Wiki of themes for Application Architecture.
1. Консольное приложение
Консольное приложение - это компьютерное приложение без графического интерфейса пользователя (GUI), предназначенное для работы исключительно с командами клавиатуры через текстовый компьютерный интерфейс. Многие ранние операционные системы работали исключительно в таких режимах, и только позже компании начали разрабатывать операционные системы с графическим интерфейсом для простоты использования. Можно запустить консольное приложение без графического интерфейса или запустить операционную систему в режиме консоли по диагностическим и другим причинам.
В консольном приложении пользователь выдает команды через клавиатуру, в отличие от приложений с графическим интерфейсом пользователя, которые обычно требуют использования мыши или другого указывающее устройство. Можно запустить приложение, чтобы участвовать в различных действиях, и результат будет отображаться на консоли. Программа способна извлекать и редактировать файлы, печатать, передавать данные, массово удалять и выполнять другие функции. Многие приложения, работающие в фоновом режиме в операционной системе, работают в режиме консоли, поскольку пользователю не нужно взаимодействовать с ними, за исключением редких случаев.
Текстовый интерфейс пользователя (англ. Text user interface, TUI; также Character User Interface, CUI) — система средств взаимодействия пользователя с компьютером, основанная на использовании текстового (буквенно-цифрового) режима дисплея или аналогичных устройств — например, командная строка. Приложения, использующие текстовый интерфейс, называют консольными программами.
В простейшем случае консольная программа использует интерфейс командной строки, однако многие из таких программ с помощью управляющих последовательностей терминалов создают более дружественный интерфейс, приближающийся к графическому.
В Windows командная строка является примером консольного приложения. Пользователь может открыть командную строку для редактирования системных файлов и для других целей. Когда он вводит команды, они прокручивают экран вверх вместе с ответами из приложения.
-
терминал Linux
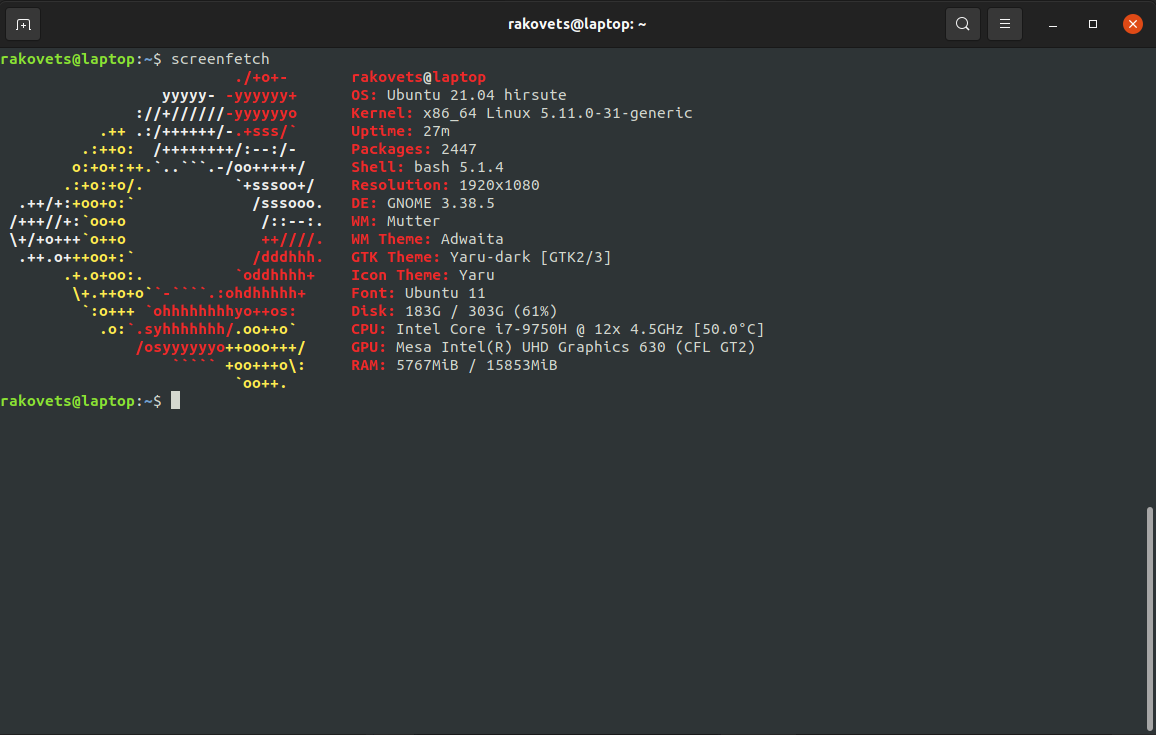
-
командная строка Windows
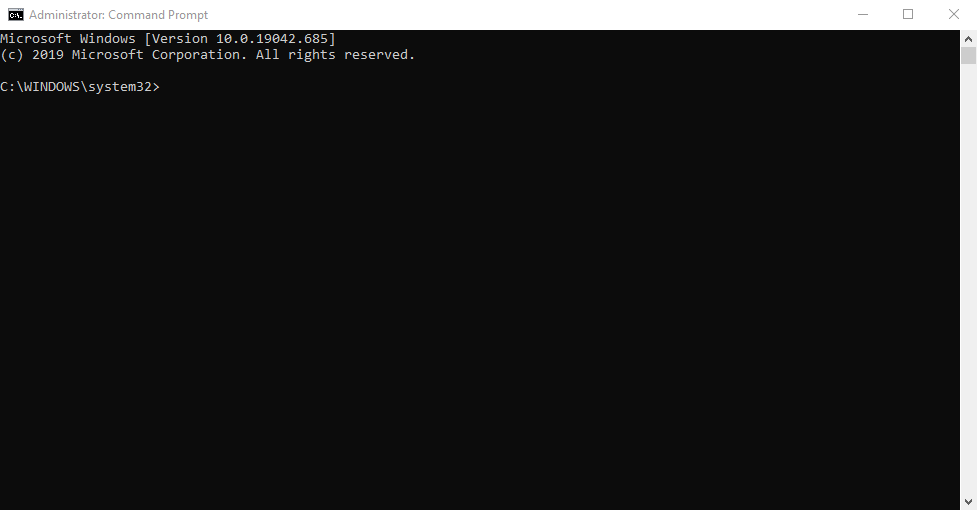
-
терминал macOS
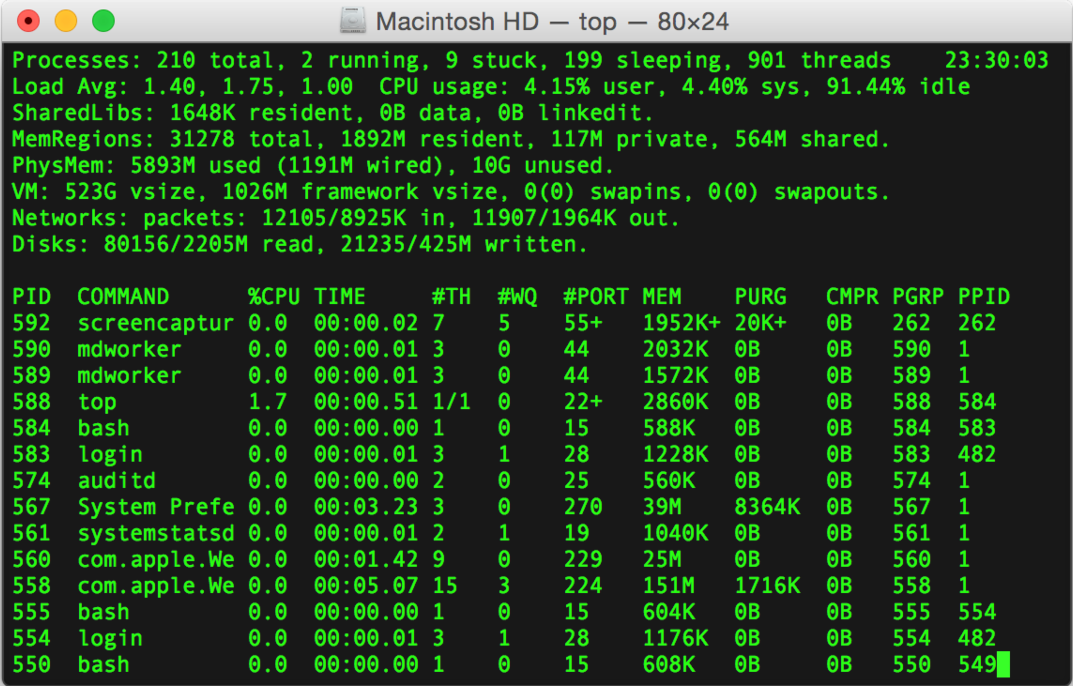
Преимущества консольных приложений:
-
Более скромные требования к ресурсам по сравнению с другими видами интерфейсов.
-
При большом наборе возможных команд опытные пользователи могут работать с приложением быстрее, чем с системой меню
-
Основным преимуществом является то, что консольные приложения дают возможность использовать себя в скриптах для автоматизации (рутинных) действий.
