандартным средством доступа к RDBMS-таблицам. Однако, даже внутри среды RDBMS фактический синтаксис и формат SQL-команд может сильно зависеть от конкретной базы данных.
Для различных типов персистентных хранилищ существует еще большее число вариантов. Механизмы доступа, поддерживаемые API и функции отличаются для различных типов персистентных хранилищ, таких как RDBMS, объектно-ориентированные базы данных, плоские файлы и т.д. Приложения, которым нужен доступ к данным, расположенным на традиционных или несовместимых системах (например, мэйнфреймы или B2B-службы), часто вынуждены использовать патентованные API. Такие источники данных представляют проблему для приложений и могут потенциально создавать прямую зависимость между кодом приложения и кодом доступа к данным. Когда бизнес-компонентам (компонентам управления данными, сессионным компонентам и даже презентационным компонентам, таким как Servlets и вспомогательные объекты для JSP-страниц) необходим доступ к источнику данных, они могут использовать соответствующий API для получения соединения и управления этим источником данных. Но включение кода для установления соединения и доступа к данным в код этих компонентов создает тесную связь между компонентами и реализацией источника данных. Такая зависимость кода в компонентах может сделать миграцию приложения от одного типа источника данных к другому трудной и громоздкой. При изменениях источника данных компоненты необходимо изменить.
1.1.3. Ограничения
-
Компоненты управления данными с управляемой компонентом персистенцией, сессионные компоненты, Servlets и другие объекты, такие как вспомогательные объекты для JSP-страниц, должны получать и сохранять информацию в персистентных хранилищах и других источниках данных, например традиционных системах, B2B, LDAP и т.д.
-
API доступа к персистентному хранилищу данных может зависеть от поставщика продукта. Другие источники данных могут иметь нестандартные или патентованные API. Эти API и их возможности зависят от типа хранилища данных - RDBMS, система управления объектно-ориентированными базами данных (OODBMS), XML-документы, плоские файлы и т.д. Унифицированный API доступа к этим несовместимым системам отсутствует.
-
Для извлечения или сохранения данных во внешних и/или традиционных системах компоненты обычно используют патентованные API.
-
Включение в компоненты специфических механизмов доступа и API прямо влияет на переносимость компонентов.
-
Компоненты должны быть прозрачны для реальной реализации персистентного хранилища или источника данных и обеспечивать легкую миграцию на продукт другого поставщика, на другой тип хранилища и на другой тип источника данных.
1.1.4. Решение
|
Note
|
Используйте Data Access Object (DAO) для абстрагирования и инкапсулирования доступа к источнику данных. DAO управляет соединением с источником данных для получения и записи данных. |
DAO реализует необходимый для работы с источником данных механизм доступа. Источником данных может быть персистентное хранилище (например, RDBMS), внешняя служба (например, B2B-биржа), репозиторий (LDAP-база данных), или бизнес-служба, обращение к которой осуществляется при помощи протокола CORBA Internet Inter-ORB Protocol (IIOP) или низкоуровневых сокетов. Использующие DAO бизнес-компоненты работают с более простым интерфейсом, предоставляемым объектом DAO своим клиентам. DAO полностью скрывает детали реализации источника данных от клиентов. Поскольку при изменениях реализации источника данных представляемый DAO интерфейс не изменяется, этот паттерн дает возможность DAO принимать различные схемы хранилищ без влияния на клиентов или бизнес-компоненты. По существу, DAO выполняет функцию адаптера между компонентом и источником данных.
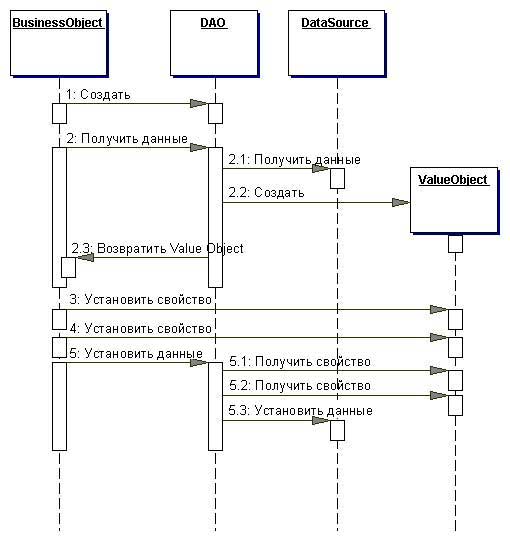
Структура
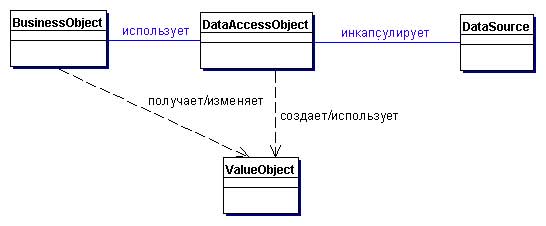
Участники и обязанности
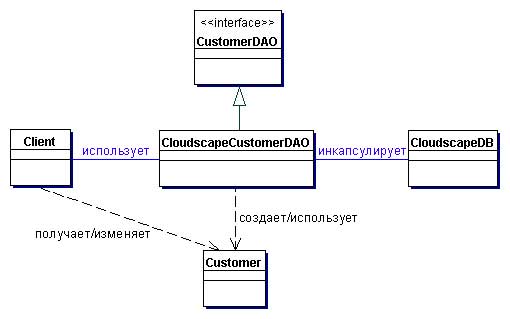
BusinessObject
BusinessObject представляет клиента данных. Это объект, который нуждается в доступе к источнику данных для получения и сохранения данных. BusinessObject может быть реализован как сессионный компонент, компонент управления данными или другой Java-объект, Servlet или вспомогательный компонент.
DataAccessObject
DataAccessObject является первичным объектом данного паттерна. DataAccessObject абстрагирует используемую реализацию доступа к данным для BusinessObject, обеспечивая прозрачный доступ к источнику данных. BusinessObject передает также ответственность за выполнение операций загрузки и сохранения данных объекту DataAccessObject.
DataSource
Представляет реализацию источника данных. Источником данных может быть база данных, например, RDBMS, OODBMS, XML-репозиторий, система плоских файлов и др. Источником данных может быть также другая система (традиционная/мэйнфрейм), служба (B2B-служба или система обслуживания кредитных карт), или какой-либо репозиторий (LDAP).
TransferObject
Представляет собой Transfer Object, используемый для передачи данных. DataAccessObject может использовать TransferObject для возврата данных клиенту. DataAccessObject может также принимать данные от клиента в объекте Transfer Object для их обновления в источнике данных.
1.1.5. Стратегии
Стратегия Automatic DAO Code Generation
Поскольку BusinessObject соответствует конкретному DAO, есть возможность установить взаимоотношения между BusinessObject, DAO, и применяемыми реализациями (таблицы в RDBMS). После установления взаимоотношений появляется возможность написать простую утилиту для генерации кода, зависящую от приложения, которая может генерировать код для всех нужных приложению объектов DAO. Метаданные для генерации DAO могут определяться разработчиком в файле-дескрипторе. В качестве альтернативы генератор кода может автоматически проанализировать базу данных и предоставить необходимые для доступа к ней объекты DAO. Если требования к DAO являются достаточно сложными, можно использовать инструментальные средства сторонних производителей, обеспечивающие отображение «объектный-реляционный» для баз данных RDBMS. Такие средства обычно имеют GUI-интерфейс для отображения бизнес-объектов в объекты персистентного хранилища и определяют промежуточные объекты DAO. Инструментальные средства автоматически генерируют код после завершения отображения и могут предоставлять другие ценные функции, например, кэширование результатов, кэширование запросов, интеграция с серверами приложений, интеграция с другими сторонними продуктами (например, распределенное кэширование) и т.д.
Стратегия Factory for Data Access Objects
Паттерн DAO может быть сделан очень гибким при использовании паттернов Abstract Factory [GoF] и Factory Method [GoF].
Данная стратегия может быть реализована с использованием паттерна Factory Method для генерации нескольких объектов DAO, которые нужны приложению, в тех случаях, когда применяемое хранилище данных не изменяется при переходе от одной реализации к другой.
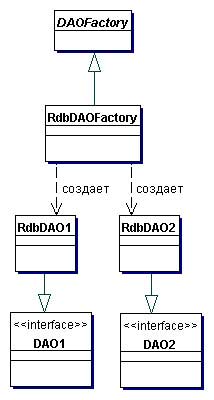
Когда используемое хранилище данных может измениться при переходе от одной реализации к другой, данная стратегия может быть реализована с применением паттерна Abstract Factory. Abstract Factory, в свою очередь, может создать и использовать реализацию Factory Method implementation, как рекомендуется в книге «Паттерны проектирования: Элементы повторно используемого объектно-ориентированного программного обеспечения» [GoF]. В этом случае данная стратегия предоставляет абстрактный объект генератора DAO (Abstract Factory), который может создавать конкретные генераторы DAO различного типа, причем каждый генератор может поддерживать различные типы реализаций персистентных хранилищ данных. После получения конкретного генератора для конкретной реализации вы можете использовать его для генерации объектов DAO, поддерживаемых и реализуемых в этой реализации.
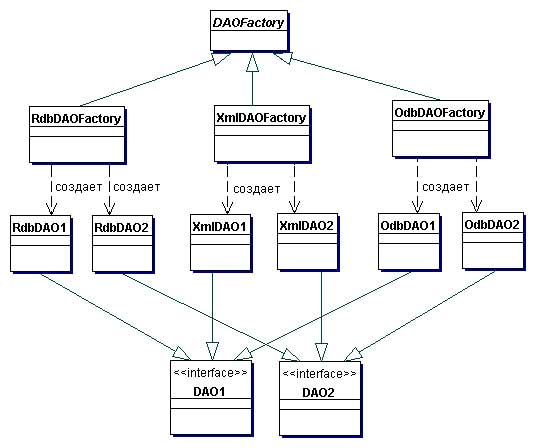
Диаграмма классов этой стратегии представлена на рисунке ниже. Эта диаграмма классов показывает базовый генератор DAO, являющийся абстрактным классом, который наследуется и реализуется различными конкретными генераторами DAO для поддержки доступа к специфической реализации хранилища данных. Клиент может получить реализацию конкретного генератора DAO, например RdbDAOFactory, и использовать его для получения конкретных объектов DAO, работающих с этой конкретной реализацией хранилища данных. Например, клиент может получить RdbDAOFactory и использовать его для получения конкретных DAO, таких, как RdbCustomerDAO, RdbAccountDAO и др. Объекты DAO могут расширять и реализовывать общий базовый класс (показанные как DAO1 и DAO2) и детально описывать требования к DAO для поддерживаемых бизнес-объектов. Каждый конкретный объект DAO отвечает за соединение с источником данных и за получение и управление данными для поддерживаемого им бизнес-объекта.