1.1. Стандартные потоки
Говоря про консольные приложения стоит знать о стандартных потоках ввода/вывода данных.
Стандартные потоки ввода/вывода в системах типа UNIX (и некоторых других) — потоки процесса, имеющие номер (дескриптор), зарезервированный для выполнения некоторых «стандартных» функций. Как правило(хотя и не обязательно), эти дескрипторы открыты уже в момент запуска задачи (исполняемого файла).
Существует три стандартных потока ввода/вывода данных:
-
стандартный поток ввода standard input (stdin);
-
стандартный поток вывода standard output (stdout);
-
стандартный поток ошибок standard error (stderr).
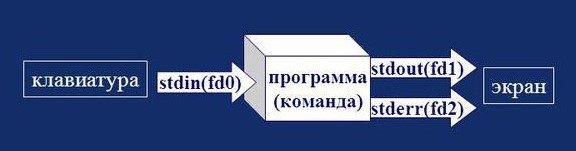
Вывод данных на экран и чтение их с клавиатуры происходит потому, что по умолчанию стандартные потоки ассоциированы с терминалом пользователя. Это не является обязательным — потоки можно подключать к чему угодно — к файлам, программам и даже устройствам.
1.1.1. Стандартный ввод
Поток №0 (stdin) зарезервирован для чтения команд пользователя или входных данных. Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности — инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
1.1.2. Стандартный вывод
Поток №1 данных (stdout), которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
1.1.3. Стандартный вывод ошибок
Поток ошибок (stderr) имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
1.2. Конвейер
Конвейер - некоторое множество процессов, для которых выполнено следующее перенаправление ввода-вывода: то, что выводит на поток стандартного вывода предыдущий процесс, попадает в поток стандартного ввода следующего процесса.
Другими словами, конвейер умеет передавать выходные данные из одной программы, как входные данные для другой. Т.е. выполняется команда, мы получаем результат и передаем эти данные далее на обработку другой программе.
-
|- отправить следующей команде -
Tee- отправить в файл и на стандартный вывод -
Xargs– построчно передать на ввод команде
Конвейер создаётся с помощью вызова pipe(), который возвращает два файловых дескриптора: один ссылается на вход конвейера, второй на выход и разделяются | (stdout/stderr | stdin).
$ ls | grep r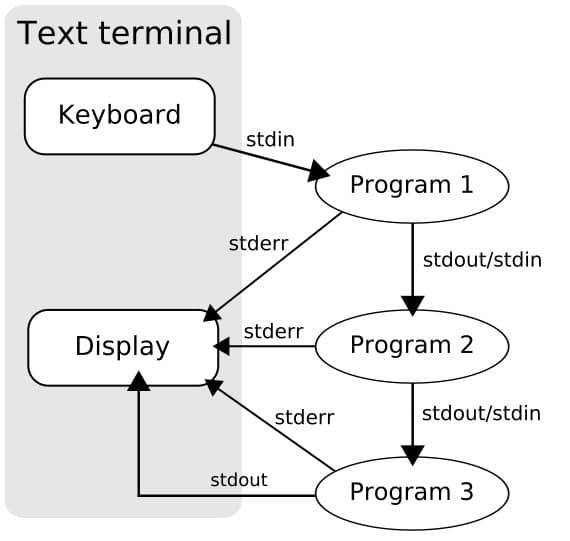
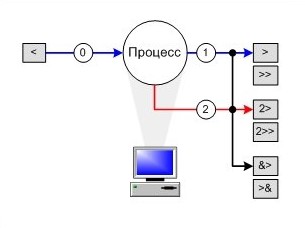
1.3. Перенаправление потоков
Перенаправление ввода/вывода - изменения стандартных входных или выходных потоков и привязка к определенным условиям или файлам.
Перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и < в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
-
<- изменение (назначение) нестандартного входного устройства (< файл- файл в поток ввода); -
<<- считывать стандартный ввод, пока не встретится указанный текст; -
>- переназначение стандартного вывода (> файл- поток вывода в новый файл); -
>>- переназначение вывода, добавление вывода команды в конец существующего файла (>> файл- поток вывода в конец файла); -
2>- переназначения стандартного потока сообщений об ошибках (2> файл- поток ошибок в новый файл); -
2>>- переназначение вывода сообщений об ошибках, добавление сообщений об ошибках в конец существующего файла (2>> файл- поток ошибок в конец файла); -
&>,>&- направляет потоки вывода и ошибок в один файл (&> файлили>& файл- потоки вывода и ошибок в новый файл); -
2>&1- направляет поток ошибок туда, куда направлен поток вывода (2>&1 файл- потоки ошибок туда, куда и поток вывода); -
1>&2- направляет поток вывода туда, куда направлен поток ошибок (1>&2 файл- поток вывода туда, куда и поток ошибок).