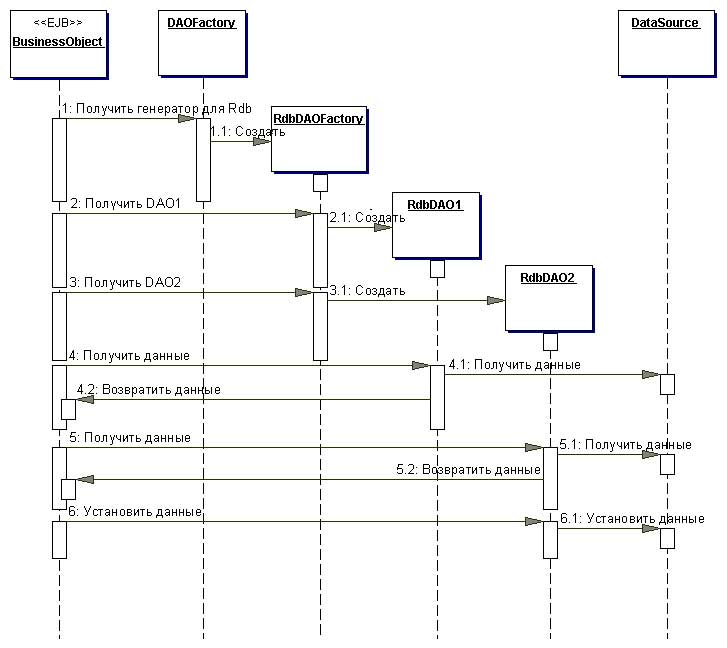
1.1.6. Выводы
-
Разрешает прозрачность
Бизнес-объекты могут использовать источник данных, не имея знаний о конкретных деталях его реализации. Доступ является прозрачным, поскольку детали реализации скрыты внутри DAO. -
Облегчает миграцию
Уровень объектов DAO облегчает приложению миграцию на другую реализацию базы данных. Бизнес-объекты не знают о деталях реализации используемых данных. Следовательно, процесс миграции требует изменений только в уровне DAO. Более того, при использовании стратегии генератора можно предоставить конкретную реализацию генератора для каждой реализации хранилища данных. В этом случае миграция на другую реализацию хранилища означает предоставление приложению новой реализации генератора. -
Уменьшает сложность кода в бизнес-объектах
Поскольку объекты DAO управляют всеми сложностями доступа к данным, упрощается код бизнес-компонентов и других клиентов данных, использующих DAO. Весь зависящий от реализации код (например, SQL-команды) содержится в DAO, а не в бизнес-объекте. Это улучшает читаемость кода и производительность разработки. -
Централизует весь доступ к данным в отдельном уровне
Поскольку все операции доступа к данным реализованы в объектах DAO, отдельный уровень доступа к данным может рассматриваться как уровень, изолирующий остальную часть приложения от реализации доступа к данным. Такая централизация облегчает поддержку и управление приложением. -
Бесполезна для управляемой контейнером персистенции
Поскольку EJB-контейнер управляет компонентами с управляемой контейнером персистенцией (CMP - container-managed persistence), контейнер автоматически обслуживает весь доступ к хранилищу данных. Приложения, использующие компоненты управления данными этого типа, не нуждаются в уровне объектов DAO, поскольку сервер приложений обеспечивает эту функциональность. Однако, объекты DAO остаются полезны в случаях, когда необходимо использовать комбинацию CMP (для компонентов управления данными) и BMP (для сессионных компонентов, Servlets). -
Добавляет дополнительный уровень
Объекты DAO создают дополнительный уровень объектов между клиентом данных и источником данных, который должен быть разработан и реализован для использования преимуществ, предлагаемых данным паттерном. Но за реализуемые при этом преимущества приходится платить дополнительными усилиями при разработке. -
Требуется разработка иерархии классов
При использовании стратегии генератора необходимо разработать и реализовать иерархию конкретных генераторов и иерархию конкретных объектов, производимых генераторами. Эти дополнительные усилия необходимо принимать во внимание, если существует достаточно оснований для реализации такой гибкости. Это увеличивает сложность разработки. Однако, вы можете сначала реализовать эту стратегию с паттерном Factory Method, а затем, при необходимости, перейти к паттерну Abstract Factory.
1.1.7. Примеры
Реализация паттерна Data Access Object
Код объекта DAO для персистентного объекта, предоставляющего информацию о клиенте (Customer), представлен в примере 4. CloudscapeCustomerDAO создает объект Customer Transfer Object при вызове метода findCustomer().
Код, использующий DAO, показан в примере 6.
Реализация стратегии Factory for Data Access Objects
Использование паттерна Factory Method
Рассмотрим пример, в котором мы применяем данную стратегию для создания генератором многих объектов DAO для одной реализации базы данных (например, Oracle). Генератор производит такие объекты DAO, как CustomerDAO, AccountDAO, OrderDAO и др.
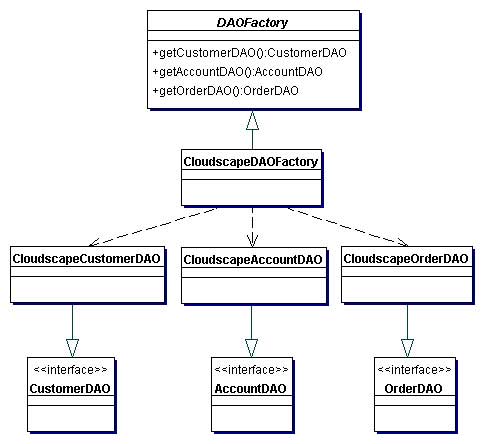
Код генератора DAO (CloudscapeDAOFactory) приведен в примере 2.
Использование паттерна Abstract Factory
Рассмотрим пример, в котором мы применяем данную стратегию для трех различных баз данных. В этом случае может быть использован паттерн Abstract Factory. Диаграмма классов этого примера показана на рисунке ниже. Код в примере 1 показывает фрагмент абстрактного класса DAOFactory. Этот генератор производит такие объекты DAO как CustomerDAO, AccountDAO, OrderDAO и др. Данная стратегия использует реализацию Factory Method в генераторах, созданных при помощи Abstract Factory.
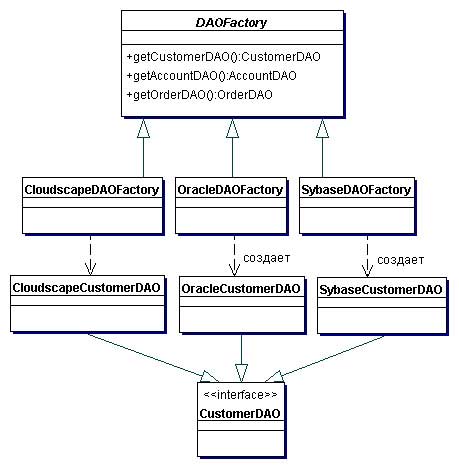
Пример 1: Абстрактный класс DAOFactory
// Абстрактный класс *DAO* Factory
public abstract class DAOFactory {
// Список типов DAO, поддерживаемых генератором
public static final int CLOUDSCAPE = 1;
public static final int ORACLE = 2;
public static final int SYBASE = 3;
// ...
// Здесь будет метод для каждого DAO, который может быть
// создан. Реализовывать эти методы
// должны конкретные генераторы.
public abstract CustomerDAO getCustomerDAO();
public abstract AccountDAO getAccountDAO();
public abstract OrderDAO getOrderDAO();
// ...
public static DAOFactory getDAOFactory(int whichFactory) {
switch (whichFactory) {
case CLOUDSCAPE:
return new CloudscapeDAOFactory();
case ORACLE:
return new OracleDAOFactory();
case SYBASE:
return new SybaseDAOFactory();
// ...
default:
return null;
}
}
}Код CloudscapeDAOFactory приведен в примере ниже. Реализации OracleDAOFactory и SybaseDAOFactory аналогичны, за исключением особенностей каждой реализации, таких как JDBC-драйвер, URL базы данных и различий в синтаксисе SQL, если таковые имеются.
Пример 2: Реализация DAOFactory для Cloudscape
// Конкретная реализация DAOFactory для Cloudscape
import java.sql.*;
public class CloudscapeDAOFactory extends DAOFactory {
public static final String DRIVER = "COM.cloudscape.core.RmiJdbcDriver";
public static final String DB_URL = "jdbc:cloudscape:rmi://localhost:1099/CoreJakartaEEDB";
// метод для создания соединений к Cloudscape
public static Connection createConnection() {
// Использовать DRIVER и DB_URL для создания соединения
// Рекомендовать реализацию/использование пула соединений
}
public CustomerDAO getCustomerDAO() {
// CloudscapeCustomerDAO реализует CustomerDAO
return new CloudscapeCustomerDAO();
}
public AccountDAO getAccountDAO() {
// CloudscapeAccountDAO реализует AccountDAO
return new CloudscapeAccountDAO();
}
public OrderDAO getOrderDAO() {
// CloudscapeOrderDAO реализует OrderDAO
return new CloudscapeOrderDAO();
}
// ...
}Интерфейс CustomerDAO, показанный в примере ниже, определяет DAO-методы для персистентного объекта Customer, которые реализованы всеми конкретными реализациями DAO, такими как, CloudscapeCustomerDAO, OracleCustomerDAO и SybaseCustomerDAO. Аналогично реализуются интерфейсы AccountDAO и OrderDAO, определяющие DAO-методы соответственно для бизнес-объектов Account и Order.
Пример 3: Базовый DAO-интерфейс для Customer
// Интерфейс, который должны поддерживать все CustomerDAO
public interface CustomerDAO {
int insertCustomer(/* ... */);
boolean deleteCustomer(/* ... */);
Customer findCustomer(/* ... */);
boolean updateCustomer(/* ... */);
RowSet selectCustomersRS(/* ... */);
Collection selectCustomersTO(/* ... */);
// ...
}CloudscapeCustomerDAO реализует CustomerDAO, как показано в примере ниже. Реализации других объектов DAO, таких, как CloudscapeAccountDAO, CloudscapeOrderDAO, OracleCustomerDAO, OracleAccountDAO, и т.д. - аналогичны.
Пример 4: Реализация CloudscapeDAO для Customer
// Реализация CloudscapeCustomerDAO
// интерфейса CustomerDAO. Этот класс может содержать весь
// специфичный для Cloudscape код и SQL-команды.
// Клиент, таким образом, защищается от необходимости
// знать эти детали реализации.
import java.sql.*;
public class CloudscapeCustomerDAO implements CustomerDAO {
public CloudscapeCustomerDAO() {
// инициализация
}
// Следующие методы по необходимости могут использовать
// CloudscapeDAOFactory.createConnection()
// для получения соединения
public int insertCustomer(/* ... */) {
// Реализовать здесь операцию добавления клиента.
// Возвратить номер созданного клиента
// или -1 при ошибке
}
public boolean deleteCustomer(/* ... */) {
// Реализовать здесь операцию удаления клиента.