1.3.1. Перенаправление стандартного потока вывода
Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел. При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды.
$ date > date.txtДля того, чтобы это данные добавлялись в конец файла, а не перезаписывали файл, надо использовать два символа >>, поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
$ traceroute google.com >> date.txt1.3.2. Перенаправление стандартного потока ввода
Используя знак < мы можем перенаправить стандартный ввод, заменив его содержимым файла.
$ comm <(sort list1.txt) <(sort list2.txt)Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm, которая затем выводит результат сравнения списков.
1.3.3. Перенаправление стандартного потока ошибок
Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Обычно, когда обычный пользователь запускает команду, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2>. В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
$ find / -name wireless 2> denied.txtЕсли нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках можно добавить команду перенаправления стандартного потока вывода в файл:
$ find / -name wireless 2> denied.txt > found.txtЕсли нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &>:
$ find / -name wireless &> results.txt1.4. Формат и параметры команд
Наиболее общий формат команд (в квадратные скобки помещены необязательные части):
[символ_начала_команды]имя_команды [параметр_1 [параметр_2 […]]]Символ начала команды может быть самым разным, однако чаще всего для этой цели используется косая черта /. Если строка вводится без этого символа, выполняется некоторая базовая команда. Если же такой базовой команды нет, символ начала команды отсутствует вообще (как, например, в DOS).
Параметры команд могут иметь самый разный формат. В основном применяются следующие правила:
-
параметры разделяются пробелами (и отделяются от названия команды пробелом)
-
параметры, содержащие пробелы, обрамляются кавычками-апострофами
'или двойными кавычками" -
если параметр используется для обозначения включения какой-либо опции, выключенной по умолчанию, он начинается с косой черты
/или дефиса- -
если параметр используется для включения/выключения какой-либо опции, он начинается (или заканчивается) знаком плюс или минус (для включения и выключения соответственно)
-
если параметр указывает действие из группы действий, назначенных команде, он не начинается со специальных символов
-
если параметр указывает объект, к которому применяется действие команды, он не начинается со специальных символов
-
если параметр указывает дополнительный параметр какой-либо опции, то он имеет формат
/опция:дополнительный_параметр(вместо косой черты также может употребляться дефис).
/map dm1 /skill:2-
/— символ начала команды -
map— название команды (переход на другой уровень) -
dm1— обязательный параметр (название уровня) -
/skill:2— дополнительный параметр (задание уровня сложности)
1.5. Примеры консольных программ
-
Любая программа, осуществляющая получение данных от пользователя путём чтения stdin и отправку данных пользователю путём записи в stdout, по определению является консольной программой. Однако, такие программы могут обходиться и безо всякого пользователя, например обрабатывая данные из файлов.
-
Unix shell, а также все утилиты, предназначенные для работы в этой среде.
-
Midnight Commander (UNIX), FAR Manager (Windows) - это двухпанельный файловый менеджер для операционных систем.
-
Alpine (клиент электронной почты)
-
Irssi (IRC-клиент (Internet Relay Chat))
-
Lynx (веб-браузер)
-
Music on Console (аудиоплеер)
-
Mutt (клиент электронной почты)
-
VIM (текстовый редактор)
-
RTORRENT (ТОРРЕНТ КЛИЕНТ)
-
newsbeuter (RSS-ридер)
2. Client-Server Architecture
|
Warning
|
Термины и названия, которые используются в разработке программного обеспечения, для одних и тех же вещей и идей, могут отличаться друг от друга в зависимости от авторов и различных глоссариев принятых в командах и компаниях. К сожалению, согласованность в этом отсутствует и необходимо это учитывать при коммуникации с другими. Да бы не вносить еще большую несогласованность, рекомендуется использовать только термины и названия на английском языке, так как в процессе локализации может теряться смысл или очевидность, того или иного термина и названия. Что еще хуже, может появиться новый термин или название для конкретной локализации. |
2.1. Что такое Client-Server Architecture?
Client-server model или client-server architecture, представляет собой структуру распределенного приложения, разделяющую задачи между серверами и клиентами, которые либо находятся в одной системе, либо обмениваются данными через компьютерную сеть или Интернет. Клиент полагается на отправку запроса в другую программу, чтобы получить доступ к услуге, предоставляемой сервером. На сервере выполняется одна или несколько программ, которые совместно используют ресурсы и распределяют работу между клиентами.
Клиент и сервер физически представляют собой программы, например, клиентом может являться браузер, а сервером: Web server или Relational Database Management System.
Отношения client-server взаимодействуют согласно request–response messaging pattern и должны иметь общий протокол связи, который формально определяет используемые правила, язык и шаблоны requests и response. Связь между клиентом и сервером обычно осуществляется по набору протоколов TCP/IP.
В основе взаимодействия клиент-сервер лежит принцип того, что такое взаимодействие начинает клиент, сервер лишь отвечает клиенту и сообщает о том, может ли он предоставить услугу и, если может, то на каких условиях.
Клиентское и серверное программное обеспечение обычно установлено на разных машинах, но также они могут работать и на одном компьютере. Данная концепция взаимодействия была разработана для того, чтобы разделить нагрузку между участниками процесса обмена информацией, а также для того, чтобы разделить программный код поставщика и заказчика.
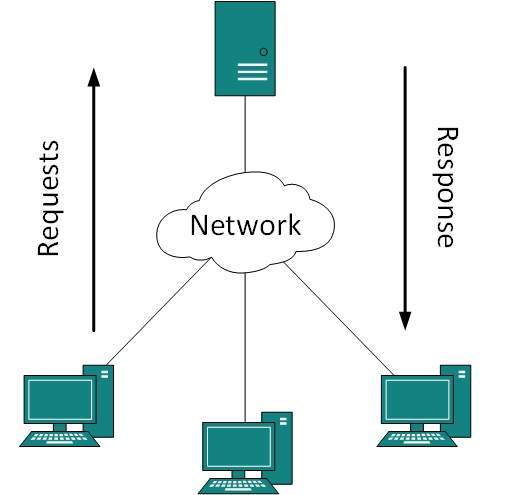
Видно, что к одному серверу может обращаться сразу несколько клиентов (на одном сайте может находиться несколько посетителей). Также стоит заметить, что количество одновременно взаимодействующих клиентов с сервером зависит от мощности сервера и от того, что хочет получить клиент от сервера.
2.1.1. Преимущества
-
Отсутствие дублирования кода программы-сервера программами-клиентами. Это позволяет обновлять систему, без обязательной необходимости обновлять программу-клиент, так как основная логика выполнения находится на стороне программы-сервера.
-
Снижаются требования к компьютерам на которые установлен клиент, так как все вычисления выполняются на сервере.
-
Безопасность, так как все данные хранятся на сервере, который, как правило, защищён гораздо лучше большинства клиентов. На сервере проще организовать контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа.
2.1.2. Недостатки
-
Неработоспособность сервера может сделать неработоспособной всю вычислительную систему. Неработоспособным сервером следует считать сервер, производительности которого, не хватает на обслуживание всех клиентов. Неработоспособным сервером следует так же считать сервер, который физически не обслуживает клиентов, т.к находящийся на ремонте, профилактике и т.д.
-
Поддержка работы данной системы требует отдельного специалиста — системного администратора.
-
Высокая стоимость оборудования, т.к. к серверу предъявляются более высокие требования к отказоустойчивости, чем к клиентам.
2.2. Тонкий и толстый клиент
Все клиенты в клиент-серверной архитектуре условно делятся на два подтипа: толстые клиенты и тонкие клиенты.
Толстый клиент — клиент, выполняющий запрашиваемые со стороны пользователя манипуляции независимо от ведущего сервера. Основной сервер в такой вариации системной архитектуры может применяться как особое хранилище информации, обработка и конечное предоставление которых просто переносится на локальную машину пользователя.
Толстый клиент – это рабочая машина или ПК, которые функционируют на основе своей ОС и наполнены полноценным набором ПО для требуемых задач пользователя. Если взглянуть с программной точки зрения, понятными примерами толстых клиентов можно считать программы для совместной деятельности, если они изначально установлены на определенные вычислительные устройства. Например: Yahoo Messenger, Office 365, Microsoft Outlook.
Преимущества толстых клиентов:
-
Большая функциональность;
-
Наличие многопользовательского режима;
-
Возможность работы в режиме оффлайн;
-
Мгновенное быстродействие;
-
Минимальная зависимость от сложных серверов.
Недостатки толстых клиентов:
-
Все рабочие машины на постоянной основе нуждаются в техническом обслуживании;
-
Необходимость в индивидуальном обновлении аппаратного ПО каждого клиента до уровня программного обеспечения, которое будет использоваться;
-
Массивные объемы дистрибутивов;
-
Полная зависимость от платформ, под которую данные клиенты были созданы.