// Возвратить true при успешном выполнении, false при ошибке
}
public Customer findCustomer(/* ... */) {
// Реализовать здесь операцию поиска клиента, используя
// предоставленные значения аргументов в качестве критерия поиска.
// Возвратить объект Transfer Object при успешном поиске,
// null или ошибку, если клиент не найден.
}
public boolean updateCustomer(/* ... */) {
// Реализовать здесь операцию обновления записи,
// используя данные из customerData Transfer Object
// Возвратить true при успешном выполнении, false при ошибке
}
public RowSet selectCustomersRS(/* ... */) {
// Реализовать здесь операцию выбора клиентов,
// используя предоставленный критерий.
// Возвратить RowSet.
}
public Collection selectCustomersTO(/* ... */) {
// Реализовать здесь операцию выбора клиентов,
// используя предоставленный критерий.
// В качестве альтернативы, реализовать возврат
// коллекции объектов Transfer Object.
}
// ...
}Класс Customer Transfer Object показан в примере 5. Он используется объектами DAO для передачи и приема данных от клиентов. Использование объектов Transfer Object детально рассматривалось в паттерне Transfer Object.
Пример 5: Customer Transfer Object
public class Customer implements java.io.Serializable {
// переменные-члены
private int CustomerNumber;
private String name;
private String streetAddress;
private String city;
// ...
// методы getter и setter...
// ...
}В примере 6 показано использование генератора DAO и DAO. Если реализация меняется от Cloudscape к другому продукту, необходимо изменить только вызов метода getDAOFactory() в генераторе DAO для получения другого генератора.
Пример 6: Использование DAO и DAO-генератора - код клиента
public class Application {
public static void main(String[] args) {
// ...
// создать требуемый генератор DAO
DAOFactory cloudscapeFactory =
DAOFactory.getDAOFactory(DAOFactory.DAOCLOUDSCAPE);
// Создать DAO
CustomerDAO customerDAO =
cloudscapeFactory.getCustomerDAO();
// создать нового клиента
int newCustomerNo = customerDAO.insertCustomer(/* ... */);
// найти объект customer. Получить объект Transfer Object.
Customer customer = customerDAO.findCustomer(/* ... */);
// изменить значения в Transfer Object.
customer.setAddress(/* ... */);
customer.setEmail(/* ... */);
// обновить объект customer, используя DAO
customerDAO.updateCustomer(customer);
// удалить объект customer
customerDAO.deleteCustomer(/* ... */);
// выбрать всех клиентов одного города
Customer criteria = new Customer();
criteria.setCity("New York");
Collection customersList =
customerDAO.selectCustomersTO(criteria);
// возвратить customersList - коллекцию объектов Customer
// Transfer Objects. Проходит по коллекции для
// получения значений.
// ...
}
}1.1.8. Связанные паттерны
-
Transfer Object
DAO использует Transfer Objects для передачи данных клиентам и от них. -
Factory Method [GoF] и Abstract Factory [GoF]
Стратегия Factory for Data Access Objects использует паттерн Factory Method для реализации конкретных генераторов и их продуктов (объектов DAO). Для дополнительной гибкости, в стратегиях может быть применен паттерн Abstract Factory, как рассматривалось выше. -
Broker [POSA1]
Паттерн DAO связан с паттерном Broker, который описывает подходы для разделения клиентов и серверов в распределенных системах. Паттерн DAO применяет этот паттерн более конкретно для разделения уровня ресурсов от клиентов и перемещения его в другой уровень, такой как бизнес-уровень, или уровень представлений.
2. Abbreviations
2.1. Common
-
ACID- Atomicity, Consistency, Isolation, Durability -
AOP- Aspect-Oriented Programming -
API- Application Programming Interface -
BIOS- Basic Input/Output System -
CHS- Cylinder Head Sector -
CIFS- Common Internet File System -
DAO- Data Access Object -
DD- DataDog -
DI- Dependency Injection -
DNS- Domain Name System -
DOM- Document Object Model -
DRY- Don’t Repeat Yourself -
DTD- Document Type Definition -
ESP-EFISystem Partition -
FTP- File Transfer Protocol -
FUSE- File System in User Scope -
GPG-GNUPrivacy Guard -
GPT- Globally UID Partition Table -
GRUB- GRand Unified Boot loader -
HTTP- HyperText Transfer Protocol -
IaaS- Infrastructure as a Service -
IoC- Inversion of Control -
IP- Internet Protocol -
LAN- Local area network -
LBA- Logical Block Addressing -
MBR- Master Boot Record -
MVC- Model–View–Controller -
NAT- Network Address Translation -
NTLM- NT Lan Manager -
ODBC- Open DataBase Connectivity -
ORM- Object-Relational Mapping -
OSI- Open Systems Interconnection model -
REST- REpresentational State Transfer -
SCSI- Small Computer System Interface -
SGML- Standard Generalized Markup Language -
SMB- Server Message Block -
SOA- Service-Oriented Architecture -
SOAP- Simple Object Access Protocol -
SPI- Service Provider Interface -
TSP- Transmission Control Protocol -
UDP- User Datagram Protocol -
UEFI- Unified Extensible Firmware Interface -
UID- Unique Identifier -
UUID- Universally Unique Identifier -
VFS- Virtual File System -
W3C- World Wide Web Consortium -
WLAN- Wireless LAN -
WSDL- Web Service Description Language -
XML- eXtensible Markup Language -
XPath- XML Path Language -
XSD- XML Schema Definition -
XSL- eXtensible Stylesheet Language -
XSLT- eXtensible Stylesheet Language Transformations
2.2. Amazon Web Services
-
AWS- Amazon Web Services -
EC2- Elastic Compute Cloud -
EBS- Elastic Block Store -
AMI- Amazon Machine Image -
IAM- Identity and Access Management -
VPC- Virtual Private Cloud -
SAN- Storage-Area Network -
EFS- Elastic File Store -
CIDR- Classes Inter-Domain Routing -
SQS- Simple Queue Service -
STS- Simple Token Service
2.3. Java
-
BPP- BeanPostProcessor -
EJB- Enterprise JavaBeans -
EL- Expression Language -
JAX-WS- Java API for XML Web Services -
JAXB- Java Architecture for XML Binding -
JDBC- Java DataBase Connectivity -
JDO- Java Data Objects -
JNDI- Java Naming and Directory Interface -
JPA- Java Persistence API -
JSF- JavaServer Faces -
JSP- JavaServer Pages -
JSTL- JSP Standard Tag Library -
JTA- Java Transaction API -
POJO- Plain Old Java Object -
RMI- Remote Method Invocation
3. Работа в терминале Linux
Прошли те времена, когда для управления операционной системой Linux требовалось знание командной строки. Сегодня в распоряжении пользователей Linux несколько отличных графических интерфейсов. Однако необязательное не означает бесполезное — знание команд открывает мощные возможности настройки и управления системой. Время, вложенное в изучение команд, окупится сторицей. Ниже несколько полезных команд. В Ubuntu Linux операции, требующие полномочий администратора, должны предваряться командой sudo
Переход в терминал: Alr+Ctr+F1(-F6)
Переключение между текстовыми консолями: Alr+F1(-F6)
Переход в графический режим: Alr+F7
Аварийный выход из системы X Window: Ctr+Alt+Backspace
3.1. Включение/выключение
Перезагрузить компьютер:
reboot
shutdown -r now
Выключить компьютер:
shutdown -h now
Выключить компьютер через заданное время:
shutdown -h hh:mm
shutdown -h +m
Окончание сеанса работы в терминале:
exit
3.2. Управление пользователями
Включить корневую учетную запись:
sudo passwd root
Заблокировать корневую учетную запись:
sudo passwd -l root
Добавить пользователя:
adduser имя_пользователя
Удалить пользователя:
deluser имя_пользователя
Удалить пользователя вместе с домашним каталогом:
deluser имя_пользователя -remove-home
Изменить имя пользователя и название его домашнего каталога:
usermod -l новое_имя_пользователя -d /home/новое_имя_пользователя -m старое_имя_пользователя
Изменить пароль пользователя:
passwd имя_пользователя
Восстановить пароль к учетной записи в режиме восстановления системы (нажать Esc в процессе загрузки GRUB):
passwd имя_записи
3.3. Управление каталогами
Показать информацию о файловых системах:
sudo mount
Показать список разделов:
df
Показать содержание текущего каталога:
du -h
Показать объем указанного каталога:
du -S имя_каталога
Отобразить путь к текущему каталогу:
pwd
Создать каталог:
mkdir имя_каталога
Скопировать каталог:
cp каталог_1 каталог_2
Переместить каталог_1 в каталог_2:
mv каталог_1 каталог_2
Войти в каталог:
cd /имя_каталога
Показать содержание каталога:
ls /имя_каталога
Показать содержание каталога, включая скрытые файлы и каталоги:
ls -a /имя_каталога
Показать полную информацию о содержании каталога:
ls -l /имя_каталога
Удалить пустой каталог:
rmdir имя_каталога
Удалить каталог с содержанием:
rm -r имя_каталога
3.4. Работа с файлами
Создать файл в текущем каталоге:
touch имя_файла.txt
Найти файл:
locate имя_файла
Обновить базу поиска файлов:
updatedb
Просмотреть текстовый файл:
cat /путь/имя_файла
Просмотреть текстовый файл в обратном порядке — от последней строки к первой:
tac /путь/имя_файла
Скопировать файл_1 в файл_2:
cp файл_1 файл_2
Переместить файл_1 в файл_2:
mv файл_1 файл_2
Переместить файл с сохранением оригинала (в конец имени файла дописывается символ ~):
mv -b файл целевой_каталог
Удалить файл:
rm имя_файла
Записать информацию в файл, перезаписав его:
echo текст > имя_файла.txt
Добавить информацию в файл без его перезаписи:
echo текст >> имя_файла.txt
Слить несколько текстовых файлов в один:
cat файл_1 файл_2 > итоговый_файл
3.5. Работа с архивами
Создать архив из содержимого каталога:
tar -cvf имя_архива.tar имя_каталога/
Сжать файлы:
bzip2 имя_файла
gzip имя_файла zip имя_файла
Распаковать архив:
gunzip имя_архива.tar.gz bunzip имя_архива.tar.bz bunzip2 имя_архива. ar.bz2 tar xvf имя_архива.tar tar xzf имя_архива.tgz
3.6. Управление правами доступа
Пример:
-r—r----- dr—r-----
Дефис вначале означает обычный файл, d — каталог (директорию). Дальше три группы по три символа означают права доступа для владельца, членов группы, в которую входит владелец, и для всех остальных пользователей соответственно. - - означает отсутствие прав, r — означает право на чтение, w — право на запись, x — право на выполнение.