Тонкий клиент — вид клиента, который может переносить выполнение задач по обработке информации на сервер, не применяя свои мощности по вычислению для их внедрения. Все вычислительные ресурсы подобного клиента максимально ограничены, важно, чтобы их хватало для старта нужного сетевого ПО, применяя, к примеру, веб-интерфейс.
Одним из наиболее распространенных примеров такого типа клиента считается ПК с заранее установленным веб-браузером, который применяется для работы с web-сервисами.
Характерная черта тонких клиентов — применение терминального режима функционирования. В такой ситуации, терминальный сервер применяется для процесса отправки и получения информации пользователя, что и является базовым отличием от процесса независимой обработки информации в толстых клиентах.
Плюсы тонкого клиента:
-
Минимальное аппаратное обслуживание;
-
Низкий риск возникновения неисправности;
-
Минимальные технические требования к аппаратному оборудованию.
Недостатки тонкого клиента:
-
При сбое на сервере «пострадают» все подключенные пользователи;
-
Нет возможности работать без активного подключения к сети;
-
При взаимодействии с большим массивом данных может снижаться объем производительности основного сервера.
Базовые отличия между ними – это варианты обработки данных. Толстые клиенты работают с информацией на основе собственных аппаратных и программных возможностей, в то же время тонкие применяют ПО центрального сервера, только чтобы обработать данные, предоставляя системе лишь требуемый графический интерфейс для выполнения работы пользователем. Это значит, что в роли тонких клиентов иногда мы можем увидеть устаревшие или не очень производительные ПК.
3. N-tier Architecture
N-tier architecture (multitier architecture, многослойная архитектура) это client-server architecture, в которой разделяются функции представления, обработки и хранения данных. Наиболее распространённой разновидностью многоуровневой архитектуры является трёхуровневая архитектура.
3.1. Tiers
Стоит выделить несколько tiers на которые обычно разделяют систему.
3.1.1. Presentation tier
Presentation tier (слой представления) - это user interface (пользовательский интерфейс) и communication layer (уровень связи приложения), где конечный пользователь взаимодействует с приложением. Его основная цель - отображать информацию и собирать информацию от пользователя. Этот top-level tier (верхне-уровневый слой) может работать, например, в веб-браузере, как настольное приложение или как graphical user interface (графический пользовательский интерфейс, GUI). Web presentation tiers обычно разрабатываются с использованием HTML, CSS и JavaScript. Настольные приложения могут быть написаны на разных языках в зависимости от платформы.
3.1.2. Application tier
Application tier (слой приложения), также известный как logic tier (слой логики) или middle tier (средний слой), является сердцем приложения. На этом уровне информация, собранная на presentation tier, обрабатывается, и обычно с использованием некой бизнес-логики и определенного набора бизнес-правил. Application tier также может добавлять, удалять или изменять данные на data tier.
Application tier обычно разрабатывается с использованием Java, Python, Perl, PHP или Ruby и взаимодействует с data tier с помощью вызовов некоторого API.
3.1.3. Data tier
Data tier (слой данных), иногда называемый database tier (слоем базы данных), data access tier (слоем доступа к данным) или back-end (серверной частью), - это место, где информация, обрабатываемая приложением, хранится и управляется. Это может быть relational database management system (система управления реляционными базами данных), такая как PostgreSQL, MariaDB, Oracle, DB2, Informix или Microsoft SQL Server, или NoSQL Database server (сервером NoSQL базы данных), таким как Cassandra, CouchDB или MongoDB.
3.2. Layer против tier
При обсуждении N-tier architecture, layer (уровень) часто используется взаимозаменяемо с tier (слой), что является не совсем верно, например, presentation layer или business logic layer.
Это не одно и то же. Layer относится к функциональному разделению программного обеспечения, а tier относится к функциональному разделению программного обеспечения, которое выполняется на разных инфраструктурных единицах, независимо от других. Приложение Контакты на телефоне, например, представляет собой three-layer application, но single-tier application, потому что все три layers работают на телефоне.
Разница важна, потому что layers не могут предложить те же преимущества, что и tiers.