Просмотреть права доступа:
ls -l имя_файла_или_каталога
Задать права доступа:
chmod имя_файла_или_каталога где
chmod группа=/+/-тип доступа имя_файла_или_каталога
где группа: u (user, владелец), g (group, группа), o (other, другие), a (all, все), например: chmod a+rw имя_файла
Изменить владельца:
chown имя_пользователя имя_файла
Распространенные права доступа:
644 = rw-r--r-- 666 = rw-rw-rw- 777 = rwxrwxrwx
Порядок цифр соответствует порядку пользователей (ugo), цифра в каждой позиции складывается из значений 4, 2 и 1 для прав r, w и x, соответственно. Так право полного доступа для владельца и отсуствие каких-либо прав для группы и прочих пользователей будет 700 (4+2+1.0.0).
3.7. Управление программами
Обновить список программного обеспечения:
apt-get update
Обновить систему:
apt-get upgrade
Найти программу в репозитарии по ключевому слову:
apt-cache search ключевое_слово
Показать информацию о пакете:
apt-cache show название_пакета
Установить программу из репозитария:
apt-get install имя_пакета
Удалить установленную программу:
apt-get remove имя_пакета
Удалить программу вместе с файлами настройки:
apt-get remove purge имя_пакета
Установить программу из скомпилированного пакета:
dpkg -i имя_пакета.deb
Удалить программу:
dpkg -r имя_пакета.deb
Очистить локальное хранилище полученных файлов пакетов:
apt-get clean
Просмотреть список установленных пакетов:
dpkg -l
Добавить частный источник программного обеспечения PPA (Personal Package Archive):
add-apt-repository ppa:user/ppa-name
Установить программу из бинарного файла (предварительно необходимо перейти в каталог с файлом программы):
./имя_файла.bin
Разрешить исполнение файла (если необходимо):
chmod a+x имя_файла.bin
Установить программу из исходных файлов (предварительно необходимо перейти в каталог с файлом программы):
./configure make make install
Удалить программу, установленную из исходных файлов:
make uninstall
Запустить графическую программу с правами root:
gksudo имя_программы
3.8. Управление системой
Отобразить список зарегистрированных в системе пользователей:
who
Показать информацию об использовании оперативной памяти:
free
Показать список запущенных процессов:
ps
Завершить процесс:
killall имя_процесса
Показать список процессов в реальном времени:
top
Внести изменения в файл конфигурации
gedit /путь/к_файлу
Снизить скорость чтения диска в приводе:
hdparm -E 4 /dev/dvdrom
3.9. Диагностика системы
Проверить жесткий диск на «битые» секторы:
badblocks
Показать состояние сетевых интерфейсов:
ifconfig
Показать состояние беспроводных сетевых устройств:
iwconfig
Проверить таблицу маршрутизации:
route
Проверить доступность компьютера в сети:
ping имя_сайта_или_ip_адрес
Остановить процесс: Ctrl+C
Проверить маршрут следования пакета:
traceroute имя_сайта_или_ip_адрес
Показать информацию о подключенных USB-устройствах:
lsusb
Отобразить список PCI-шин и подключенных к ним устройств:
lspci
Отобразить список оборудования системы:
lshw
3.10. Получение помощи
Показать Введение в пользовательские команды:
man intro
Отобразить краткое описание команды:
whatis имя_команды
Вывести информацию о команде:
man имя_команды info имя_команды имя_команды --help
Найти информацию по ключевым словам:
man -k ключевое_слово
Поиск по странице:
/ключевое_слово
Продолжить поиск:
N
Вывести историю команд:
history
Выполнить команду из списка истории команд:
!номер_команды !первые_буквы_команды
Очистить экран консоли:
clear
3.11. Объединение команд
Последовательное выполнение команд:
команда1 ; команда2
Последовательное выполнение команд при условии успешного выполнения предыдущей команды:
команда1 && команда2
Последовательное выполнение команд при условии неудачного выполнения предыдущей команды:
команда1 || команда2
Последовательное выполнение команд с передачей результатов выполнения предыдущей команды последующей:
команда1 | команда2
Запуск команды в фоновом режиме:
команда &
3.12. Символы подстановки
Текущий каталог: .
Родительский каталог: ..
Домашний каталог пользователя: ~
Один произвольный символ: ?
Любое количество произвольных символов: *
Символ из указанного диапазона: [a,b,x-z], например, [a,b].rar
Любые символы, кроме указанных: [!ab], например, [!ab].rar
Подстановка с помощью фигурных скобок: например, {a,b}{1,2} создаст строку a1 a2 b1 b2
Указание специального символа: \ или ', например, 'имя файла', или имя\ файла
4. Системы счисления
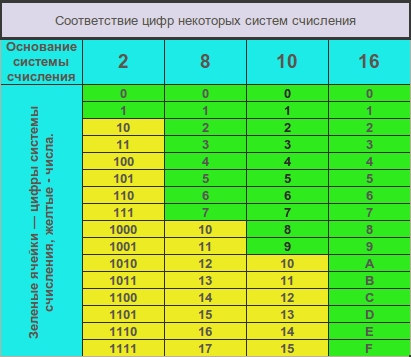
Чтобы избежать путаницы при одновременной работе с несколькими системами счисления основание указывается в качестве нижнего индекса.
4.1. Двоичная
Эта система, в основном, используется в вычислительной технике. Почему не стали использовать привычную нам 10-ю? Первую вычислительную машину создал Блез Паскаль, использовавший в ней десятичную систему, которая оказалась неудобной в современных электронных машинах, поскольку требовалось производство устройств, способных работать в 10 состояниях, что увеличивало их цену и итоговые размеры машины. Этих недостатков лишены элементы, работающие в 2-ой системе. Тем не менее, рассматриваемая система была создана за долго до изобретения вычислительных машин и уходит “корнями” в цивилизацию Инков, где использовались кипу — сложные верёвочные сплетения и узелки.
Отлично, но почему на экране мы видим десятичные числа и буквы? При нажатии на клавишу в компьютер передаётся определённая последовательность электрических импульсов, причём каждому символу соответствует своя последовательность электрических импульсов (нулей и единиц). Программа драйвер клавиатуры и экрана обращается к кодовой таблице символов (например, Unicode, позволяющая закодировать 65536 символов), определяет какому символу соответствует полученный код и отображает его на экране. Таким образом, тексты и числа хранятся в памяти компьютера в двоичном коде, а программным способом преобразуются в изображения на экране.
4.1.1. Основные принципы/понятия при работе с с двоичной системой
-
Двоичная позиционная система счисления имеет основание
2и использует для записи числа 2 символа (цифры):-
0 -
1
-
-
В каждом разряде допустима только одна цифра — либо
0, либо1. Примером может служить число1012. Оно аналогично числу5в десятичной системе счисления. -
Чтобы компьютер мог работать с двоичными числами (кодами), необходимо чтобы они где-то хранились.
-
Для хранения каждой отдельной цифры применяется триггер, представляющий собой электронную схему. Он может находится в 2-х состояниях, одно из которых соответствует
0, другое —1 -
Для хранения отдельного числа используется регистр — группа триггеров, число которых соответствует количеству разрядов в двоичном числе
-
Совокупность регистров — это оперативная память
-
Число, содержащееся в регистре — машинное слово.
-
Арифметические и логические операции со словами осуществляет арифметико-логическое устройство (
АЛУ). -
Для упрощения доступа к регистрам их нумеруют. Номер называется адресом регистра. Например, если необходимо сложить 2 числа — достаточно указать номера ячеек (регистров), в которых они находятся, а не сами числа.
-
Адреса записываются в 8- и 16-ричной системах, поскольку переход от них к двоичной системе и обратно осуществляется достаточно просто.
4.2. Восьмиричная
8-я система счисления, как и двоичная, часто применяется в цифровой технике. Имеет основание 8 и использует для записи числа цифры 0, 1, 2, 3, 4, 5, 6, 7.
4.3. Десятичная
Это одна из самых распространенных систем счисления. Именно её мы используем, когда называем цену товара и произносим номер автобуса. В каждом разряде (позиции) может использоваться только одна цифра из диапазона от 0, до 9. Основанием системы является число 10.
Для примера возьмем число 50310.
Если бы это число было записано в непозиционной системе, то его значение равнялось 5 + 0 + 3 = 8. Но у нас — позиционная система и значит каждую цифру числа необходимо умножить на основание системы, в данном случае число 10, возведенное в степень, равную номеру разряда. Получается, значение равно 5 * 102 + 0 * 101 + 3 * 100 = 500 + 0 + 3 = 503.
Таким образом, 503 = 50310.
4.4. Шестнадцатеричная
Шестнадцатеричная система широко используется в современных компьютерах, например при помощи неё указывается цвет: =FFFFFF — белый цвет. Рассматриваемая система имеет основание 16 и использует для записи числа: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, где буквы равны 10, 11, 12, 13, 14, 15 соответственно.
В качестве примера возьмем число 4F51616.
4.5. Перевод из одной системы в другую
Иногда требуется преобразовать число из одной системы счисления в другую, поэтому рассмотрим способы перевода между различными системами.
4.5.1. Из любой в десятичную
Целая часть
Имеется число a1a2a3 в системе счисления с основанием b. Для перевода в 10-ю систему необходимо каждый разряд числа умножить на bn, где n — номер разряда. Таким образом, (a1a2a3)b = (a1 * b2 + a2 * b1 + a3 * b0)10.
Пример:
1012 = 1 * 22 + 0 * 21 + 1 * 20 = 4 + 0 + 1 = 510
Дробная часть
Преобразование осуществляется также, как и для целых частей, за исключением того, что цифры числа умножаются на основание в степени -n, где n начинается от 1.
Пример:
101,0112 = (1 * 22 + 0 * 21 + 1 * 20), (0 * 2-1 + 1 * 2-2 + 1 * 2-3) = (5), (0 + 0,25 + 0,125) = 5,37510
4.5.2. Из десятичной в любую
Целая часть
-
Последовательно делим целую часть десятичного числа на основание системы, в которую переводим, пока десятичное число не станет равно нулю.
-
Полученные при делении остатки являются цифрами искомого числа.
-
Число в новой системе записывают, начиная с последнего остатка.
Дробная часть
-
Дробную часть десятичного числа умножаем на основание системы, в которую требуется перевести.
-
Отделяем целую часть.
-
Продолжаем умножать дробную часть на основание новой системы, пока она не станет равной 0.
-
Число в новой системе составляют целые части результатов умножения в порядке, соответствующем их получению.
Пример: переведем 1510 в восьмеричную:
15 \ 8 = 1, остаток 7
1 \ 8 = 0, остаток 1
Записав все остатки снизу вверх, получаем итоговое число 17. Следовательно, 1510 = 178.
4.5.3. Из двоичной в восьмиричную
Целая часть
Для перевода в восьмеричную — разбиваем двоичное число на группы по 3 цифры справа налево,а недостающие крайние разряды заполняем ведущими нулями. Далее преобразуем каждую группу, умножая последовательно разряды на 2n, где n — номер разряда.
В качестве примера возьмем число 10012:
10012 = 001 001 = (0 * 22 + 0 * 21 + 1 * 20) (0 * 22 + 0 * 21 + 1 * 20) = (0 + 0 + 1) (0 + 0 + 1) = 118
Дробная часть
Перевод дробной части осуществляется также, как и для целых частей числа, за тем лишь исключением, что разбивка на группы по 3 цифры идёт вправо от десятичной запятой, недостающие разряды дополняются нулями справа.
Пример:
1001,012 = 001 001, 010 = (0 * 22 + 0 * 21 + 1 * 20) (0 * 22 + 0 * 21 + 1 * 20), (0 * 22 + 1 * 21 + 0 * 20) = (0 + 0 + 1) (0 + 0 + 1), (0 + 2 + 0) = 11,28
4.5.4. Из двоичной в шестнадцатиричную
Целая часть
Для перевода в шестнадцатеричную — разбиваем двоичное число на группы по 4 цифры справа налево, затем — аналогично преобразованию из 2-й в 8-ю.
Дробная часть
Перевод дробной части осуществляется также, как и для целых частей числа, за тем лишь исключением, что разбивка на группы по 4 цифры идёт вправо от десятичной запятой, недостающие разряды дополняются нулями справа.
4.5.5. Из восьмиричной в двоичную
Целая и дробная часть
Перевод из восьмеричной в двоичную — преобразуем каждый разряд восьмеричного числа в двоичное 3-х разрядное число делением на 2, недостающие крайние разряды заполним ведущими нулями.
Для примера рассмотрим число 458:
458 = (100) (101) = 1001012
4.5.6. Из шестнадцатиричной в двоичную
Целая и дробная часть
Перевод из 16-ой в 2-ю — преобразуем каждый разряд шестнадцатеричного числа в двоичное 4-х разрядное число делением на 2, недостающие крайние разряды заполняем ведущими нулями.
5. GitHub keys
5.1. SSH key
С помощью протокола SSH можно подключаться и проходить проверку подлинности на удаленных серверах и службах. С помощью ключей SSH вы можете подключаться к GitHub без предоставления своего имени пользователя и личного маркера доступа при каждом посещении.
Для того чтобы использовать подключение с помощью протокола SSH необходимо сгенерировать SSH-KEY. В данном примере генерация происходит через GIT GUI.
Для генерации заходим Git GUI Here.
В появившемся окне выбираем вкладку Help - Show SSH Key
Если, ключ не обнаружен, то производим генерацию ключа Generate Key
После того как ключ был сгенерирован или уже имелся, его нужно скопировать для установки в профиле. Для этого в настройки вашего профиля (setting).
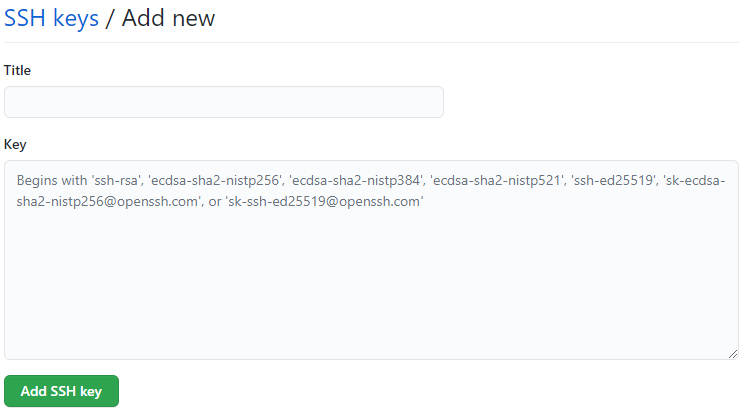
Далее ищем вкладку SSH and GPG keys
Нажимаем New SSH key
Вставляем имеющийся ключ и добавляем Add SSH key
5.2. GPG key
С помощью GPG или S/MIME можно подписывать теги и коммиты. Эти теги или коммиты помечаются как проверенные на GitHub, чтобы другие люди могли быть уверены, что изменения происходят из надежного источника.
Сначала необходимо скачать и становить Gpg4win
Затем заходим в Git Bush и вводим команду:
gpg --full-generate-key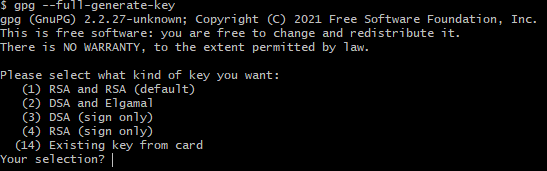
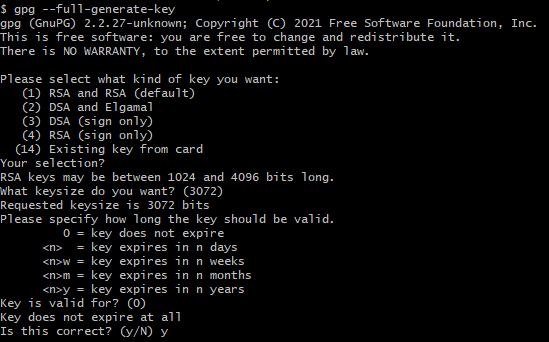
Затем выбирая нужные настройки нажимаем Enter до тех пор, пока не попросит подтвердить корректность данных и если все верно подтверждаем набрав Y
Далее вводим свои данные: имя, email.
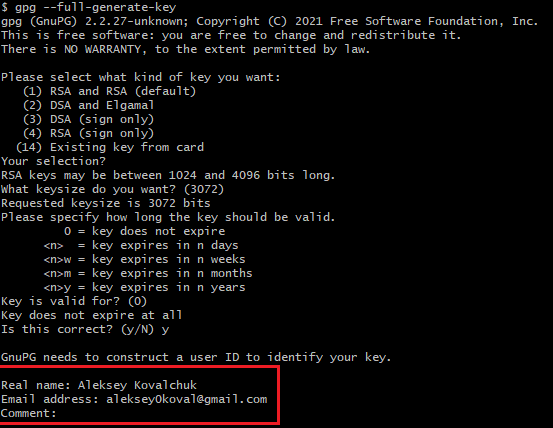
Если все верно - подтверждаем введенные данные набрав`О`.

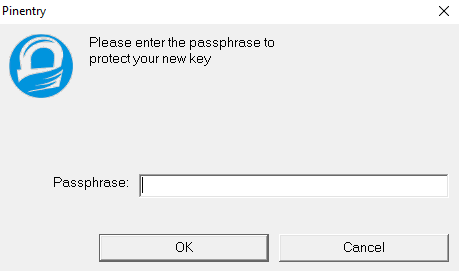
Вводим пароль(секретное поле) и затем его подтверждаем
После этого наши GPG ключи сгенерированы.
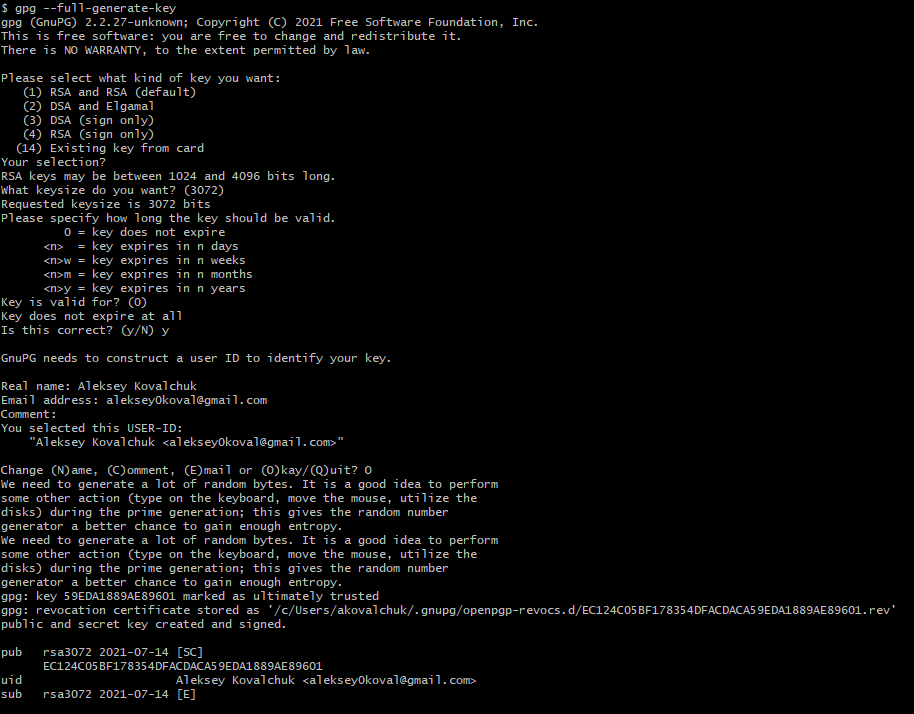
Чтобы посмотреть открытый и закрытый ключи необходимо ввести следующую команду:
gpg --list-secret-keys --keyid-format=long
/Users/hubot/.gnupg/secring.gpg
------------------------------------
sec 4096R/3AA5C34371567BD2 2016-03-10 [expires: 2017-03-10]
uid Hubot
ssb 4096R/42B317FD4BA89E7A 2016-03-10Далее введя команду gpg --armor --export …, и подставив место … свое значение получим
gpg --armor --export 3AA5C34371567BD2
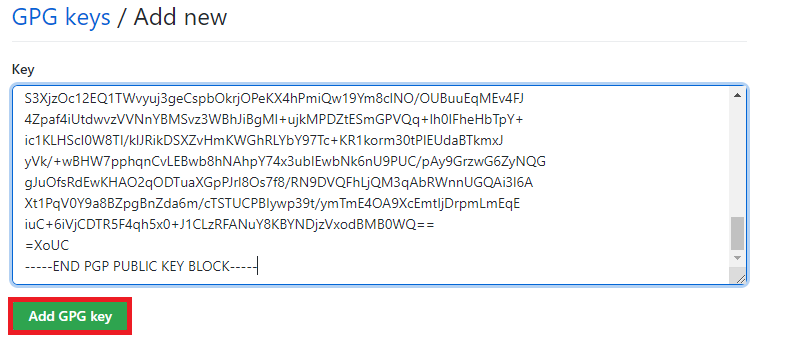
После этого выделяем и копируем от -----BEGIN PGP PUBLIC KEY BLOCK----- до -----END PGP PUBLIC KEY BLOCK-----
Далее, как и при добавлении SSH ключей заходим в свой профиль - setting - SSH and GPG keys и выбираем уже New GPG key
И в появившемся окне вставляем скопированный ключ и добавляем его.
6. LDAP
6.1. Abbreviations
Термин |
Определение |
Перевод и пояснения |
CN |
Common Name |
Общепринятое имя (термин служб каталогов) |
DC |
Domain Component |
Доменный компонент (термин служб каталогов) |
DIT |
Directory Information Tree |
Информационное дерево каталога (термин служб каталогов) |
DNS |
Domain Name System |
Система доменных имён |
DN |
Distinguished Name |
Уникальное имя (термин служб каталогов) |
Kerberos |
Kerberos Authentication Service |
Служба аутентификации Kerberos |
LDAP |
Lightweight Directory Access Protocol |
Облегчённый протокол доступа к службам каталогов |
UID |
User Identifier |
Идентификатор пользователя (термин служб каталогов) |
6.2. Что такое LDAP?
LDAP - это аббревиатура от Lightweight Directory Access Protocol. Как следует из названия, это облегчённый протокол доступа к службам каталогов, предназначенный для доступа к службам каталогов на основе X.500.
6.2.1. Какого рода информация может храниться в каталоге?
Информационная модель LDAP основана на записях (entry). Запись - это коллекция атрибутов (attribute), обладающая уникальным именем (Distinguished Name, DN). DN глобально-уникально для всего каталога и служит для однозначного указания на запись. Каждый атрибут записи имеет свой тип (type) и одно или несколько значений (value). Обычно типы - это мнемонические строки, в которых отражено назначение атрибута, например cn - для общепринятого имени (common name), или mail - для адреса электронной почты. Синтаксис значений зависит от типа атрибута. Например, атрибут cn может содержать значение Babs Jensen. Атрибут mail может содержать значение babs@example.com. Атрибут jpegPhoto будет содержать фотографию в бинарном формате JPEG.
6.2.2. Как организовано размещение информации?
Записи каталога LDAP выстраиваются в виде иерархической древовидной структуры. Традиционно, эта структура отражает географическое и/или организационное устройство хранимых данных. В вершине дерева располагаются записи, представляющие собой страны. Под ними располагаются записи, представляющие области стран и организации. Еще ниже располагаются записи, отражающие подразделения организаций, людей, принтеры, документы, или просто всё то, что Вы захотите включить в каталог.
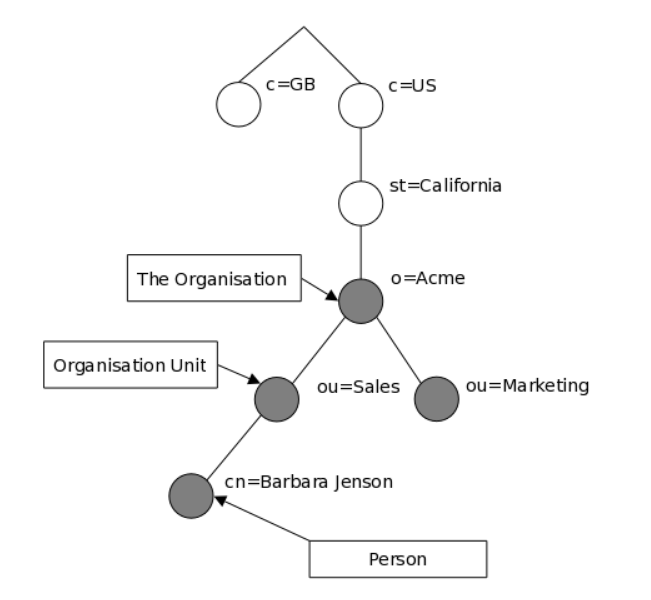
Построение дерева может быть также основано на доменных именах Internet. Этот подход к именованию записей становится всё более популярным, поскольку позволяет обращаться к службам каталогов по аналогии с доменами DNS.
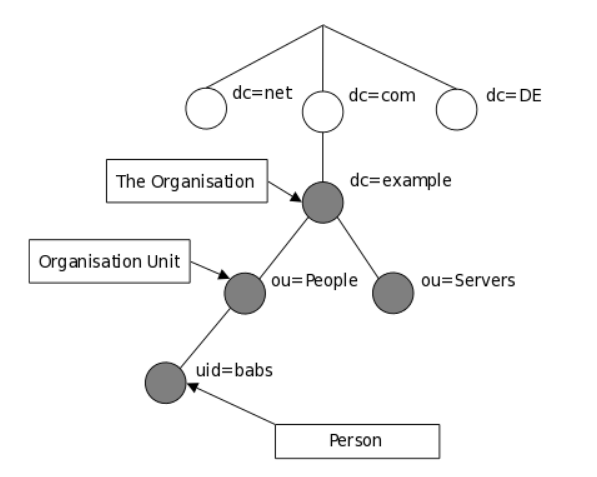
6.2.3. Как можно обратиться к информации?
К записи обращаются по ее уникальному имени, которое состоит из собственно имени записи (так называемое относительное уникальное имя (Relative Distinguished Name, RDN) с прибавлением к нему имён записей-предков. Так, запись, описывающая Barbara Jensen, имеет RDN uid=babs, и DN - uid=babs,ou=People,dc=example,dc=com. Полное описание формата DN можно найти RFC4514.
-
Какие манипуляции можно произвести с информацией? В LDAP определены операции для опроса и обновления каталога. К числу последних относятся операции добавления и удаления записи из каталога, изменения существующей записи и изменения названия записи. Однако, большую часть времени LDAP используется для поиска информации в каталоге. Операции поиска LDAP позволяют производить поиск записей в определённой части каталога по различным критериям, заданным поисковыми фильтрами. У каждой записи, найденной в соответствии с критериями, может быть запрошена информация, содержащаяся в её атрибутах. К примеру, Вам захотелось найти записи о человеке по имени
Barbara Jensenво всем подкаталоге, начиная с уровняdc=example,dc=comи ниже, и получить адрес электронной почты в каждой найденной записи. LDAP позволяет Вам легко это сделать. Или Вам хочется поискать непосредственно на уровнеst=California,c=USзаписи организаций, названия которых содержат строкуAcmeи имеющих номер факса. Такой поиск LDAP тоже позволяет сделать. -
Как информация защищена от несанкционированного доступа?
Некоторые службы каталогов не предоставляют никакой защиты, позволяя любому просматривать хранящуюся в них информацию. Однако LDAP предоставляет механизмы для аутентификации клиента, либо других способов доказательства его подлинности серверу каталогов, а также богатые возможности контроля доступа к информации, содержащейся на этом сервере. LDAP также обеспечивает защиту информации в каталоге (её целостность и конфиденциальность).
6.3. Для чего можно использовать LDAP?
В общем случае, службу каталогов можно использовать, когда Вам требуется надёжное хранение информации с возможностью централизованного управления и доступа к ней, с использованием стандартизированных методов.
Вот ряд (но, конечно, не полный) самых распространённых примеров промышленного использования служб каталогов:
-
Идентификация компьютеров
-
Аутентификация пользователей
-
Группировка пользователей (в том числе системные группы)
-
Адресные книги
-
Представление штатно-кадровой структуры организации
-
Учет закрепления имущества организации за сотрудниками
-
Телефонные справочники
-
Управление пользовательскими ресурсами
-
Справочники адресов электронной почты
-
Хранение конфигурации приложений
-
и т.д. …
Для организации каталога под столь разные задачи существуют различные, основанные на стандартах файлы наборов схемы, распространяемые с дистрибутивом. Также Вы можете создать свою собственную спецификацию схемы для решения Вашей задачи.
Всегда найдутся новые способы использования каталогов и применения принципов LDAP для решения различных проблем, поэтому не существует простого ответа на вопрос этого подраздела.
6.3.1. Как работает LDAP?
LDAP использует клиент-серверную модель. Один или несколько серверов LDAP содержат информацию, образующую информационное дерево каталога (directory information tree, DIT). Клиент подключается к серверу и делает запрос. В ответ сервер отправляет результаты обработки запроса и/или указатель на то, где клиент может получить дополнительные сведения (обычно, на другой сервер LDAP). Независимо от того, к какому серверу LDAP подключается клиент, он увидит одинаковое представление каталога; на записи, расположенные на одном сервере LDAP, будут указывать правильные ссылки при обращении к другому серверу LDAP, и наоборот. Это важная особенность глобальной службы каталогов.
7. Security
Аутентификация
Авторизация
8. Тестирование
Тестирование (testing) программного обеспечения (ПО) – это процесс исследования ПО с целью выявления ошибок и определения соответствия между реальным и ожидаемым поведением ПО, осуществляемый на основе набора тестов, выбранных определённым образом. В более широком смысле, тестирование ПО – это техника контроля качества программного продукта, включающая в себя проектирование тестов, выполнение тестирования и анализ полученных результатов.
Очень часто современные программные продукты разрабатываются в сжатые сроки и при ограниченных бюджетах проектов. Программирование сегодня перешло из разряда искусства в разряд ремесел для многих миллионов специалистов. Но, к сожалению, в такой спешке разработчики зачастую игнорируют необходимость обеспечения защищённости своих продуктов, подвергая тем самым пользователей неоправданному риску. Контроль качества (тестирование) считается важным в процессе разработки ПО, потому что обеспечивает безопасность, надёжность, удобство создаваемого продукта. В настоящее время существует великое множество подходов и методик к решению задачи тестирования ПО, но эффективное тестирование сложных программных систем — процесс творческий, не сводящийся к следованию строгим и чётким правилам.
8.1. Классификация видов тестирования
Существует несколько признаков, по которым принято производить классификацию видов тестирования. Все виды тестирования программного обеспечения можно условно классифицировать по следующему виду:
-
По степени автоматизации
-
По уровню доступа
-
В зависимости от преследуемых целей
8.1.1. По степени автоматизации
-
Ручное тестирование;
-
Автоматизированное тестирование.
Ручное тестирование (manual testing) – тестирование при котором не используются программные средства для выполнения тестов и проверки результатов выполнения.
Автоматизированное тестирование (automated testing) – тестирование, при котором используются программные средства для выполнения тестов и проверки результатов выполнения. Автоматизированное тестирование, несомненно, приносит пользу и экономит время и ресурсы компании.
В процессе разработки часто бывает так, что новая версия с исправленными ошибками выпускается каждый день, а иногда, и несколько раз в день. Smoke testing прежде всего должно быть автоматизировано, потому что сразу после сборки новой версии программы нам необходимо в кратчайшие сроки убедиться в том, что программа запускается. Автоматический тест справится с подобной задачей за считанные секунды, и сборку можно будет считать успешной. Если же этим будет заниматься человек, то времени на проверку будет уходить гораздо больше. Таким образом, автоматизация smoke testing – это неплохая экономия времени отдела тестирования.
Для автоматизации тестирования существует большое количество приложений. Наиболее популярные из них:
-
Selenium
-
TestComplete
Автоматизация в целом не только экономит время на разработку, но и увеличивает надежность и безопасность создаваемых продуктов. Очевидны также преимущества для тестировщиков:
-
надёжность проверки продукта возрастает
-
время на тестирование сокращается
-
работа тестирующего становится менее стрессовой
Конечно, автоматические тесты никогда не смогут заменить человека, но могут облегчить работу инженера-тестировщика ПО.
8.1.2. По уровню доступа
-
Тестирование чёрного ящика;
-
Тестирование белого ящика.
Тестирование чёрного ящика
Тестирование чёрного ящика (black box) - тестирование ПО, при котором тестировщик имеет доступ к ПО только через интерфейсы заказчика, либо через внешние интерфейсы, позволяющие другому компьютеру или процессу подключиться к системе для тестирования. Этот подход до сих пор является самым распространенным в повседневной практике, но у него есть целый ряд недостатков. Например, некоторые ошибки возникают достаточно редко и потому их трудно найти и воспроизвести.
Тестирование белого ящика
Тестирование белого ящика (white box) - тестирование ПО, при котором тестировщик имеет доступ к исходному коду программы и может писать код, связанный с библиотеками тестируемого ПО. К тестированию белого ящика относят методики:
-
чтение программ
-
формальный просмотр программ
-
инспекция
Этот метод позволяет заглянуть внутрь "чёрного ящика" и сосредоточиться на внутренней информации, которая и определяет поведение программы. Основной трудностью является сложность отслеживания вычислений времени выполнения. При тестировании программы происходит проверка логики программы. Полным тестированием в этом случае будет такое, которое приведет к перебору всех возможных путей. Даже для средних по сложности программ число таких путей может достигать десятки тысяч.
8.1.3. В зависимости от преследуемых целей
Все виды тестирования программного обеспечения, в зависимости от преследуемых целей, можно условно разделить на следующие группы:
-
Функциональные
-
Нефункциональные
Функциональные виды тестирования
Функциональные тесты базируются на функциях и особенностях, а также взаимодействии с другими системами, и могут быть представлены на всех уровнях тестирования:
-
компонентном или модульном (Component/Unit testing)
-
интеграционном (Integration testing),
-
системном (System testing)
-
приемочном (Acceptance testing).
Функциональные виды тестирования рассматривают внешнее поведение системы. После проведения необходимых изменений, таких как исправление бага/дефекта, программное обеспечение должно быть протестировано повторно для подтверждения того факта, что проблема была действительно решена. Ниже перечислены виды функционального тестирования, которые необходимо проводить после установки программного обеспечения, для подтверждения работоспособности приложения или правильности осуществленного исправления дефекта:
-
Функциональное тестирование (Functional testing)
-
Тестирование взаимодействия (Interoperability Testing)
-
Дымовое тестирование (Smoke Testing)
-
Регрессионное тестирование (Regression Testing)
-
Тестирование сборки (Build Verification Test)
-
Санитарное тестирование или проверка согласованности/исправности (Sanity Testing)
-
Альфа-тестирование
-
Бета-тестирование
Функциональное тестирование (functional testing) – тестирование ПО, направленное на проверку реализуемости функциональных требований. При функциональном тестировании проверяется способность ПО правильно решать задачи, необходимые пользователям.
Альфа-тестирование – это процесс имитации реальной работы разработчиков с программным продуктом, или реальная работа потенциальных пользователей с системой.
Бета-тестирование – это распространение версий с ограничениями для некоторой группы лиц, с целью проверки содержания допустимо минимального количества ошибок в программном продукте.
Регрессионное тестирование (regression testing) – тестирование ПО, при котором проводится проверка ранее найденных ошибок, а также проверка основной функциональности.
Проводится, как правило, на каждой новой версии программного продукта. Регрессивное тестирование является наиболее важной фазой тестирования непосредственно перед окончанием работ над продуктом, так как непосредственно перед релизом продукта крайне необходимо проверить не только основную функциональность, но и то, что ни одна из ранее найденных ошибок не повторяется в финальной версии. Являясь неотъемлемой частью функционального тестирования, регрессионное тестирование позволяет гарантировать, что изменения, связанные с устранением дефектов, не оказали негативного воздействия на остальные функциональные области приложения.
Дымовое тестирование (smoke testing) - тестирование ПО, при котором выполняется набор тестов, после чего можно сказать, что программный продукт запускается.
Если ошибок при запуске не происходит, то дымовой тест считается пройденным. Если программа не прошла дымовой тест, то её отправляют на доработку. Дело в том, что разработчики пишут отдельные компоненты одного приложения, но когда эти компоненты объединяют, нередко получается так, что совместно они работать не могут, следовательно, нет смысла тестировать продукт в целом.
Нефункциональные виды тестирования
Нефункциональное тестирование описывает тесты, необходимые для определения характеристик программного обеспечения, которые могут быть измерены различными величинами. В целом, это тестирование того, "Как система работает". Далее перечислены основные виды нефункциональных тестов:
-
Тестирование производительности
-
нагрузочное тестирование (Performance and Load Testing)
-
стрессовое тестирование (Stress Testing)
-
тестирование стабильности или надежности (Stability/Reliability Testing)
-
объемное тестирование (Volume Testing)
-
-
Тестирование установки (Installation testing)
-
Тестирование удобства пользования (Usability Testing)
-
Тестирование на отказ и восстановление (Failover and Recovery Testing)
-
Конфигурационное тестирование (Configuration Testing)
-
Тестирование безопасности (Security and Access Control Testing)
Тестирование производительности (performance testing) – тестирование ПО, позволяющее осуществлять оценку быстродействия программного продукта при определённой нагрузке. Тест производительности выполняется до и после проведения оптимизации с целью выявить изменения в производительности. Если оптимизация не удается, и производительность снижается, то программист может отказаться от неудачной оптимизации. В случае повышения производительности величину этого повышения можно сравнить с ожидаемыми результатами, чтобы убедиться в успешности оптимизации. Задачей теста производительности является выявление фактов повышения и понижения производительности, чтобы можно было избежать неудачных модернизаций.
Нагрузочное тестирование (load testing) – тестирование ПО, позволяющее осуществлять оценку быстродействия программного продукта при плановых, повышенных и пиковых нагрузках. Осуществление нагрузочного тестирования перед вводом системы в промышленную эксплуатацию позволяет избегать неожиданных потерь в производительности через полгода - год, когда система будет заполнена данными.
Стресс-тестирование (stress testing) – тестирование ПО, которое оценивает надёжность и устойчивость системы в условиях превышения пределов нормального функционирования. Это проверка программы в таких стрессовых ситуациях как наличие большого объёма входных параметров, нехватка дискового пространства или маломощный процессор. Стресс тестирование предназначено для проверки настроенного решения и серверной группы на одновременное обслуживание большого количества пользователей. При таком тестировании проверяется не только серверная группа, но и влияние, оказываемое настройками на производительность системы в целом и ее отказоустойчивость. Для проведения такого тестирования необходимо иметь набор компьютеров, эмулирующих работу групп пользователей.
Тестирование стабильности (stability/endurance/soak testing) – тестирование ПО, при котором проверяется работоспособность ПО при длительном тестировании со среднем уровнем нагрузки.
Тестирование безопасности (security testing) – тестирование ПО, которое проверяет фактическую реакцию защитных механизмов, встроенных в систему на проникновение злоумышленников.
Тестирование совместимости (compatibility testing) - тестирование ПО, которое проверяет работоспособность ПО в определенном окружении.
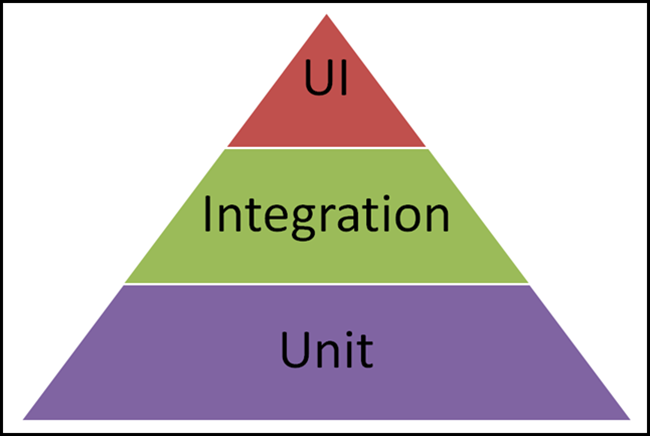
8.2. Уровни тестирования
-
Модульное тестирование;
-
Интеграционное тестирование;
-
Системное тестирование;
-
Приемочное тестирование.
8.2.1. Пирамида тестирования
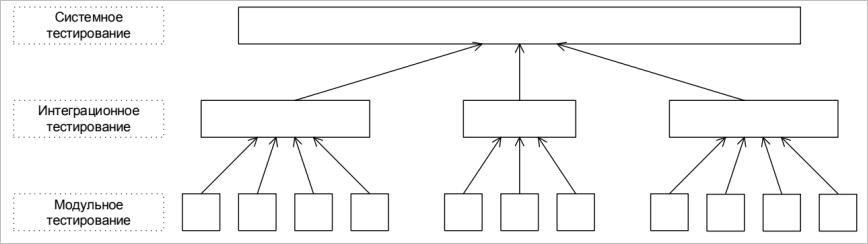
8.2.2. Модульное тестирование
Модульное тестирование – это процесс исследования ПО, при котором тестируется минимально возможный компонент, например, отдельный класс или функция. Часто модульное тестирование осуществляется разработчиками ПО.
8.2.3. Интеграционное тестирование
Интеграционное тестирование – это процесс исследования ПО, при котором тестируется интерфейсы между компонентами или подсистемами.
8.2.4. Системное тестирование
Системное тестирование – это процесс исследования ПО, при котором тестируется интегрированная система на её соответствие требованиям заказчика. Альфа и Бета тестирование относятся к подкатегориям системного тестирования.
8.2.5. Приемочное тестирование (Acceptance Testing)
Приемочное тестирование - формальный процесс тестирования, который проверяет соответствие системы требованиям и проводится с целью:
-
определения удовлетворяет ли система приемочным критериям;
-
вынесения решения заказчиком или другим уполномоченным лицом принимается приложение или нет.
Приемочное тестирование выполняется на основании набора типичных тестовых случаев и сценариев, разработанных на основании требований к данному приложению. Решение о проведении приемочного тестирования принимается, когда:
-
продукт достиг необходимого уровня качества;
-
заказчик ознакомлен с Планом Приемочных Работ (Product Acceptance Plan) или иным документом, где описан набор действий, связанных с проведением приемочного тестирования, дата проведения, ответственные и т.д.
Фаза приемочного тестирования длится до тех пор, пока заказчик не выносит решение об отправлении приложения на доработку или выдаче приложения.
8.3. Динамический и статический анализ кода
По мере продвижения проекта стоимость устранения дефектов ПО может экспоненциально возрастать. Инструменты статического и динамического анализа помогают предотвратить эти затраты благодаря обнаружению программных ошибок на ранних этапах жизненного цикла ПО.
Динамический анализ кода (runtime analysis) – способ анализа программы непосредственно при ее выполнении. При динамическом анализе проблемы в исходном коде находятся по мере их возникновения. Процесс анализа можно разбить на несколько этапов:
-
подготовка исходных данных
-
проведение тестового запуска программы
-
сбор необходимых параметров
-
анализ полученных данных
Статический анализ кода (static analysis) - анализ программы, производимый без реального выполнения исследуемых программ. Статический анализ кода позволяет обнаружить дефекты в исходном коде до того, как код будет готов для запуска.
На практике разработчики могут использовать как статический, так и динамический анализ для ускорения процессов разработки и тестирования, а также для повышения качества исходного продукта.
9. Asciidoc
9.1. Что такое AsciiDoc?
AsciiDoc — легковесный язык разметки и система для его визуализации. Используется для написания документации, статей, книг, слайдов, веб-сайтов, блогов и подобных вещей.
С более детальной информацией можно ознакомиться на:
-
Website: http://asciidoc.org/
-
GitHub: https://github.com/asciidoc
9.2. Краткое руководство
9.2.1. Заголовки
| AsciiDoc | Result |
|---|---|
// = Уровень 1 `Уровень 1` может быть использован только ОДИН раз, как название для документа/книги/темы, поэтому он закомментирован и не будет отображен. == Уровень 2 Текст. === Уровень 3 Текст. ==== Уровень 4 Текст. ===== Уровень 5 Текст. |
9.3. Уровень 2Текст. 9.3.1. Уровень 3Текст. Уровень 4Текст. Уровень 5Текст. |
9.3.2. Абзацы
| AsciiDoc | Result | ||||||||
|---|---|---|---|---|---|---|---|---|---|
.Необязательное заглавие Обычный абзац. Второй абзац. |
Необязательное заглавие
Обычный абзац. Второй абзац. | ||||||||
.Необязательное заглавие Дословный абзац. Должен иметь отступ. |
Необязательное заглавие
Дословный абзац. Должен иметь отступ. | ||||||||
.Необязательное заглавие [source, sh] ps -aux Не являеется кодом следующий абзац. |
Необязательное заглавие
Не являеется кодом следующий абзац. | ||||||||
.Необязательное заглавие NOTE: Это пример абзаца с примечанием. |
| ||||||||
.Необязательное заглавие [NOTE] Это пример абзаца с примечанием. |
| ||||||||
TIP: Какой-то текст с советом. IMPORTANT: Какой-то важный текст. WARNING: Какой-то предупреждающий текст. CAUTION: Какой-то текст с предупреждением (более слабым чем WARNING). |
|
9.3.3. Блоки
.Необязательное заглавие ---- *Листинговый* блок Используется для листинг (кода или файла) ---- |
Необязательное заглавие
*Листинговый* блок Используется для листинг (кода или файла) | ||
.Необязательное заглавие
[source, java]
----
// Блок с *исходным кодом*
// Используется для выделения команд для конкретного языка
public class HellToWorld {
public static void main(String[] args) {
System.out.println("Hell to World!");
}
}
----
|
Необязательное заглавие
| ||
.Необязательное заглавие [NOTE] ==== Блок с *ПРИМЕЧАНИЕМ* Используется для примечаний с несколькими абзацами. ==== |
| ||
.Необязательное заглавие [quote, cite author, cite source] ____ Блок с *цитатой* Используется для цитирования кого-либо ____ |
Необязательное заглавие
— cite author
cite source | ||
//// Блок с *комментарием* Используется для комментирования //// | |||
++++ *Сквозной* блок <p> Используется напрямую для разметки <table border="1"> <tr><td>1</td><td>2</td></tr> </table> ++++ |
*Сквозной* блок
Используется напрямую для разметки
| ||
.Необязательное заглавие .... *Буквальный* блок Используется как трюк, когда необходимо вывести абзацы буквально один в один (с отступами), например 1. Первый. 2. Второй. но для такого случая некоректно работает список. .... |
Необязательное заглавие
*Буквальный* блок Используется как трюк, когда необходимо вывести абзацы буквально один в один (с отступами), например 1. Первый. 2. Второй. но для такого случая некоректно работает список. |
9.3.4. Текст
принудительный + перенос строки |
принудительный |
normal, 'italic', _italic_, *bold*. +mono *bold*+, `mono pass thru *bold*` ''double quoted'', 'single quoted'. normal, ^super^, ~sub~. |
normal, 'italic', italic, bold. mono *bold*, ''double quoted'', 'single quoted'. normal, super, sub. |
Символы: n__i__**b**++m++n |
Символы: nibmn |
// Комментарий | |
(C) (R) (TM) -- ... -> <- => <= ¶ |
© ® ™ — … → ← ⇒ ⇐ ¶ |
'''' |
|
Escape-символов: \_italic_, +++_italic_+++, t\__e__st, +++t__e__st+++, \¶ |
Escape-символов: _italic_, _italic_, t__e__st, t__e__st, ¶ |
9.3.5. Макросы: ссылки, изображения
[[anchor-1]] Абзац или блок 1. <<anchor-1>>, <<anchor-1,Первый якорь>>, xref:anchor-1[], xref:anchor-1[Первый якорь]. |
Абзац или блок 1. |
link:../common/intro.adoc[Родительский документ для этого документа] link:../common/intro.adoc[] | |
http://google.com http://google.com[Google Search] mailto:root@localhost[email admin] | |
Первый home image:home.png[] , Второй home image:home.png[Aльтернативный текст] . .Блок с изображением image::home.png[] image::home.png[Aльтернативный текст] .Миниатюра связана с полным изображением image:highlighter.png[ "Highlighter for Vim",width=128, link="highlighter.png"] |
Первый home

Блок с изображением
Миниатюра связана с полным изображением
|

9.3.6. Списки
.Маркированный * маркер * маркер - маркер - маркер * маркер ** маркер ** маркер *** маркер *** маркер **** маркер **** маркер ***** маркер ***** маркер **** маркер *** маркер ** маркер * маркер |
Маркированный
| ||||||||
.Маркированный 2
- маркер
* маркер
** маркер
*** маркер
|
Маркированный 2
| ||||||||
.Упорядоченный . Арабские числа (1, 2, 3, 4,...) . Арабские числа (1, 2, 3, 4,...) .. Строчные латинские буквы (a, b, c, d,...) .. Строчные латинские буквы (a, b, c, d,...) . Арабские числа (1, 2, 3, 4,...) .. Строчные латинские буквы (a, b, c, d,...) .. Строчные латинские буквы (a, b, c, d,...) ... Римские числа в нижнем регистре (i, ii, iii, iv, v,...) ... Римские числа в нижнем регистре (i, ii, iii, iv, v,...) .... Заглавные латинские буквы (A, B, C, D,...) .... Заглавные латинские буквы (A, B, C, D,...) ..... Римские числа в верхнем регистре (I, II, III, IV, V,...) ..... Римские числа в верхнем регистре (I, II, III, IV, V,...) .... Заглавные латинские буквы (A, B, C, D,...) ... Римские числа в нижнем регистре (i, ii, iii, iv, v,...) .. Строчные латинские буквы (a, b, c, d,...) . Арабские числа (1, 2, 3, 4,...) |
Упорядоченный
| ||||||||
.Упорядоченный 2
a. Строчные латинские буквы (a, b, c, d,...)
b. Строчные латинские буквы (a, b, c, d,...)
.. Строчные латинские буквы (a, b, c, d,...)
.. Строчные латинские буквы (a, b, c, d,...)
. Арабские числа (1, 2, 3, 4,...)
. Арабские числа (1, 2, 3, 4,...)
1. Арабские числа (1, 2, 3, 4,...)
2. Арабские числа (1, 2, 3, 4,...)
3. Арабские числа (1, 2, 3, 4,...)
4. Арабские числа (1, 2, 3, 4,...)
. Арабские числа (1, 2, 3, 4,...)
.. Строчные латинские буквы (a, b, c, d,...)
c. Строчные латинские буквы (a, b, c, d,...)
|
Упорядоченный 2
| ||||||||
.С надписью
Термин 1::
Определение 1
Термин 2::
Определение 2
Термин 2.1;;
Определение 2.1
Термин 2.2;;
Определение 2.2
Термин 3::
Определение 3
Термин 4:: Определение 4
Термин 4.1::: Определение 4.1
Термин 4.2::: Определение 4.2
Термин 4.2.1:::: Определение 4.2.1
Термин 4.2.2:::: Определение 4.2.2
Термин 4.3::: Определение 4.3
Термин 5:: Определение 5
|
С надписью
| ||||||||
.С надписью 2
Термин 1;;
Определение 1
Термин 1.1::
Определение 1.1
|
С надписью 2
| ||||||||
[horizontal]
.С надписью, горизонтальные
Термин 1:: Определение 1
Термин 2:: Определение 2
Термин 3::
Определение 3
Термин 4:: Определение 4
|
С надписью, горизонтальные
| ||||||||
[qanda]
.Q&A
Вопрос 1::
Ответ 1
Вопрос 2:: Ответ 2
|
Q&A
| ||||||||
.Разрыв между двумя списками . номер . номер Независимый абзаца заканчивает список . номер .Заголовок так же заканчивает предыдущий список . номер -- . Блок *списка* определяет границы списка . номер . номер -- . номер . номер |
Разрыв между двумя списками
Независимый абзаца заканчивает список
Заголовок так же заканчивает предыдущий список
| ||||||||
.Продолжение списка - продолжение маркера . продолжение нумерованого маркера * маркер продолжение буквальныго блока .. буквенный маркер + продолжение не буквальныго блока + ---- любой блок может быть включен в лист ---- + дальнейшее продолжение. |
Продолжение списка
| ||||||||
.Блок список позволяет включать подсписки
- маркер
* маркер
+
--
- маркер
* маркер
--
* маркер
- маркер
. пронумерованный маркер
.. алфавитный маркер
+
--
. пронумерованный маркер
.. алфавитный маркер
--
.. алфавитный маркер
. пронумерованный маркер
|
Блок список позволяет включать подсписки
|
9.3.7. Таблицы
.Пример таблицы [options="header,footer"] |=================================== |Столбец 1|Столбец 2 |Столбец 3 |1 |Содержимое 1 |a |2 |Содержимое 2 |b |3 |Содержимое 3 |c |6 |Три позиции |d |=================================== |
| |||||||||||||||
.CSV данные [format="csv",cols="4"] |====== 1,2,3,4 a,b,c,d A,B,C,D |====== |
| |||||||||||||||
[format="csv"] [options="header",cols="^,<,<s,<,>m"] |======================================== ID,Имя,Фамилия,Адресс,Телефон 1,Ivan,Ivanov,Minsk,+375*** 2,Petr,Petrov,"Minsk,Main street",+375*** |======================================== |
| |||||||||||||||
.Многострочные ячейки, объединение строк/столбцов |==== |Дата |Продолжительность |Средний пульс |Примечание |22-Aug-08 .2+^.^|10:24 |157 | Достигли максимального пульса при сильной физической нагрузке |22-Aug-08 | 152 | Один в один как и в предыдущем |24-Aug-08 3+^|нет |==== |
| |||||||||||||||