3.3. Single-tier architecture
Single-tier application AKA Standalone application
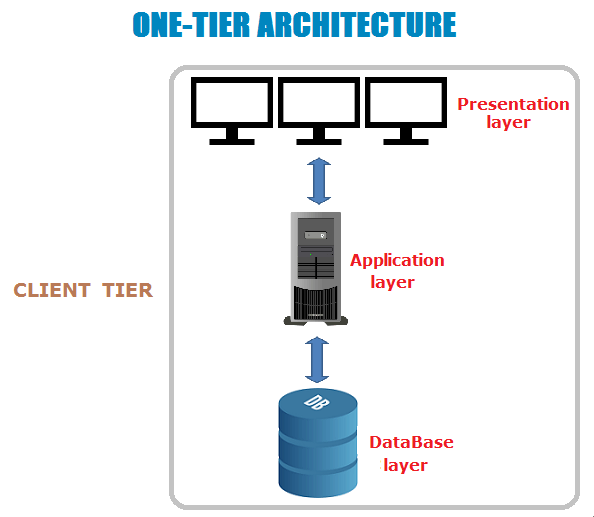
Single-tier architecture включает в себя все tiers, такие как presentation tier, application tier и data tier, в одном приложении. Приложения, которые включают в себя все три tiers, например, MP3-плеер, MS Office и т.д., являются single-tier application. Данные хранятся в локальной системе или на общем диске.
3.4. Two-tier architecture
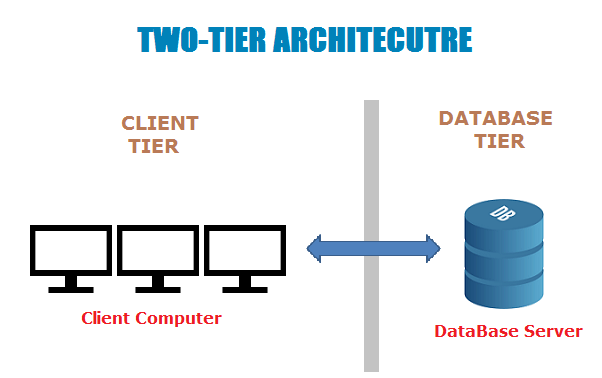
Two-tier architecture (двухзвенная архитектура, двухуровневая архитектура) - это классическая (т.е. первоначальная) client-server architecture, состоящая из presentation tier и data tier; бизнес-логика находится на presentation tier, data tier или на обоих tiers. В two-tier architecture presentation tier, а следовательно, конечный пользователь - имеет прямой доступ к data tier, а бизнес-логика часто ограничена. Простое приложение для управления бухгалтерией, в котором бухгалтеры могут фиксировать денежные операции в компании, является примером two-tier application.
3.4.1. Преимущества
-
С точки зрения разработки и обслуживания:
-
Простая структура
-
Простота установки
-
Простота обслуживания
-
-
С точки зрения производительности:
-
Хорошая производительность для небольших и средних объемов данных
-
Бизнес-логика и база данных физически близко, что обеспечивает более высокую производительность.
-
3.4.2. Недостатки
-
С точки зрения разработки и обслуживания:
-
Сложную бизнес-логику приложения трудно реализовать на сервере базы данных, поэтому требуется реализовывать на клиенте
-
Сложная бизнес-логика приложения на клиенте, ведет к снижению производительности
-
Изменения в бизнес-логике, если они на клиенте, требуют нового программного обеспечения на стороне клиента, соответственно они должны быть доступны и установленны
-
Привязка к поставщику СУБД
-
-
С точки зрения производительности:
-
Плохая производительность для больших и огромных объемов данных, так как сервер базы данных выполняет еще и бизнес-логику. Это замедляет операции в БД на сервере базы данных.
-
3.5. Three-tier architecture
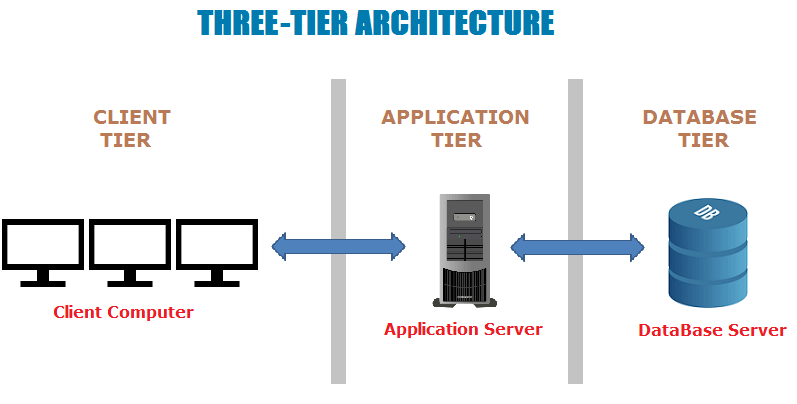
Three-tier architecture (трехзвенная архитектура, трехуровневая архитектура) - это хорошо зарекомендовавшая себя архитектура программных приложений, которая объединяет приложения в три логических и физических вычислительных tiers:
-
presentation tier или пользовательский интерфейс;
-
application tier, на котором обрабатываются данные;
-
data tier, где хранятся и управляются данные, связанные с приложением.
На протяжении десятилетий three-tier architecture была преобладающей client-server architecture для приложений.
3.5.1. Преимущества
-
Главное преимущество three-tier architecture - логическое и физическое разделение функций. Каждый tier может работать на отдельной операционной системе и на отдельной серверной платформе - например, на веб-сервере, сервере приложений, сервере базы данных - что наилучшим образом соответствует его функциональным требованиям. И каждый уровень работает по крайней мере на одном выделенном серверном оборудовании или виртуальном сервере, поэтому службы каждого уровня могут быть настроены и оптимизированы без влияния на другие уровни.
Другие преимущества (по сравнению с single-tier или two-tier architecture):
-
Более быстрая разработка: поскольку каждый tier может разрабатываться одновременно разными командами, организация может быстрее вывести приложение на рынок, а программисты могут использовать подходящие и более новые версии языков и инструментов для каждого tier.
-
Улучшенная масштабируемость: любой tier можно масштабировать независимо от других по мере необходимости.
-
Повышенная надежность: сбой на одном tier с меньшей вероятностью повлияет на доступность или производительность других tiers.
-
Повышенная безопасность: поскольку presentation tier и data tier не могут взаимодействовать напрямую, хорошо спроектированный application tier может функционировать как своего рода внутренний брандмауэр, предотвращая SQL-инъекции и другие вредоносные эксплойты.
Так же можно структурировать преимущества.
-
С точки зрения разработки и обслуживания:
-
Сложную бизнес-логику приложения легко реализовать на сервере приложений
-
Бизнес-логика отсутствует на сервере базы данных и клиенте, что улучшает производительность
-
Изменение бизнес-логики автоматически доступно клиенту после установки на application server
-
Бизнес-логика application server совместима с другими серверами баз данных, после небольших изменений
-
-
С точки зрения производительности:
-
Высокая производительность для средних и больших объемов данных
-
3.5.2. Недостатки
-
С точки зрения разработки и обслуживания:
-
Более сложная структура
-
Более сложная в настройке
-
Более сложная в обслуживании.
-
-
С точки зрения производительности:
-
Физическое разделение на application server, содержащий бизнес-логику и database server, содержащий базы данных, может незначительно повлиять на производительность.
-
3.6. Three-tier application в web-разработке
В web-разработке tiers имеют разные имена, но выполняют схожие функции:
-
Web-server является presentation tier и предоставляет пользовательский интерфейс. Обычно это web-страница или web-сайт, например, сайт электронной коммерции, где пользователь добавляет продукты в корзину, добавляет реквизиты для оплаты или создает учетную запись. Контент может быть статическим или динамическим и обычно разрабатывается с использованием HTML, CSS и Javascript.
-
Application server соответствует middle tier, в котором размещается бизнес-логика, используемая для обработки вводимых пользователем данных. Продолжая пример электронной торговли, это tier, который запрашивает из базы данных продукты, чтобы получить информацию о наличии продукта, или добавляет подробности в профиль клиента. Этот уровень часто разрабатывается с использованием Java, Python, Ruby, JavaScript и PHP, при поддержке таких фреймворков, как, например, Spring, Django, Rails, NodeJS и Symphony соответственно.
-
Database server - это data tier для web-приложения. Он работает с программным обеспечением для управления базами данных, например PostgreSQL, MariaDB, Oracle или DB2.
3.7. N-tier architecture
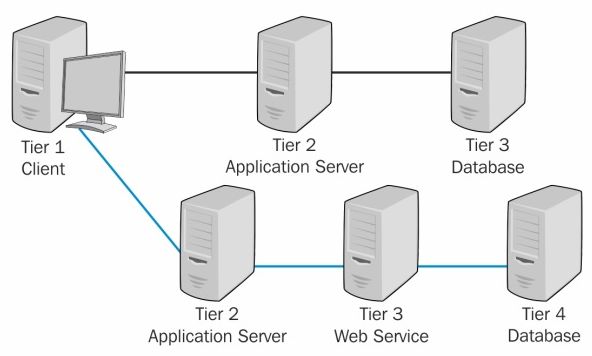
N-tier architecture - также называемая multi-tier architecture - относится к любой архитектуре приложения с более чем одним tiers. Так же встречаются приложения с более чем тремя tiers. Например, где источником данных является другой multi-tier application.
Resources: